If you would like to add specific functionality to your Datrics pipeline, you may use the Datrics Customization service that allows you to wrap the custom Python code into the Datrics brick and use it in the pipeline in a usual way. Like any other Datrics brick, Custom Brick can be configured via arguments settings and used in any pipeline in the project.
To create a Custom Code brick, click on the + button near the Customization section on the left sidebar.
Settings
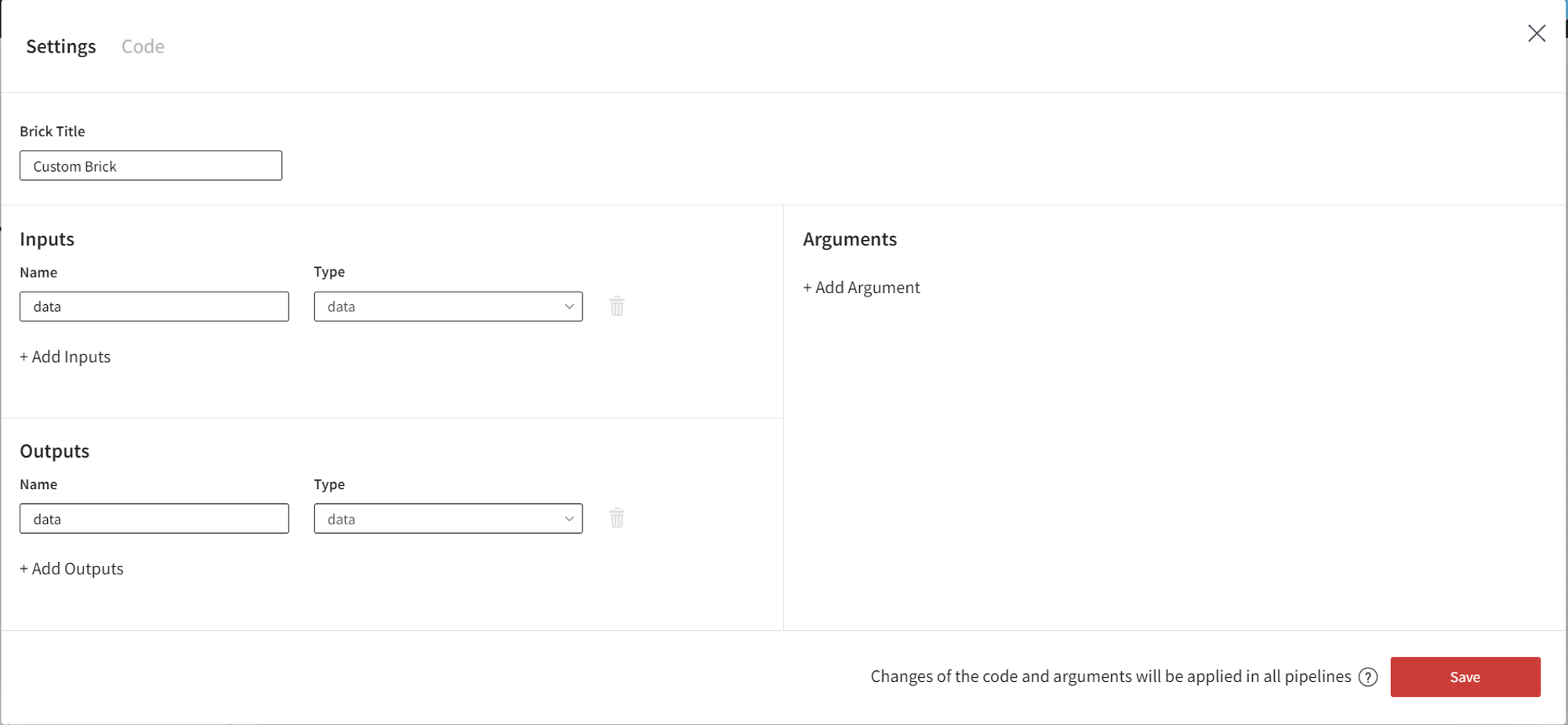
In the Settings tab, you can configure the brick:
Brick Title - the name of the brick, which will be displayed in the left sidebar and pipelines.
Inputs - brick input slots to take the date from other bricks on the pipeline.
