General information
Brick provides a possibility to create a new column by adding it to the existing dataset or as a separate dataset.
Description
Brick Locations
Bricks → Data Manipulation→ Create New Column
Brick Parameters
- General configuration: ‘Add column’ / ‘New dataset’
‘Add column’ adds a new column to an input dataset.
‘New dataset’ creates a new dataset with one column.
- Column name
Input field for the new column’s name. This field is obligatory for any setting selected.
- Setting
- ‘Value’ - fill the column with the flat value.
- ‘Empty value’ - fill the column with an empty value.
- ‘Duplicate column’ - copy a specified column from the input data.
- ‘Range from’ - a numeric range of values defined by range start and step.
- ‘Random values’ - fill the column with random values in a specified interval.
- ‘Random list’ - fill the column with random values from the list.
- ‘List’ - add a list of values as a new column.
- ‘Value’ - fill the column with the flat value.
- ‘Empty value’ - fill the column with an empty value.
- ‘Range from’ - a numeric range of values defined by range start, step, and total size.
- ‘Range from to’ - a numeric range of values defined by range start, end, and step.
- ‘Random values’ - fill the column with random values in a specified interval.
- ‘Random list’ - fill the column with random values from the list.
- ‘List’ - add a list of values as a new column.
One of the options available in the drop-down menu:
For ‘Add column’:
For ‘New dataset’:
Additional configurations based on the selected Setting:
Value:
- Value
Constant column value.
- New column type
The type of the new column.
Duplicate column:
- Column
Input dataset column to copy.
Range from:
- From
Range start (included) - any number.
- Step
Range step - any positive number.
