Description
The Clustering Benchmark Datasets contain 3 synthetic datasets conforming a structured domain with intuitively separable clusters in different forms as shown below.
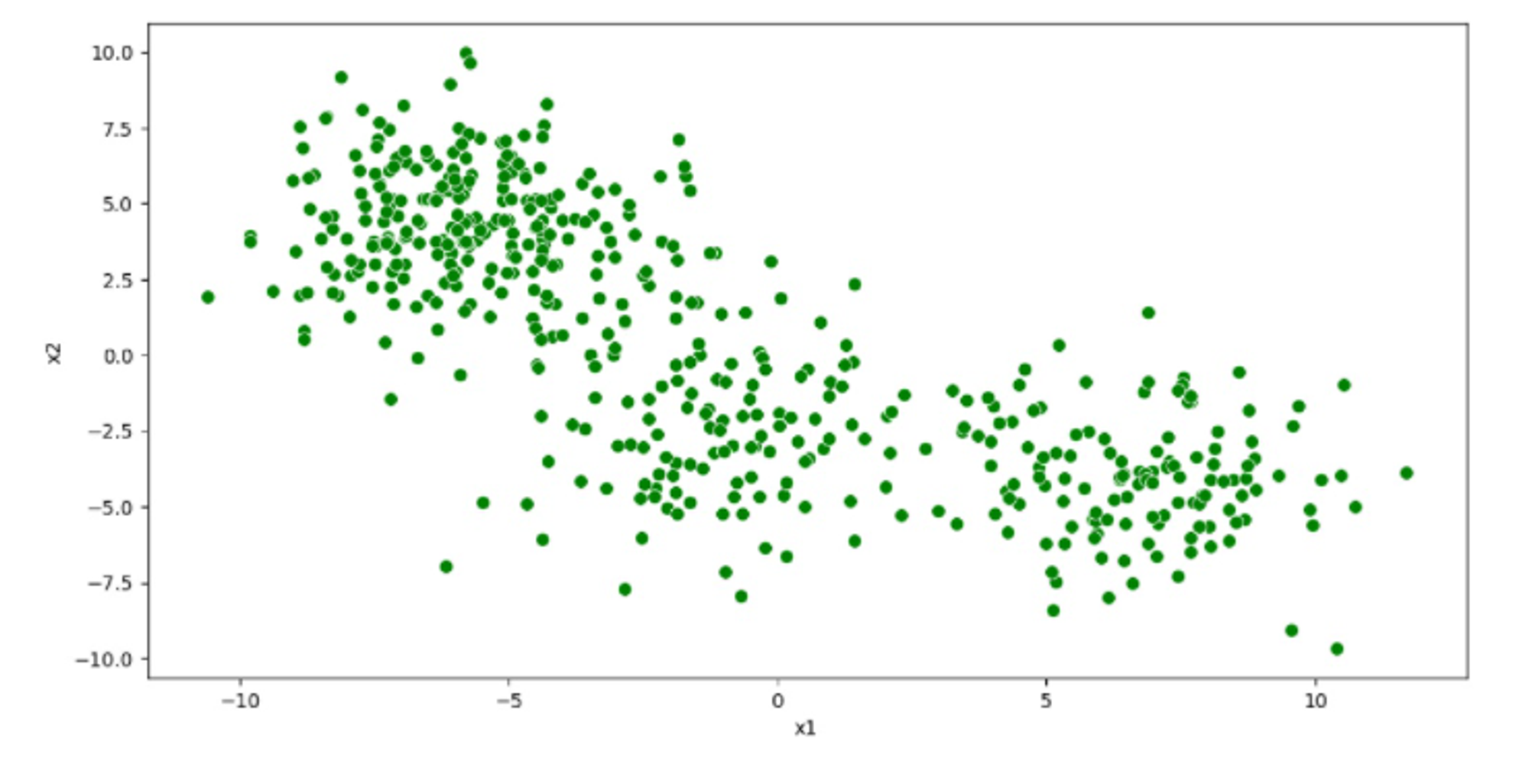
Blobs Dataset