Outputs - brick output slots to connect the custom brick with other bricks on the pipeline to pass the resulted DataFrames
Arguments - brick configuration parameters
First, you can change the name of the brick to whatever you want.
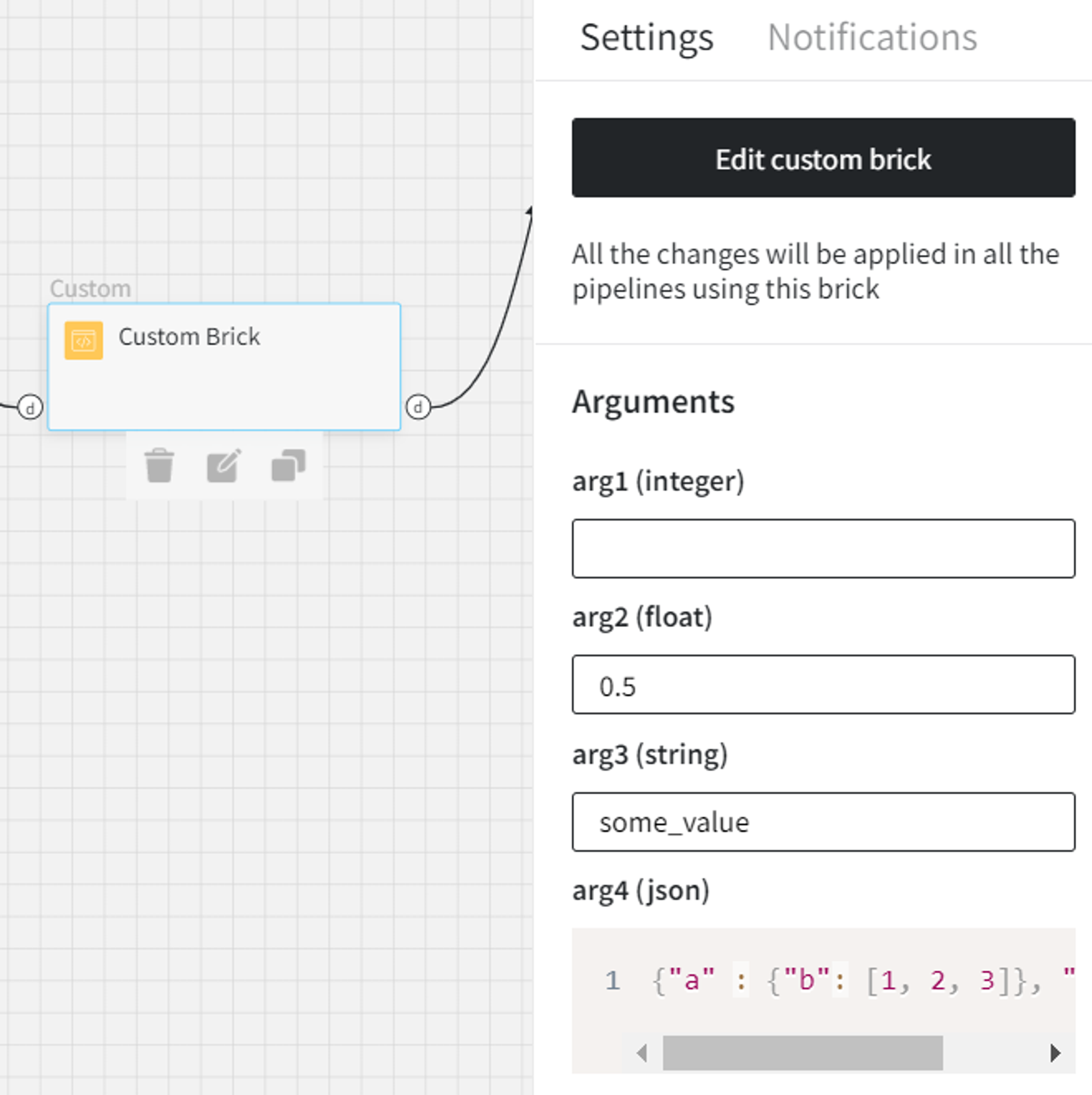
Any brick can have multiple inputs and outputs. You can set up their names and types (currently only the ‘data’ type is supported).