Range from to:
- From
Range start (included) - any number.
- To
Range end (excluded) - any number.
- Step
Range step - any positive number.
Random values:
- From
Interval start (included) - any number compatible with the New column type.
- To
Interval end (included) - any number > ‘From’, compatible with the ‘New column type’.
- New column type
Integer or float.
Random list:
- List of values
List of values to sample from. Use NA or Inf to indicate missing or infinity values and ‘NA’, or ‘Inf’ to define their strings.
- Separator
List values separator.
- New column type
The type of the new column.
List:
- List of values
List of the new column’s values. Use NA or Inf to indicate missing or infinity values and ‘NA’, or ‘Inf’ to define their strings.
- Separator
List values separator.
- New column type
The type of the new column.
For ‘New dataset’:
- Number of rows
The number of rows in the new dataset column. For some settings, it is calculated automatically.
Brick Inputs/Outputs
- Inputs
Brick takes the dataset (optionally in case of the 'New dataset' setting).
- Outputs
Brick produces the result as an extended input dataset with one additional column as specified in the parameter ‘Column name’ or a dataset with only one column in the case of the 'New dataset' setting.
Example of usage
Add column
This option requires the connected input dataset. We will use the ‘titanic.csv’ dataset for the next examples.
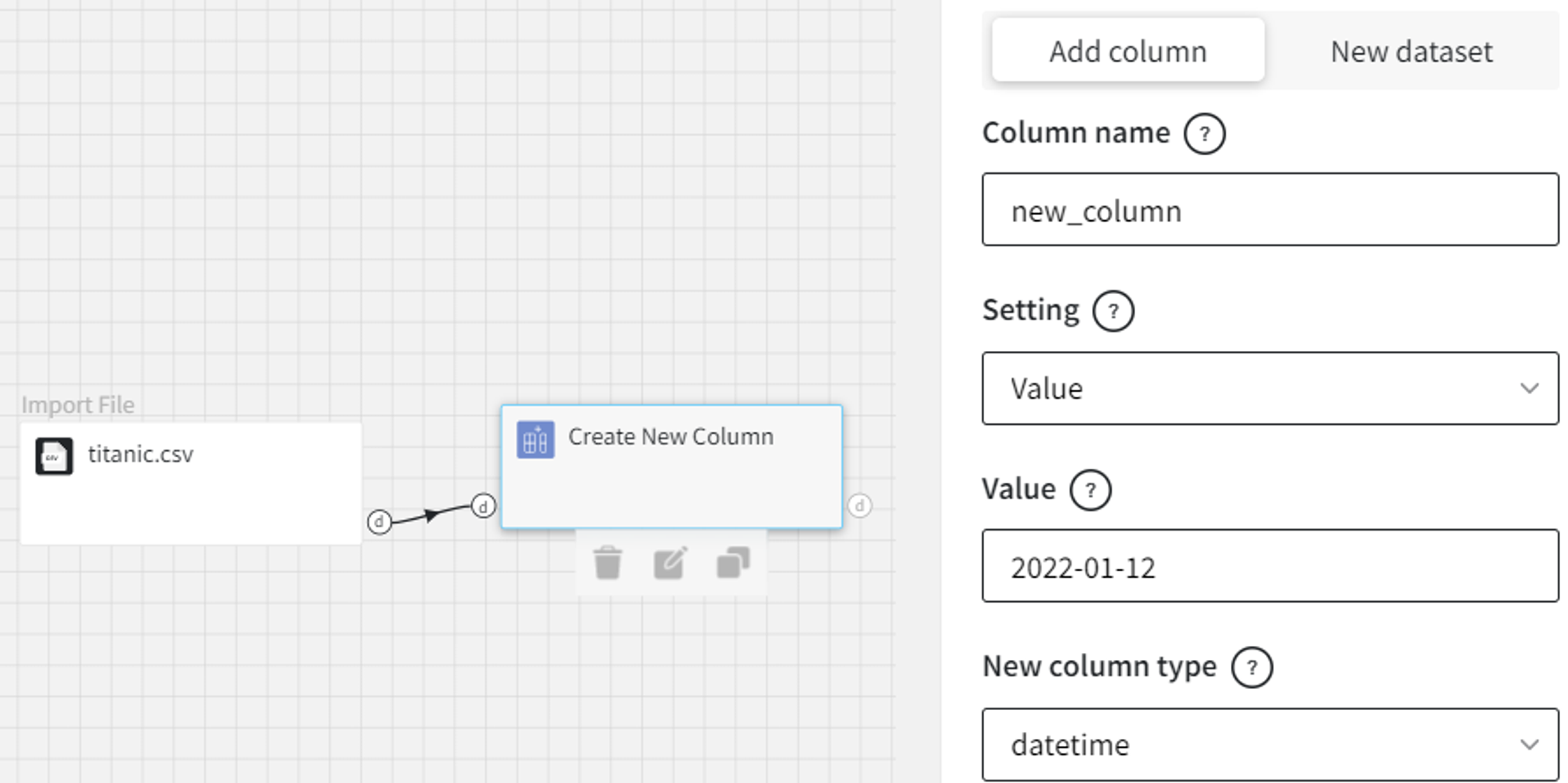
- Value
Here, we add Jan 12, 2022, as the values of the ‘new_column’:
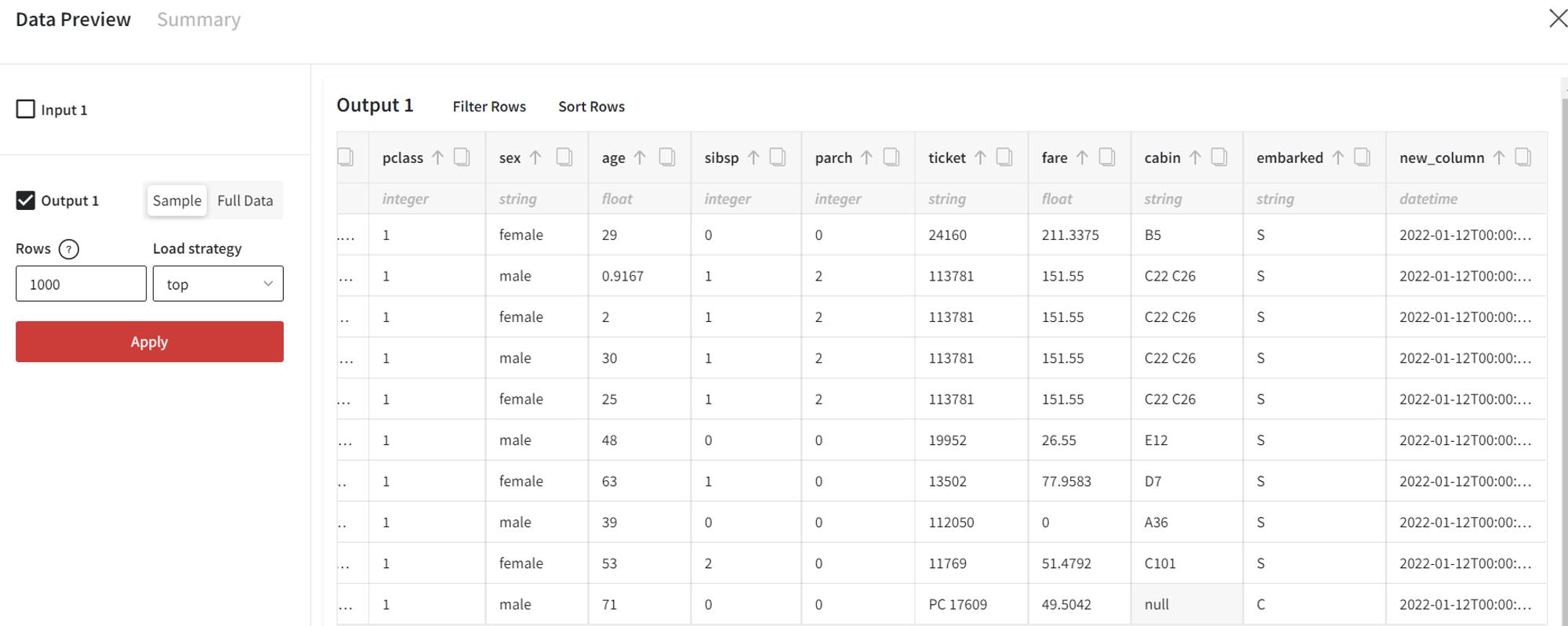
After running the pipeline, the output data is the following:
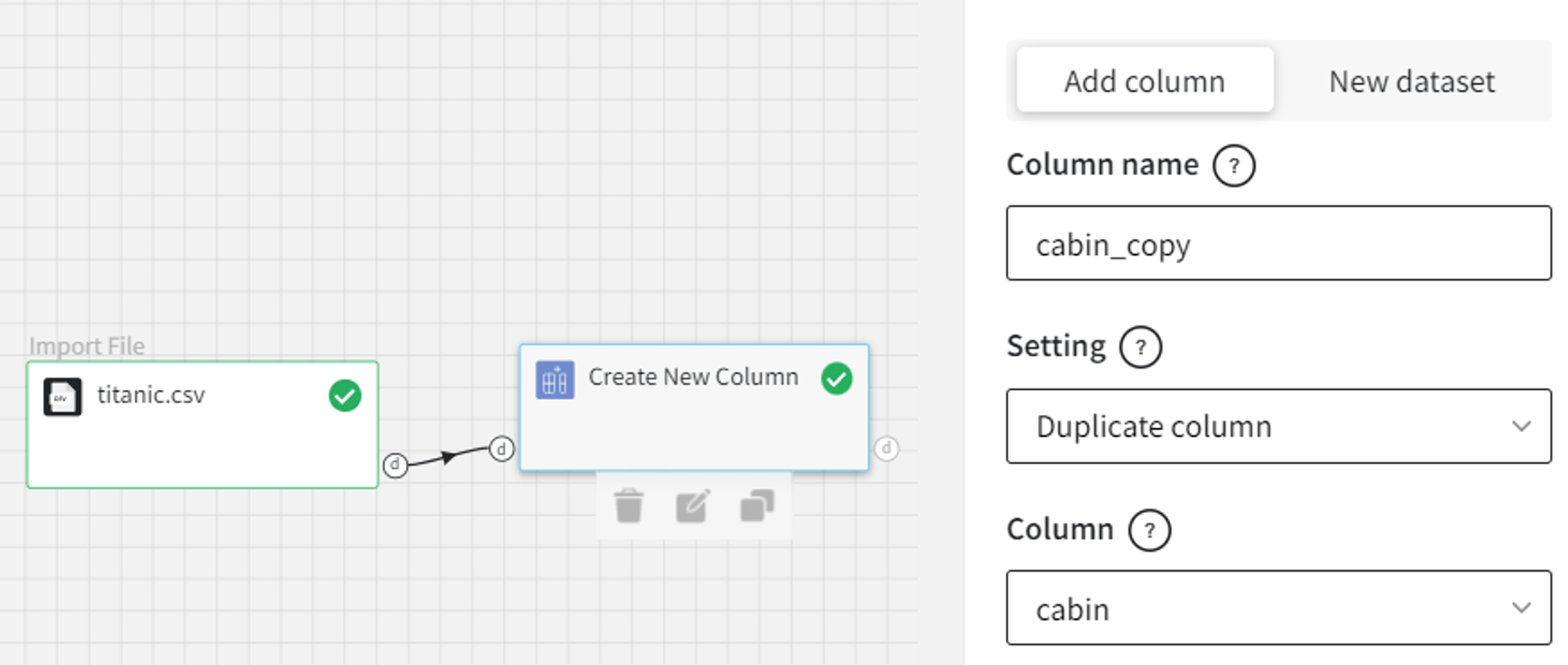
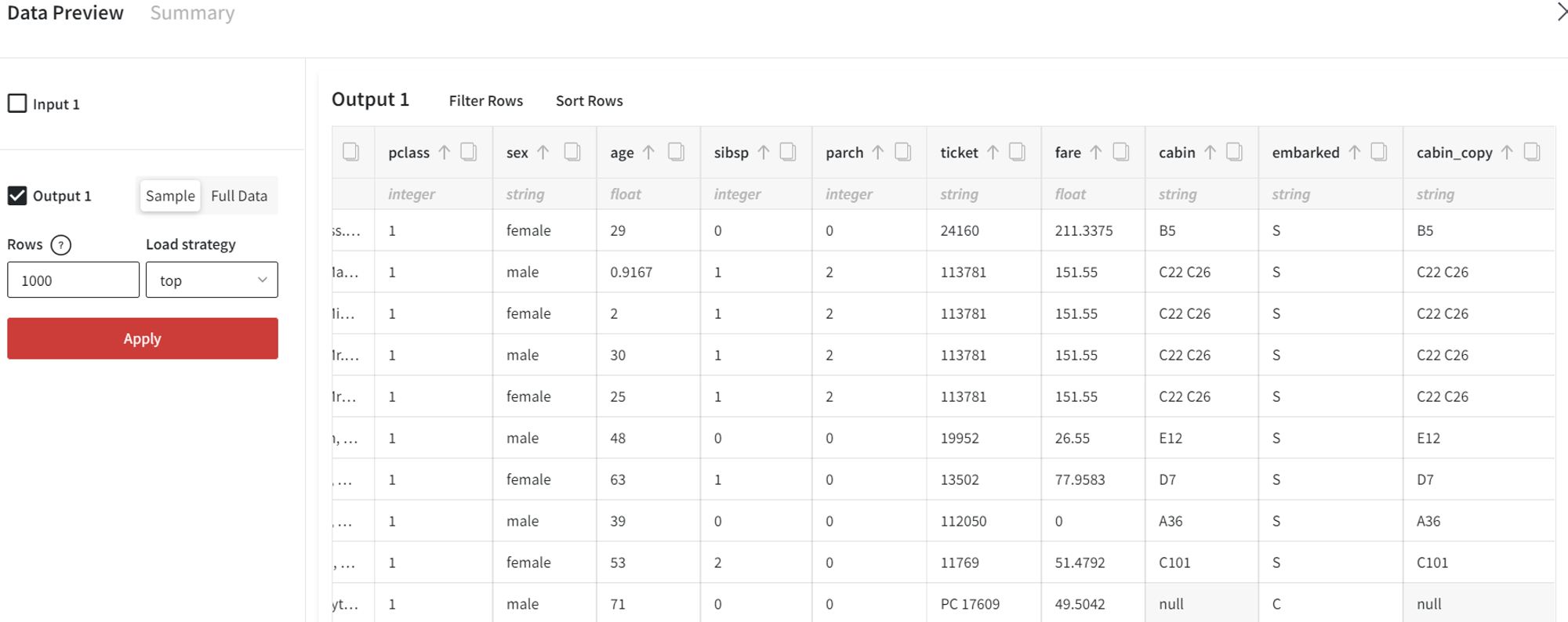
- Duplicate column
Let’s duplicate the ‘cabin’ column into the new column called ‘cabin_copy’.