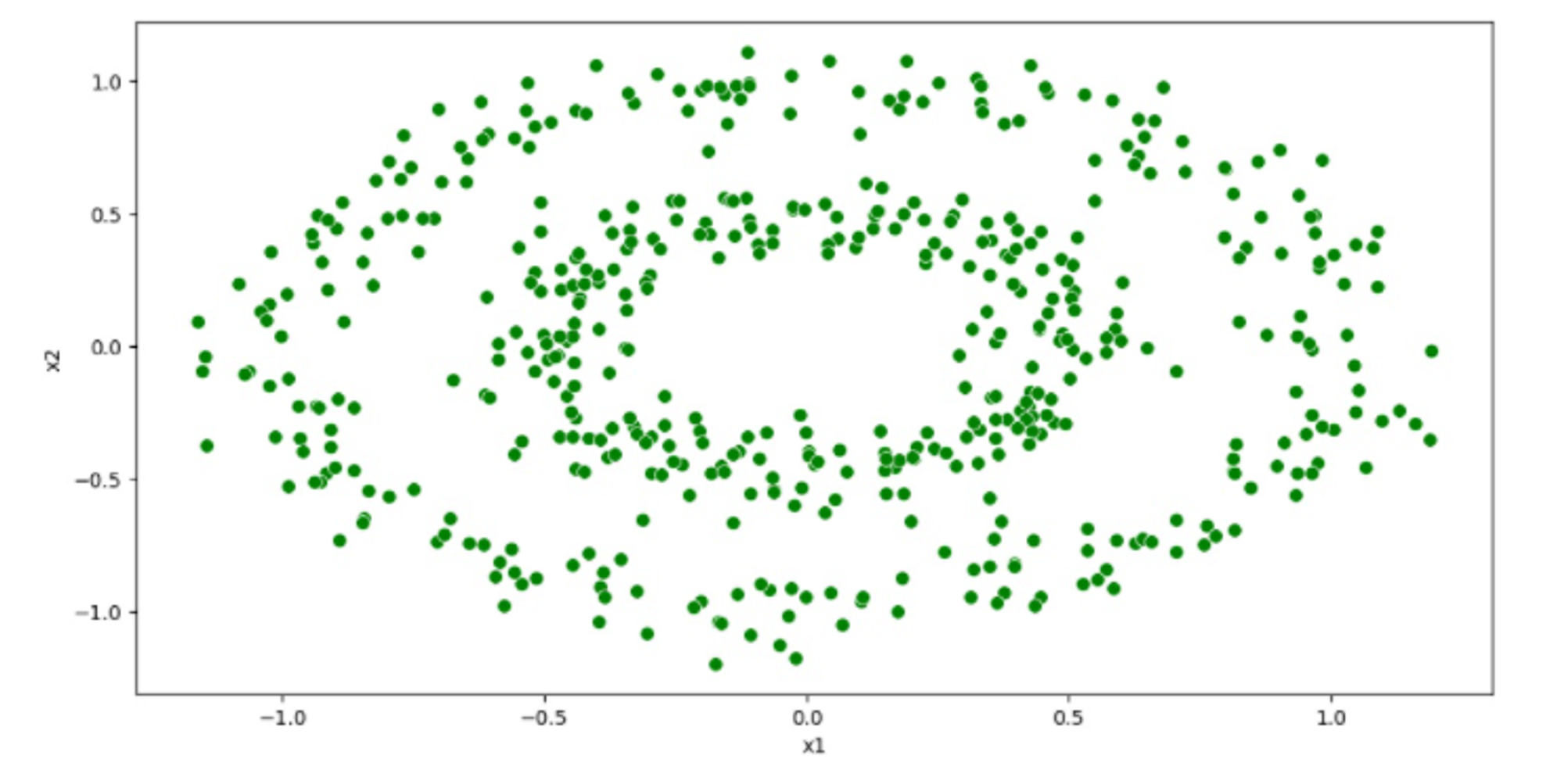
Circles Dataset
Moons Dataset
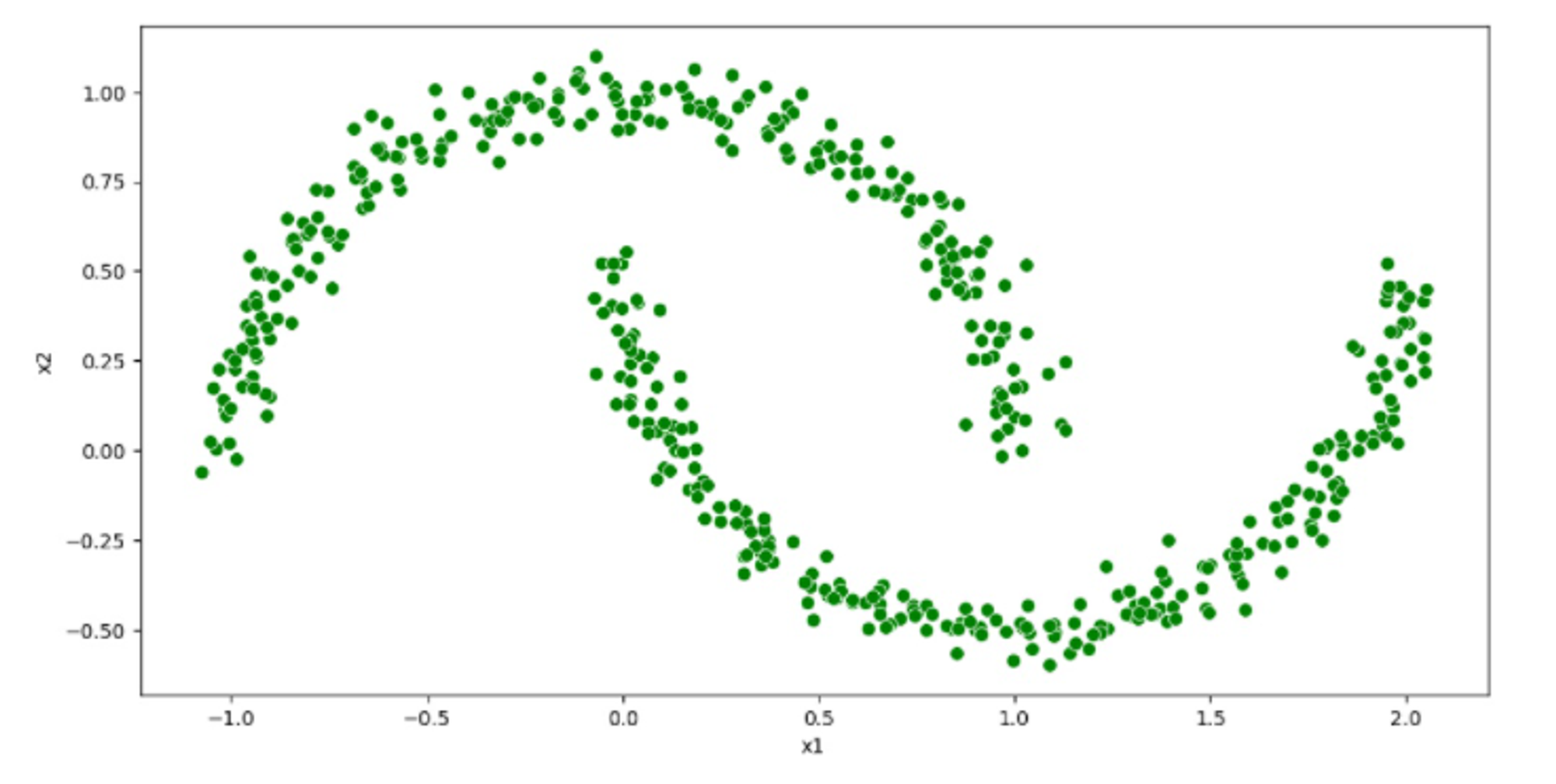
All three datasets include 500 data points in 2-dimensional space.
This dataset is often used for experimenting with clustering techniques and exploring their performance visually.
Data Location
Storage → Samples → segmentation_blobs.csv
Storage → Samples → segmentation_circles.csv
Storage → Samples → segmentation_moons.csv
Data Description