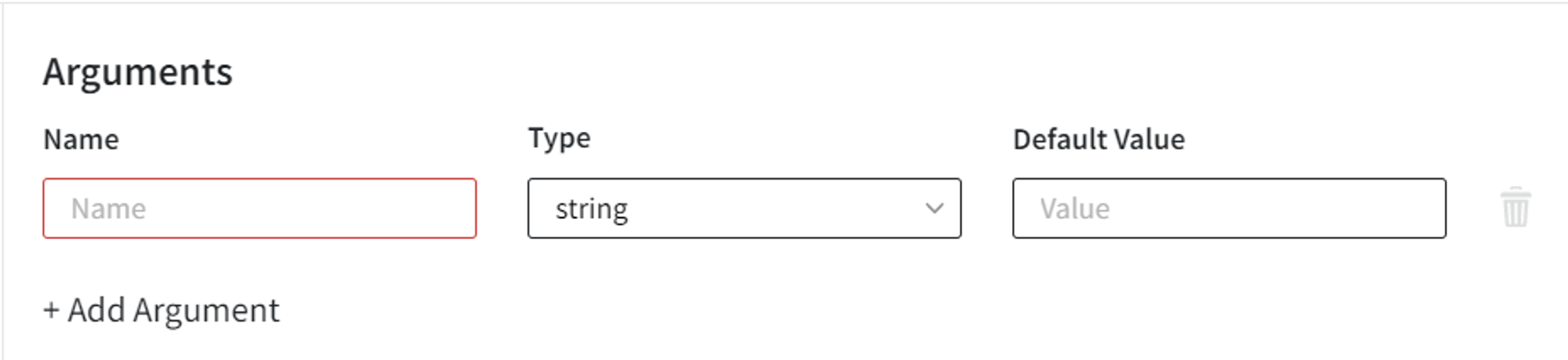
Also, there is a possibility to pass arguments (as many as you like) to the brick if necessary. To add an argument, click on the +Add Argument button and you will see the following fields:
Here, you have to specify
Nameby which you will be able to access the argument value (argument names must be unique)
Type of the argument - integer/float/string/boolean/json.
Default Value - optional. This field can remain empty.
Float type. Period is the valid decimal separator.
Boolean type gives two options to choose from - true/false.
json type - requires the value to be included in curly braces and to be in a proper json format (key-value pairs similarly to Python dictionary). Json type allows you to store multiple different values, Lists of values, or nested json objects.
Generally, json argument is represented as a json string object, so if you need to transform it into a Python dictionary in code for parsing, you may use the json.loads(json_string) function, which returns a corresponding Python object.
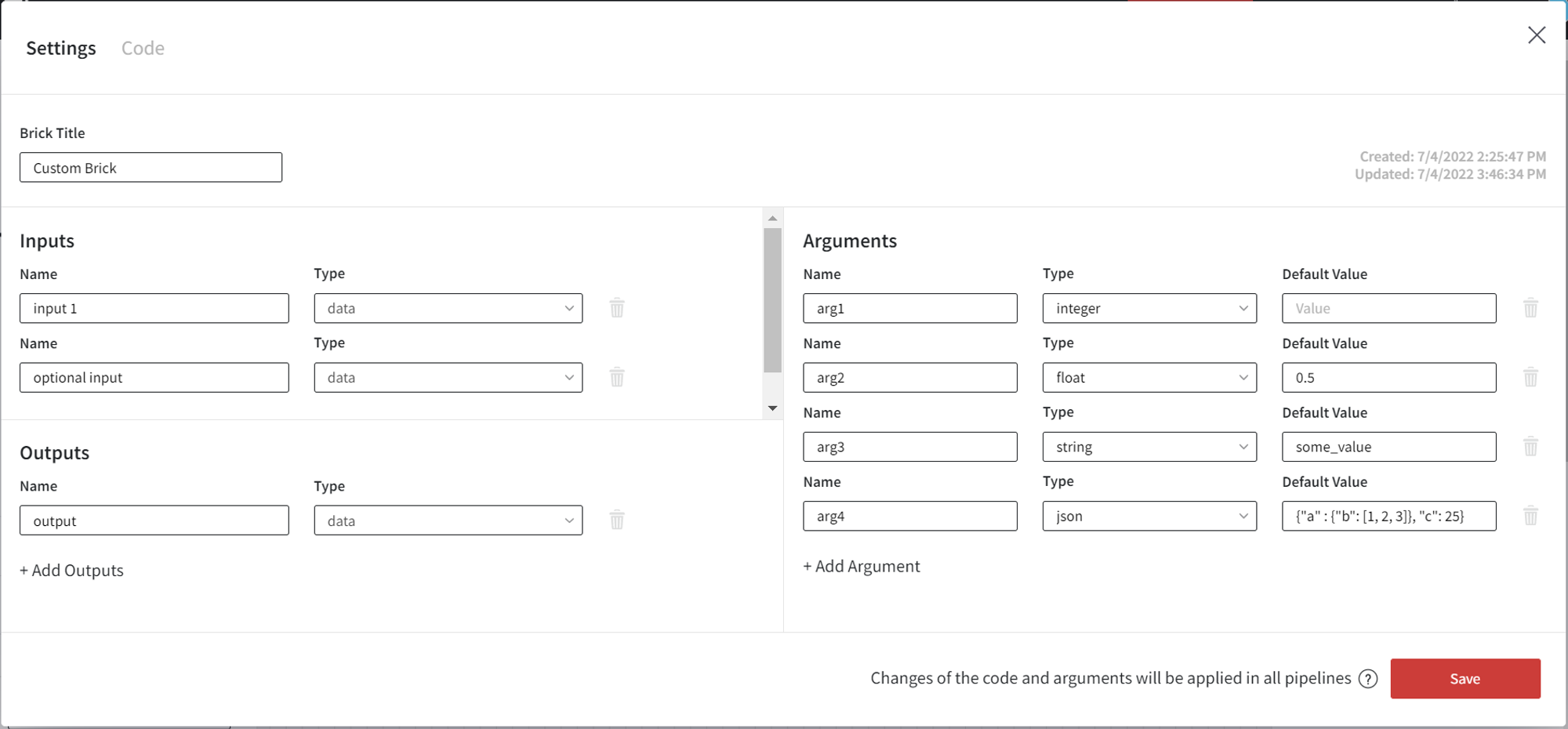
Settings example:
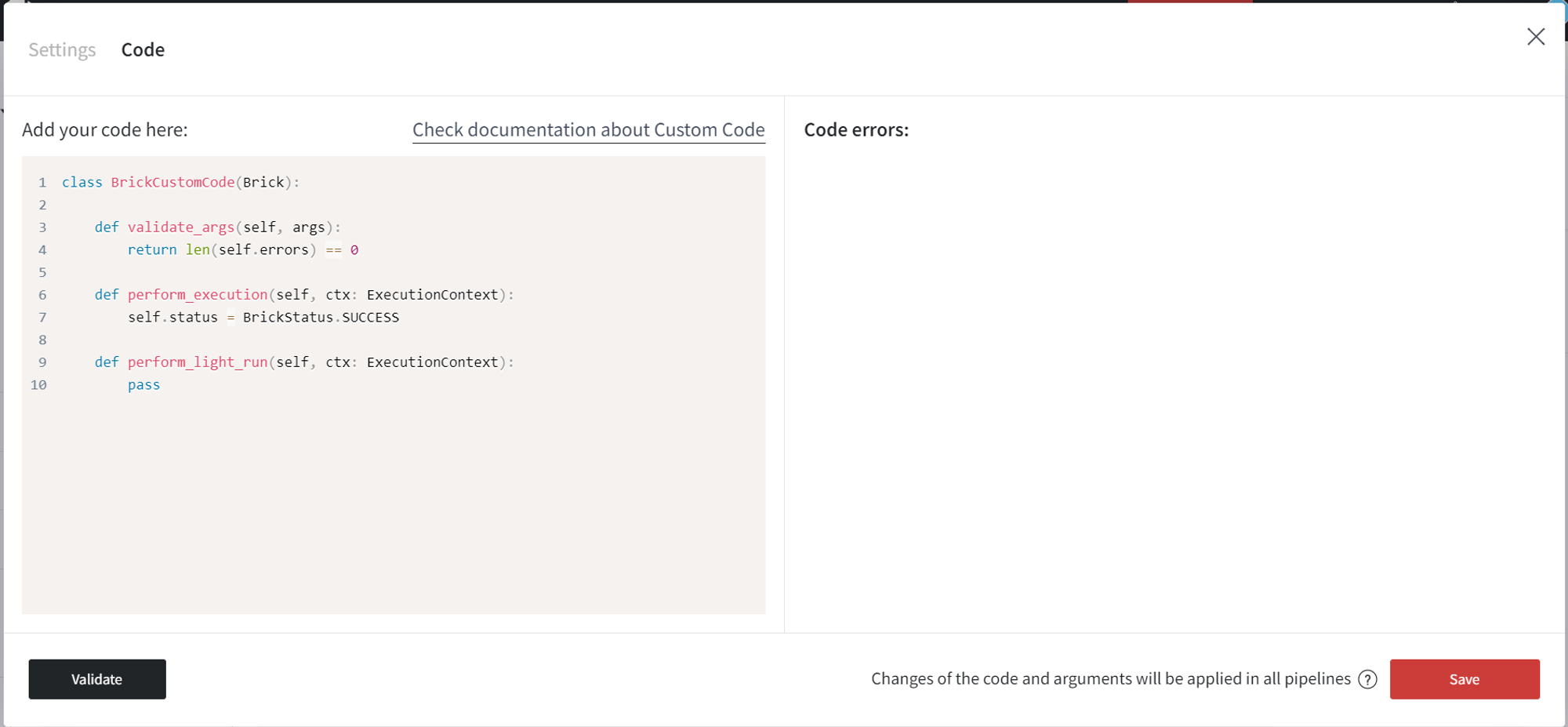
Code
In the Code tab, you can create your own functionality for a brick.
Class for all bricks must have the same name - BrickCustomCode and inherit Brick.
Methods validate_args, perform_execution, and perform_light_run are obligatory to implement.
Outputs of type data must be a pandas DataFrame.