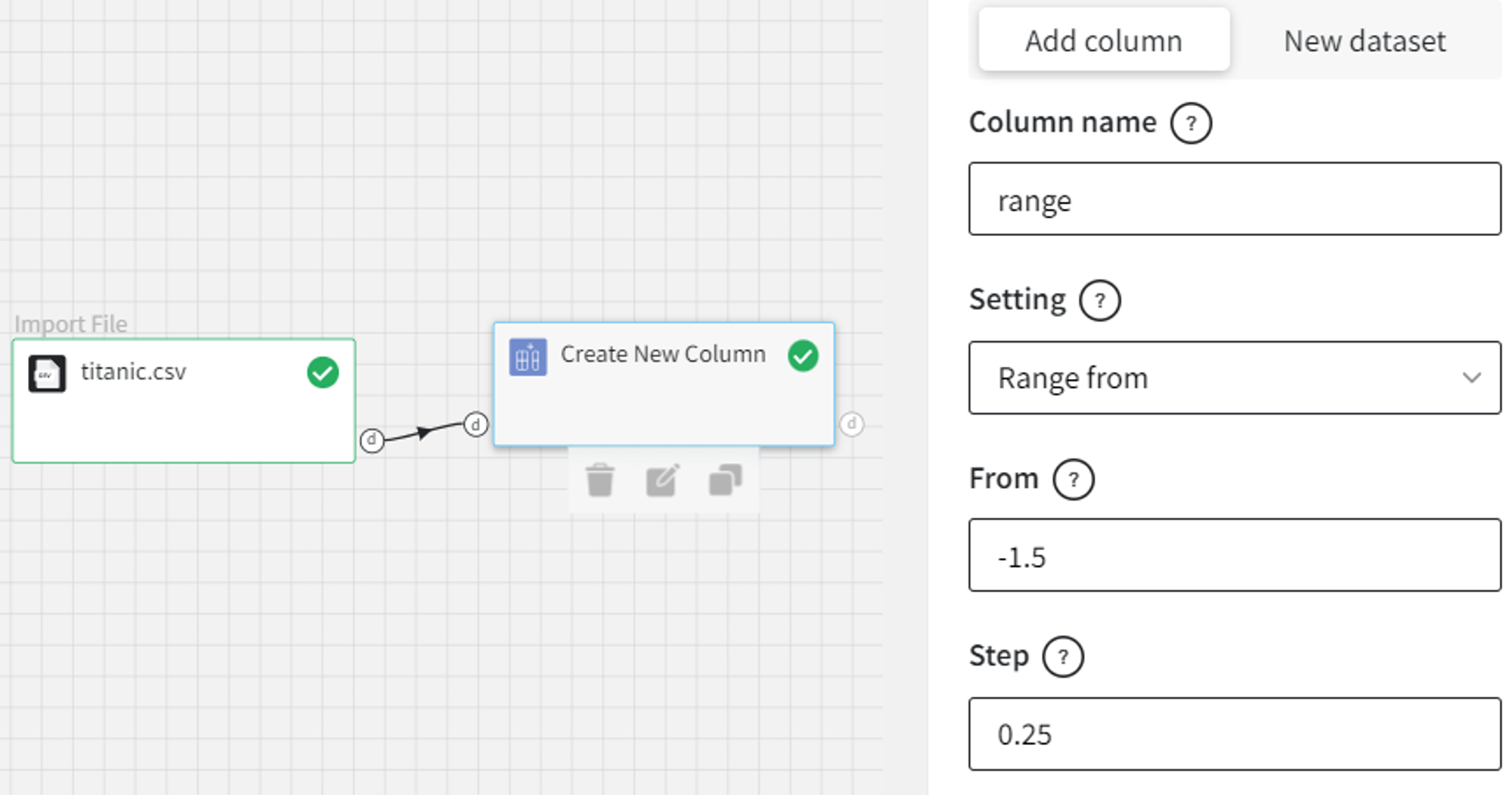
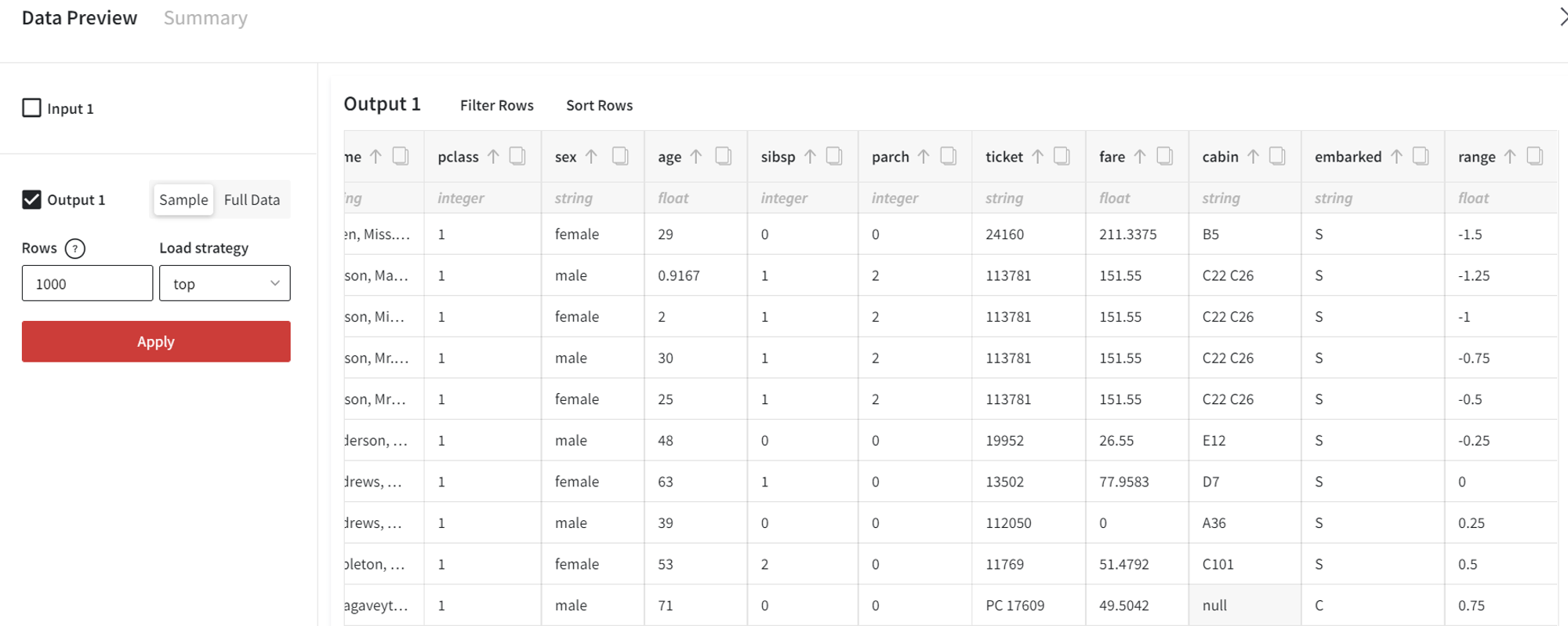
- Range from
It is possible to fill the new column with a range of values.
For example, we can create a range from -1.5 with the step equal to 0.25.
