Whenever the model is trained, AutoModel API is instantly created and can be used to generate predictions out of the platform.
There are 2 possibilities to access the model api:
- From any model brick
- From the saved model in the list of models
Access api from any model brick
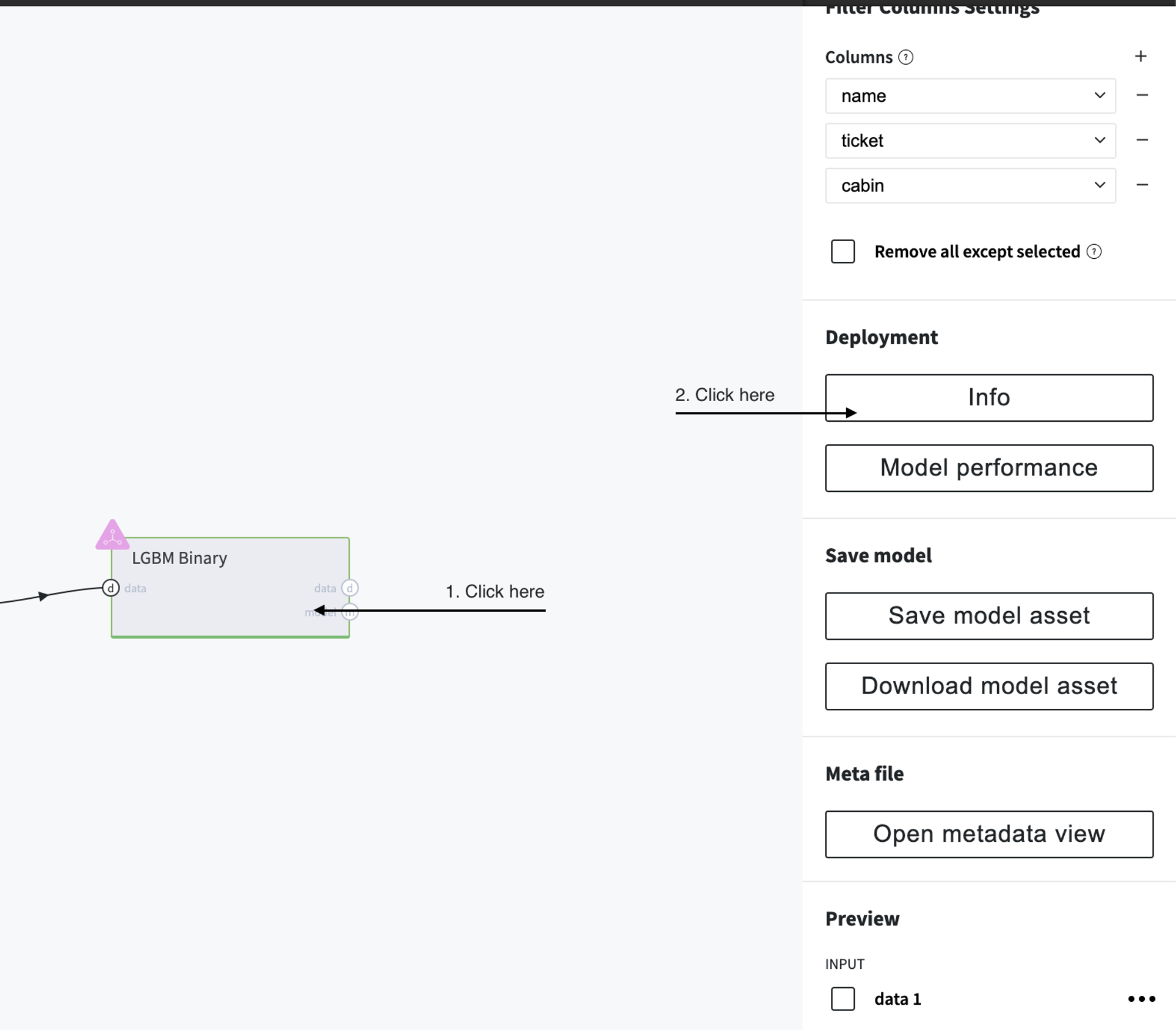
Train any model and then click on "Info" button in the right panel
Saving the model
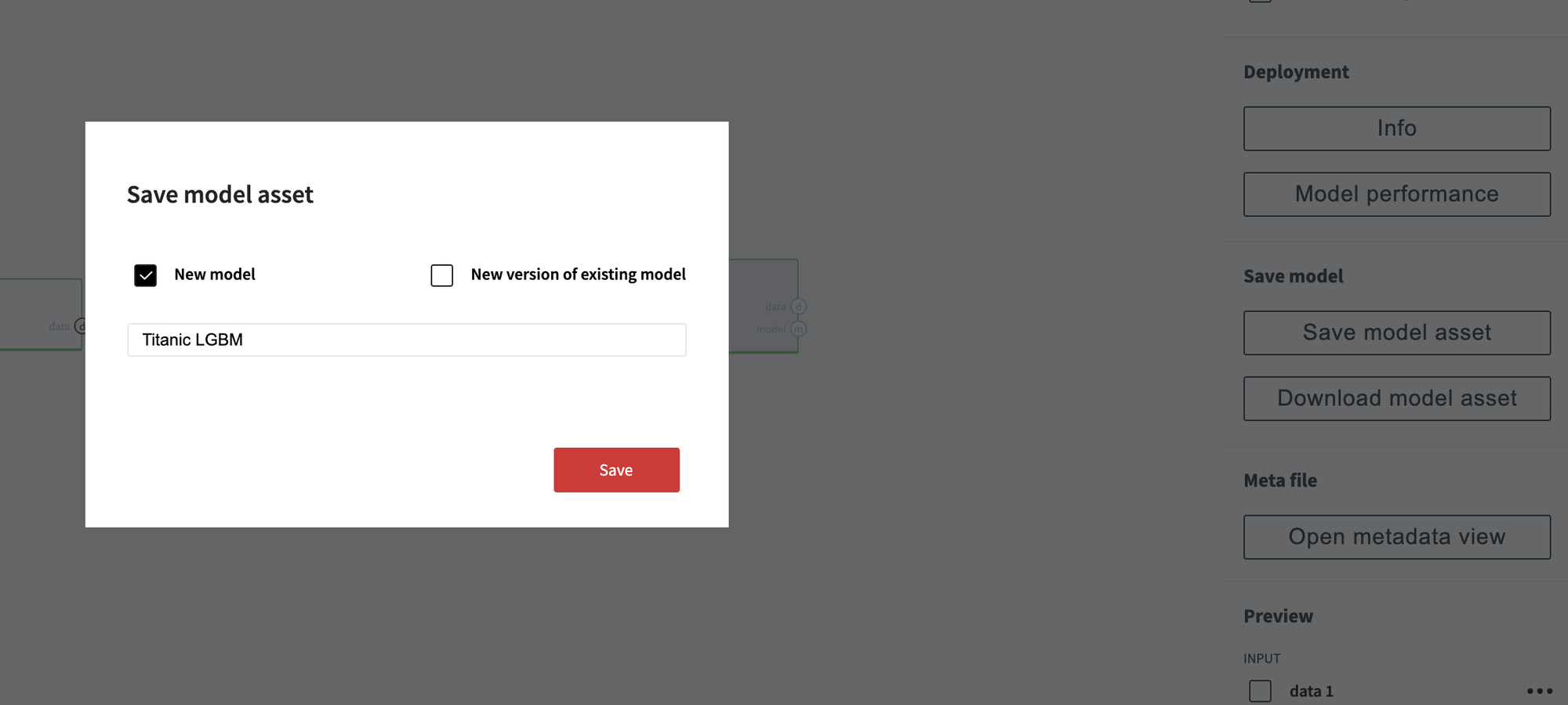
To save the model you should click on the "Save mode as asset" button on any model brick in the right panel
You can save trained model as a new one or can set the new version of the existing model
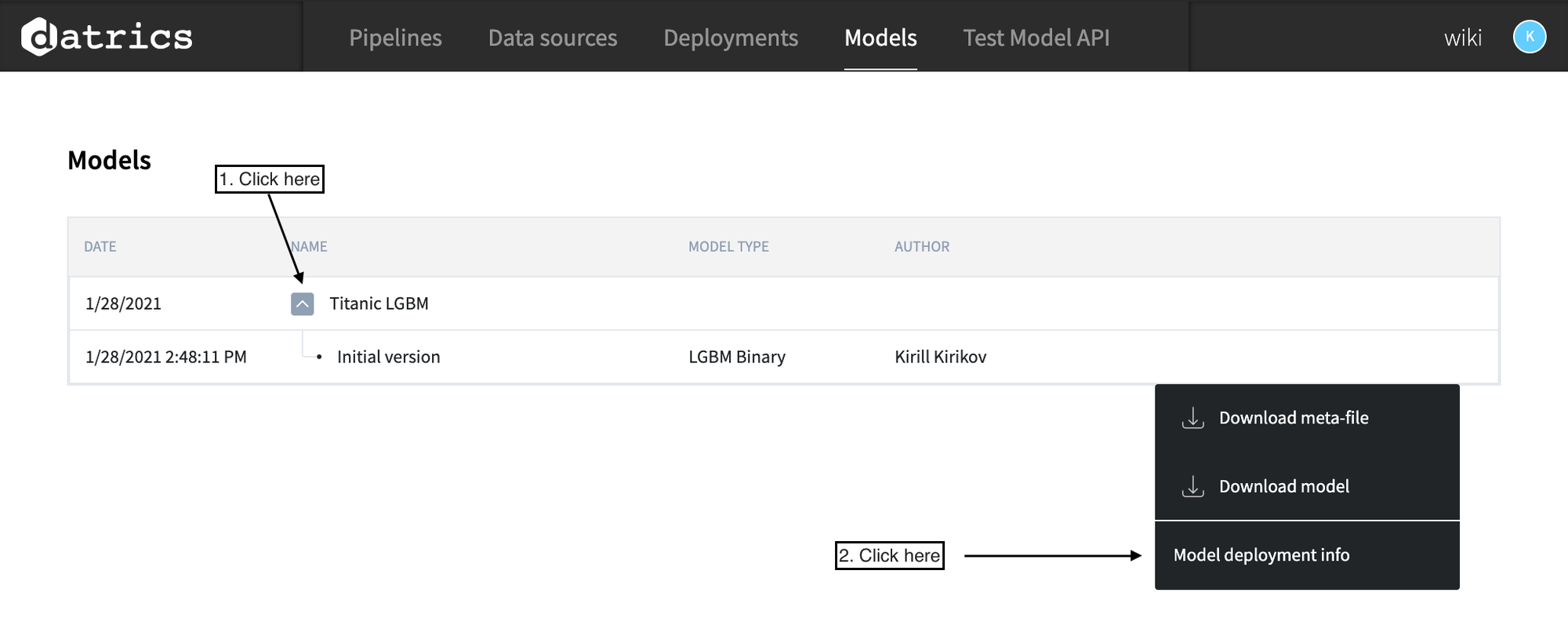
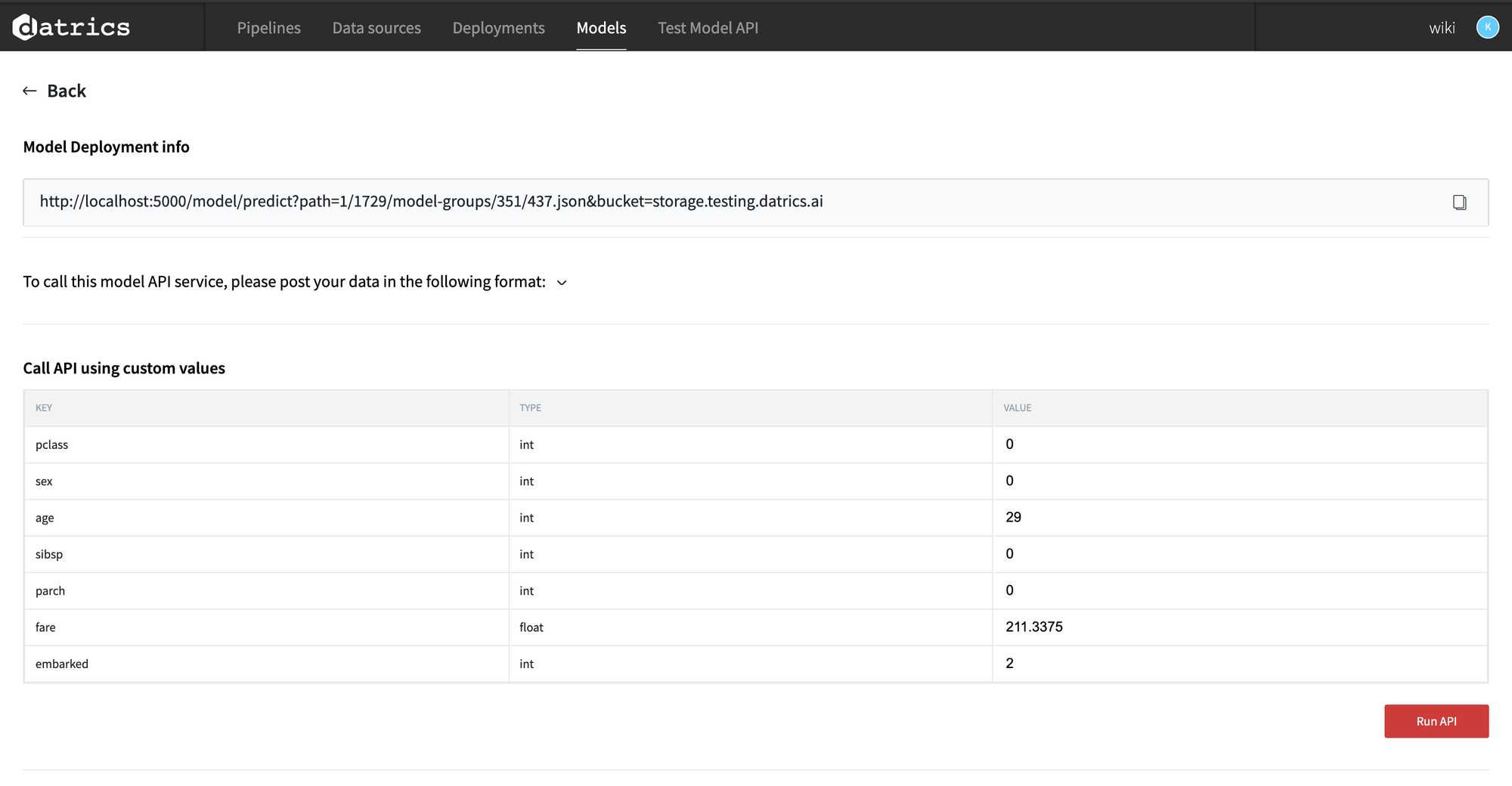
Using model API from the list of saved models
Using model API (what-if)
From within the platform you can use the "what-if" interface. In this interface, you can pass any parameters to the model and send them to the model API to generate predictions
Using model API from your code
To access the model API from your code you must do next steps