To access the argument value, use the following syntax:
column = self.args.get("Column")
# or
column = self.args["Column"]
Methods
validate_args
This method is implemented to check the correctness of arguments and inputs passed. For instance, you can validate if all the needed arguments are present or if they have certain data types and values. Regarding inputs, for instance, you can check the number of inputs, whether the inputs are empty or not, or anything else you need for the right model execution. To perform such validations you can use theArgument handling functions and Input handling functions.
For example:
class BrickCustomCode(Brick):
def validate_args(self, args):
check_number_of_inputs(self, 2)
check_input_with_index_has_value(self, 0)
if check_argument_not_none(self.args, 'arg2', self.messages):
check_argument_in_boundaries(self.args, 'arg2', 0, 1, self.messages)
check_argument_matches_type(self.args, 'arg3', str, self.messages)
try:
json.loads(self.args['arg4'])
except ValueError:
self.messages.append(Message(
message="'arg4' is not in a valid json format",
context=self.message_context,
mtype=MessageType.WARNING))
return len(self.errors) == 0
def perform_execution(self, ctx: ExecutionContext):
...
def perform_light_run(self, ctx: ExecutionContext):
...
perform_execution
This method sets the commands that are executed during the brick run.
You can receive the input by index using self.get_input_by_index(index).value or, only in case of a single input, by type with self.get_input_by_type(type).value. Then you perform some operations and at the end of it, you should fill the brick outputs with the corresponding values using self.fill_outputs_by_type_with_value(type, value) (makes sense for a single output only) or self.fill_outputs_by_name_with_value(name, value) and set the brick status to SUCCESS or, in case of exception, FAILURE.
With the custom code, you control the brick’s behavior, i.e. when certain conditions are met, you can show messages of three types: error (default), warning, or notification. Errors fail the brick execution, whereas warnings and notifications don’t.
To create a message, use the following syntax:
self.messages.append(Message(
message="Message text here",
context=self.message_context,
mtype=MessageType.<ERROR/WARNING/NOTIFICATION>)) # one of those
How messages are displayed:
Inside the perform_execution method, you can import any Python libraries you need.
Some of them are available to use without the requirement to import them (see Python Libs)
For instance, since the NumPy library is in the list, it’s possible to implement its methods without importing it explicitly:
This method is implemented to inform the pipeline of the brick output, like data types, and column names before its regular run. No need to do proper calculations here. For example, the output can be constructed as a 1-row pandas DataFrame with dummy variables (np.zeros, np.ones, etc) but with valid column names.