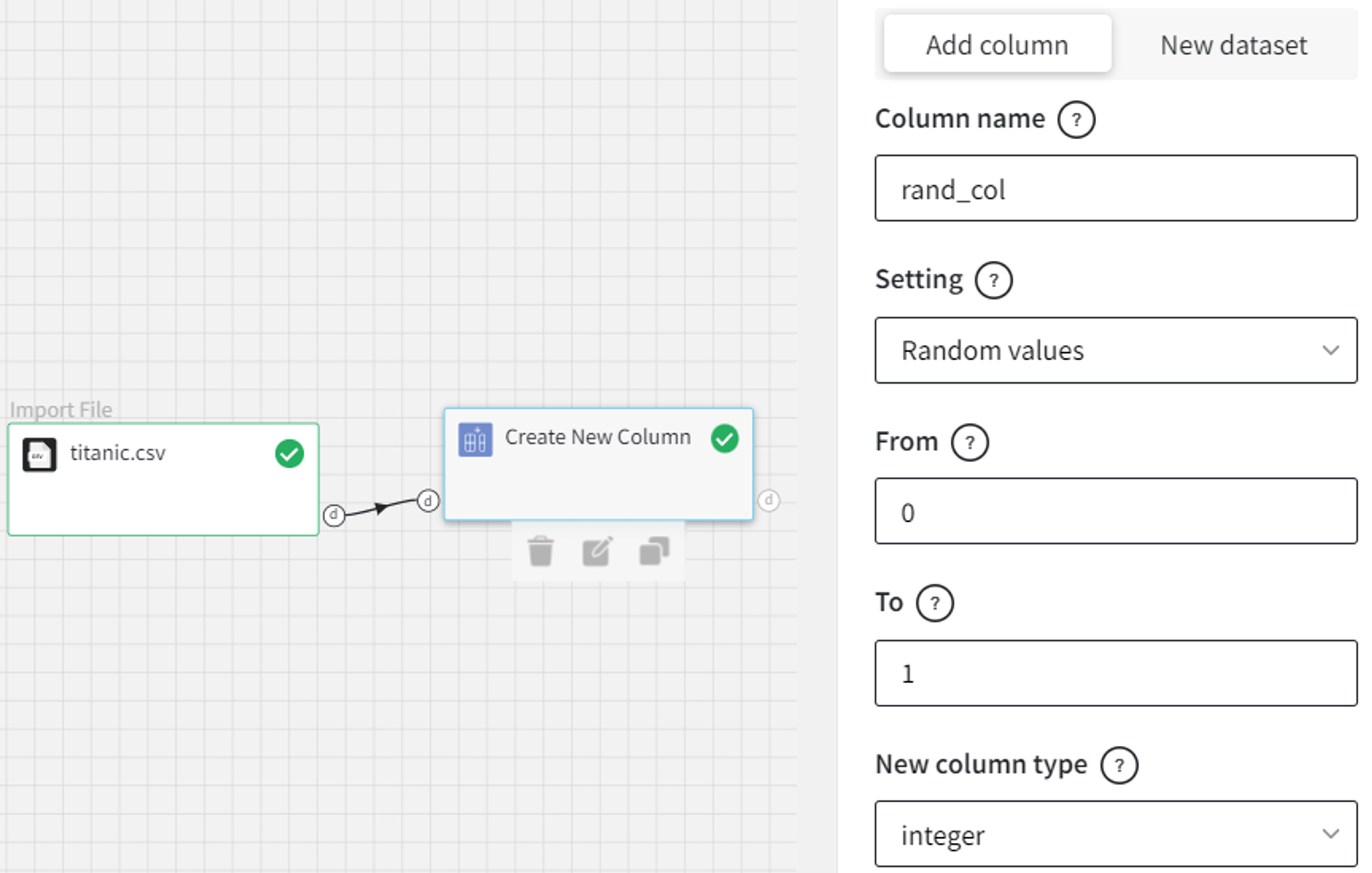
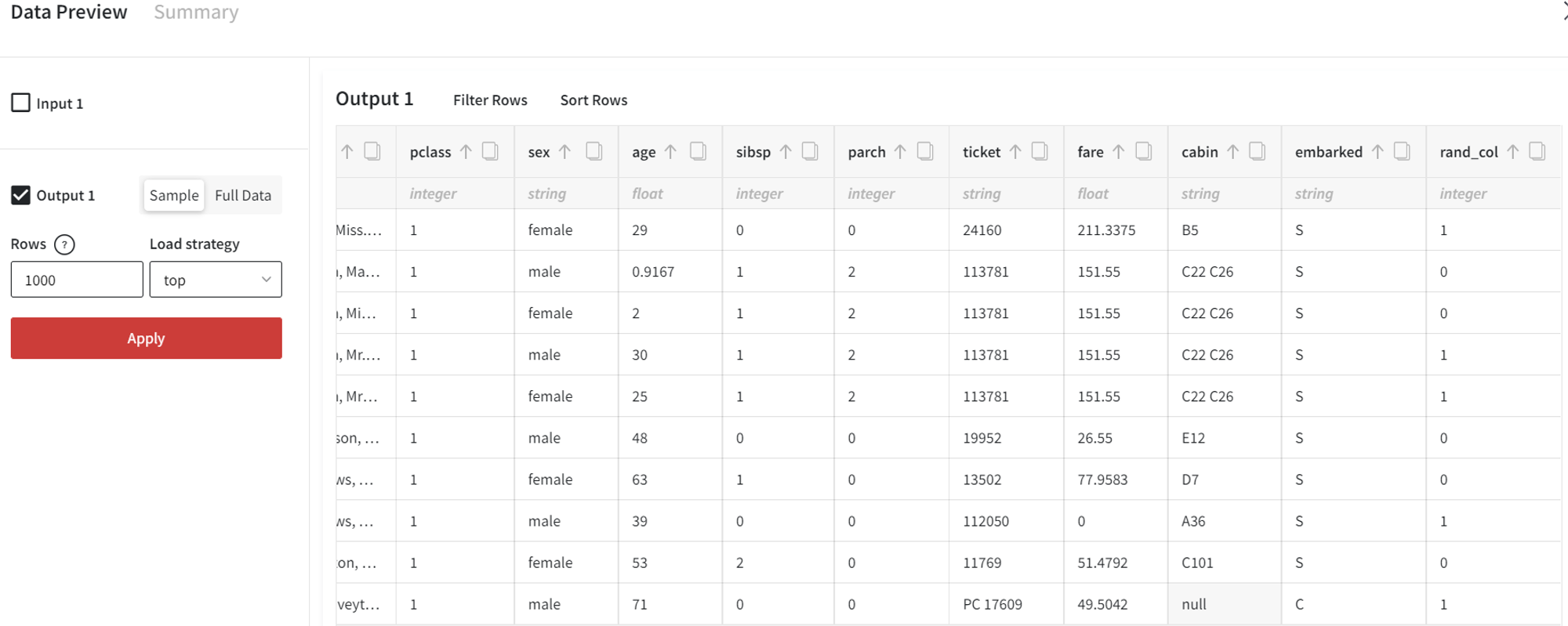
- Random values
If we would like to