Step 1: Generate access token
import jwt API_SECRET = "<ask you system administrator>" USER_DATA = { "userId": "<your user id>", "email": "<your email>" } token = jwt.encode(user_data, secret, algorithm="HS256")
Step 2: Run task to generate predictions, it will return the task id that will be used to retrieve predictions
import json import requests API_BASE_URL = 'https://api.app.datrics.ai/api/v1/proxy/pipeline/model/predict' API_RETURN_ONLY_PREDICTIONS=False MODEL_PATH = "1/4/model-groups/1/1.json" MODEL_BUCKET = "storage.datrics.ai" def create_prediction_task(data, token): r = requests.post( # this URL you can get in datrics in model deployment info f'{API_BASE_URL}?path={MODEL_PATH}&bucket={MODEL_BUCKET}&return_only_prediction={API_RETURN_ONLY_PREDICTIONS}', data=json.dumps(data), headers={ 'authorization': f'Bearer {token}', 'content-type': 'application/json;charset=UTF-8', } ) return r.json().get('id') task_id = create_prediction_task([ { "order_amount":700, "average_monthly_income":0, "employment_status_Employed":0, "employment_status_Self-Employed":0, "employment_status_Contract":0 } ], token)
Step 3: Retrieve predictions by task_id
from time import sleep import json import requests def poll_task_for_result(task_id, token): while True: r = requests.get( f'{API_BASE_URL}/info/{task_id}', headers={ 'authorization': f'Bearer {token}' } ) result = r.json() if result.get('state') == 'SUCCESS': return result elif result.get('state') == 'STARTED': sleep(1) else: return { 'error': result }
Full code example
import jwt import json import requests from time import sleep API_BASE_URL = 'https://api.app.datrics.ai/api/v1/proxy/pipeline/model/predict' API_SECRET = "" USER_DATA = { "userId": "", "email": "" } API_RETURN_ONLY_PREDICTIONS=False MODEL_PATH = "" MODEL_BUCKET = "" MODEL_REQUEST_DATA = [ { "pclass": 0, "sex": 0, "age": 29, "sibsp": 0, "parch": 0, "fare": 211.3375, "embarked": 2 } ] def main(): # we generate access token to access API token = generate_access_token(USER_DATA, API_SECRET) # we start the preiction task and getting back it's ID task_id = create_prediction_task(MODEL_REQUEST_DATA, token) # we poll server with this ID to get the prediction result if task_id is not None: result = poll_task_for_result(task_id, token) print(f"Prediction result: {result}") else: print("Cannot authenticate") def generate_access_token(user_data, secret): return jwt.encode(user_data, secret, algorithm="HS256") def create_prediction_task(data, token): r = requests.post( # this URL you can get in datrics in model deployment info f'{API_BASE_URL}?path={MODEL_PATH}&bucket={MODEL_BUCKET}&return_only_prediction={API_RETURN_ONLY_PREDICTIONS}', data=json.dumps(data), headers={ 'authorization': f'Bearer {token}', 'content-type': 'application/json;charset=UTF-8', } ) return r.json().get('id') def poll_task_for_result(task_id, token): while True: r = requests.get( f'{API_BASE_URL}/info/{task_id}', headers={ 'authorization': f'Bearer {token}' } ) result = r.json() if result.get('state') == 'SUCCESS': return result elif result.get('state') == 'STARTED': sleep(1) else: return { 'error': result } if __name__ == '__main__': main()