To save the current brick’s configuration, click on the Save button.
💡
Be aware that the saved changes in a Custom Brick are applied to all the pipelines that contain it. To make changes only to the current pipeline, please, create a copy of the brick.
You can drag-n-drop the created brick on the scene just like the other bricks. The brick must have the selected inputs and outputs and all the arguments appear on the right sidebar. To edit the Custom code brick use either the right sidebar or right-click the brick → update in Customization.
Example of usage
Let’s have a look at the simple example of Custom Code brick creation.
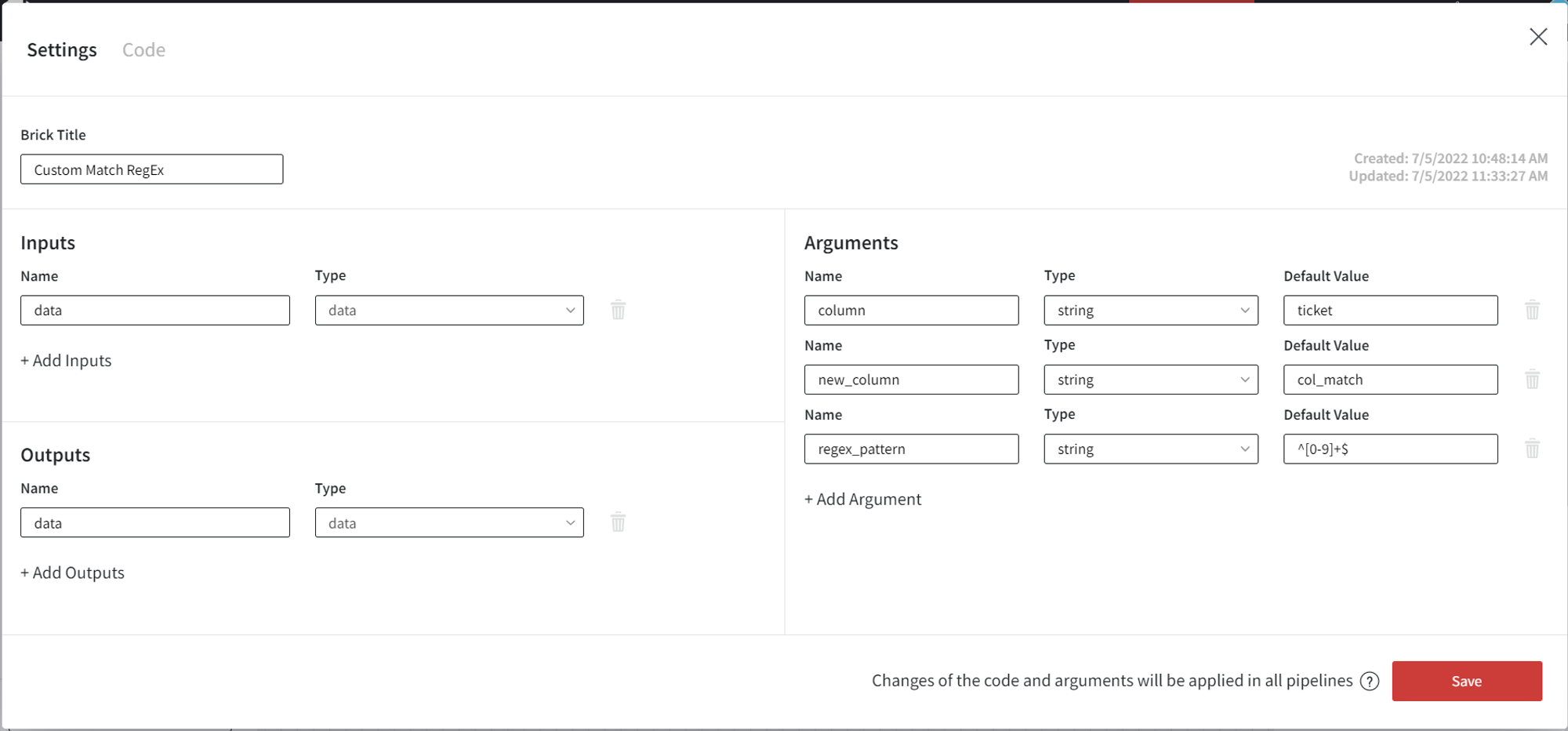
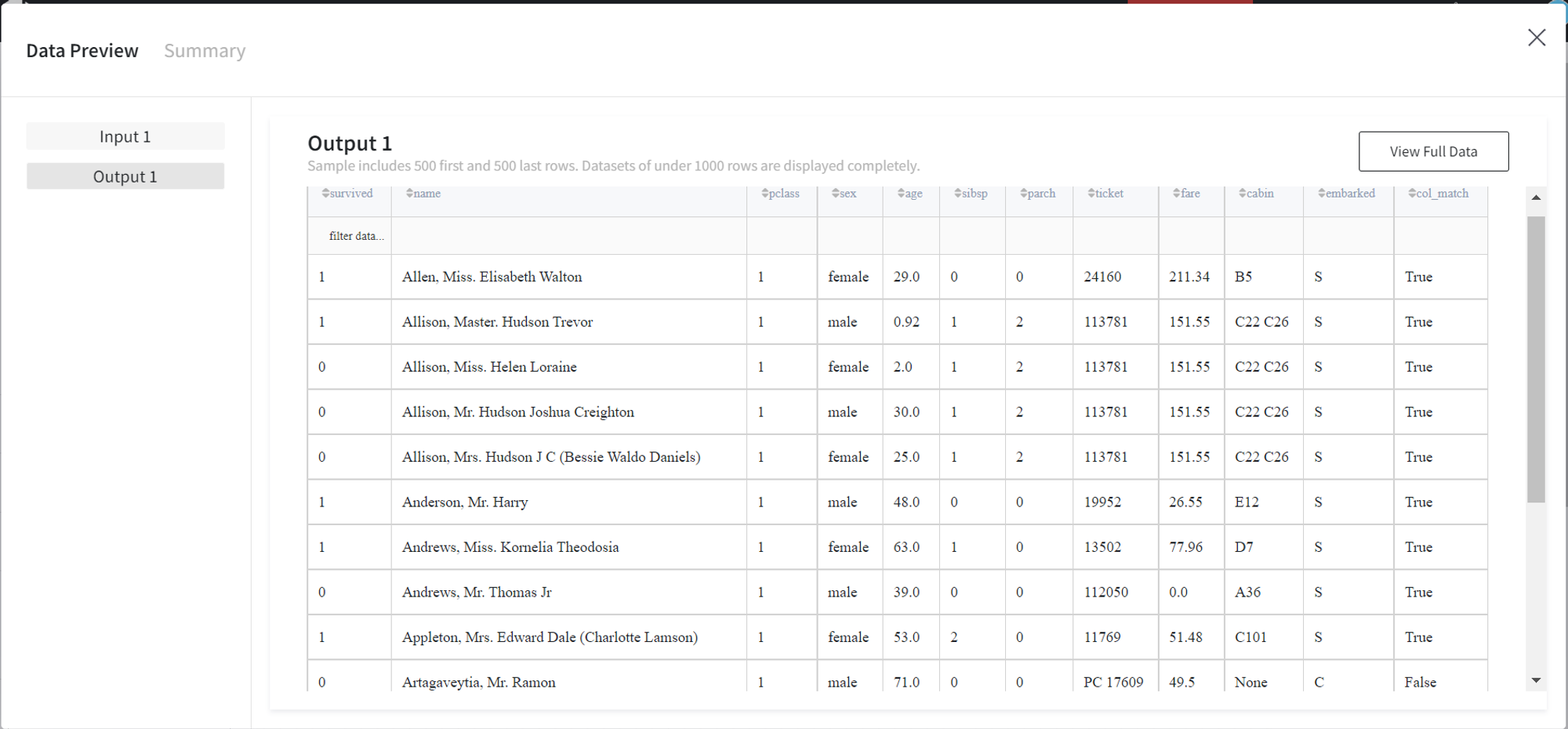
This brick checks if a certain column’s values match the defined RegEx pattern.
In this example, we check if column ‘ticket’ contains only numeric values, and create a new column ‘col_match’ with the results.
Brick settings:
The code:
class BrickCustomCode(Brick):
def validate_args(self, args):
# check data
if check_number_of_inputs(self, 1):
if check_input_with_type_has_value(self, "data"):
data = self.get_input_by_index(0).value
# check column
if check_argument_exists(self.args, "column", self.messages):
if check_argument_matches_type(self.args, "column", str, self.messages):
column = self.args.get("column")
if column not in data.columns:
self.messages.append(Message(
message=f"Column {column} does not exist in the input dataframe.",
context=self.message_context,
mtype=MessageType.ERROR,
))
# check new column
if check_argument_exists(self.args, "new_column", self.messages):
if check_argument_matches_type(self.args, "new_column", str, self.messages):
new_column = self.args.get("new_column")
if new_column in data.columns:
self.messages.append(Message(
message=f"Column {new_column} already exists in the input dataframe.",
context=self.message_context,
mtype=MessageType.NOTIFICATION,
))
# check pattern
if check_argument_exists(self.args, "regex_pattern", self.messages):
check_argument_matches_type(self.args, "regex_pattern", str, self.messages)
return len(self.errors) == 0
def perform_execution(self, ctx: ExecutionContext):
data = self.get_input_by_index(0).value.copy()
column = self.args.get("column")
new_column = self.args.get("new_column")
pattern = self.args.get("regex_pattern")
try:
regex_pattern = re.compile(pattern)
except Exception:
self.messages.append(Message(
message=f"Statement {pattern} cannot be recognised as RegEx. Please, check the syntax.",
context=self.message_context,
mtype=MessageType.ERROR,
))
if len(self.errors) > 0:
self.status = BrickStatus.FAILURE
else:
data[new_column] = data[column].apply(lambda x: bool(re.search(regex_pattern, x)))
self.fill_outputs_by_type_with_value("data", data)
self.status = BrickStatus.SUCCESS
def perform_light_run(self, ctx: ExecutionContext):
data = self.get_input_by_index(0).value
new_column = self.args.get("new_column")
cols = list(data.columns)
if new_column not in cols:
cols.append(new_column)
if len(cols) > 0:
data = pd.DataFrame(np.zeros((1, len(cols))), columns=cols)
self.fill_outputs_by_type_with_value("data", data)
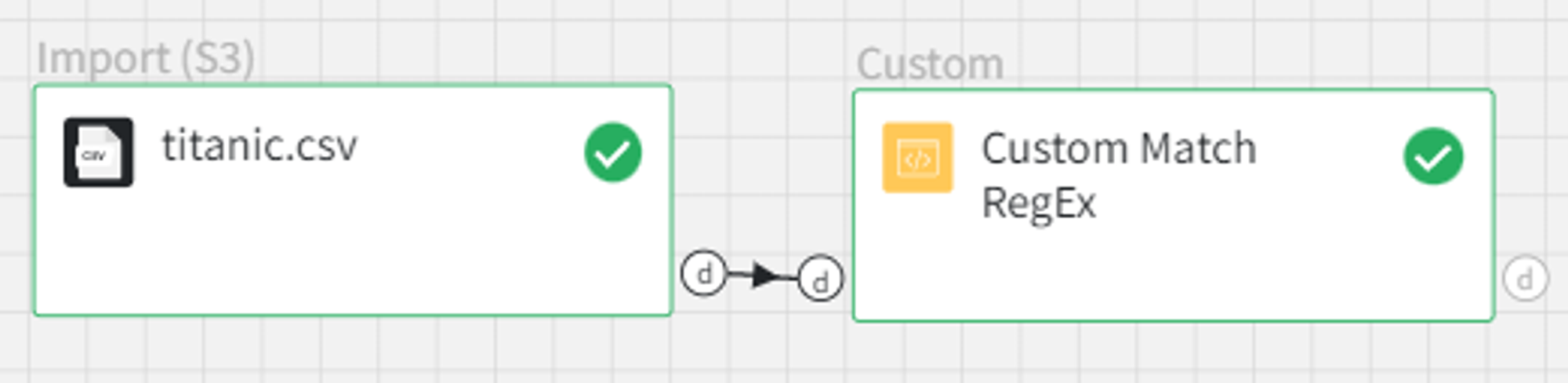
After running the pipeline, we see that the brick was executed successfully and returned the dataset with an extra column.