generate the random binary column, the settings are the following:
New dataset
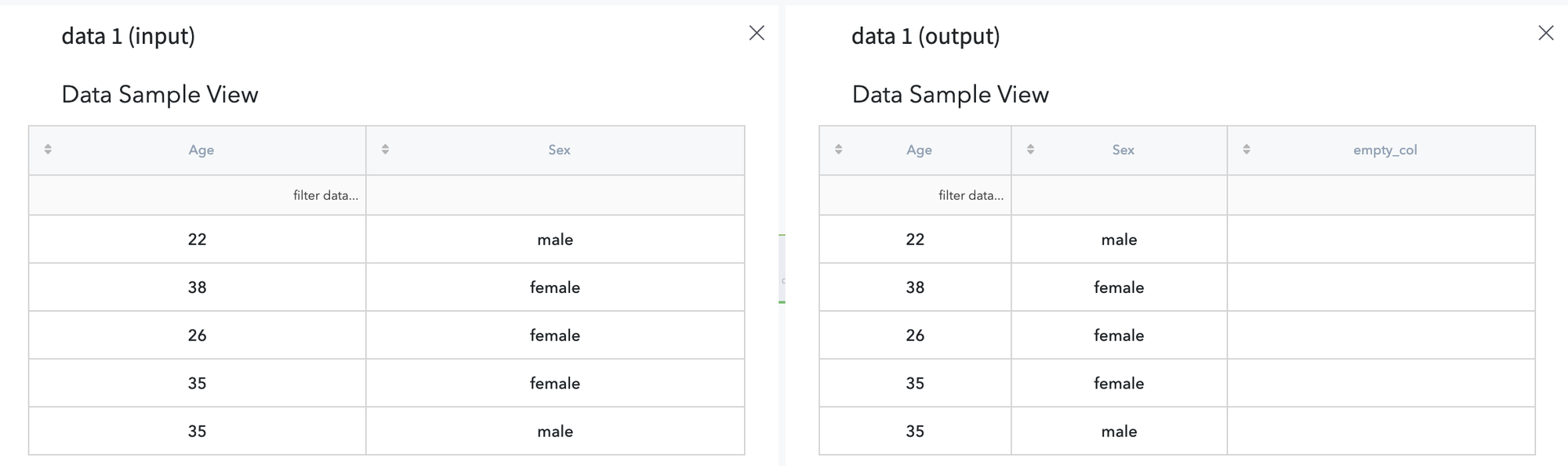
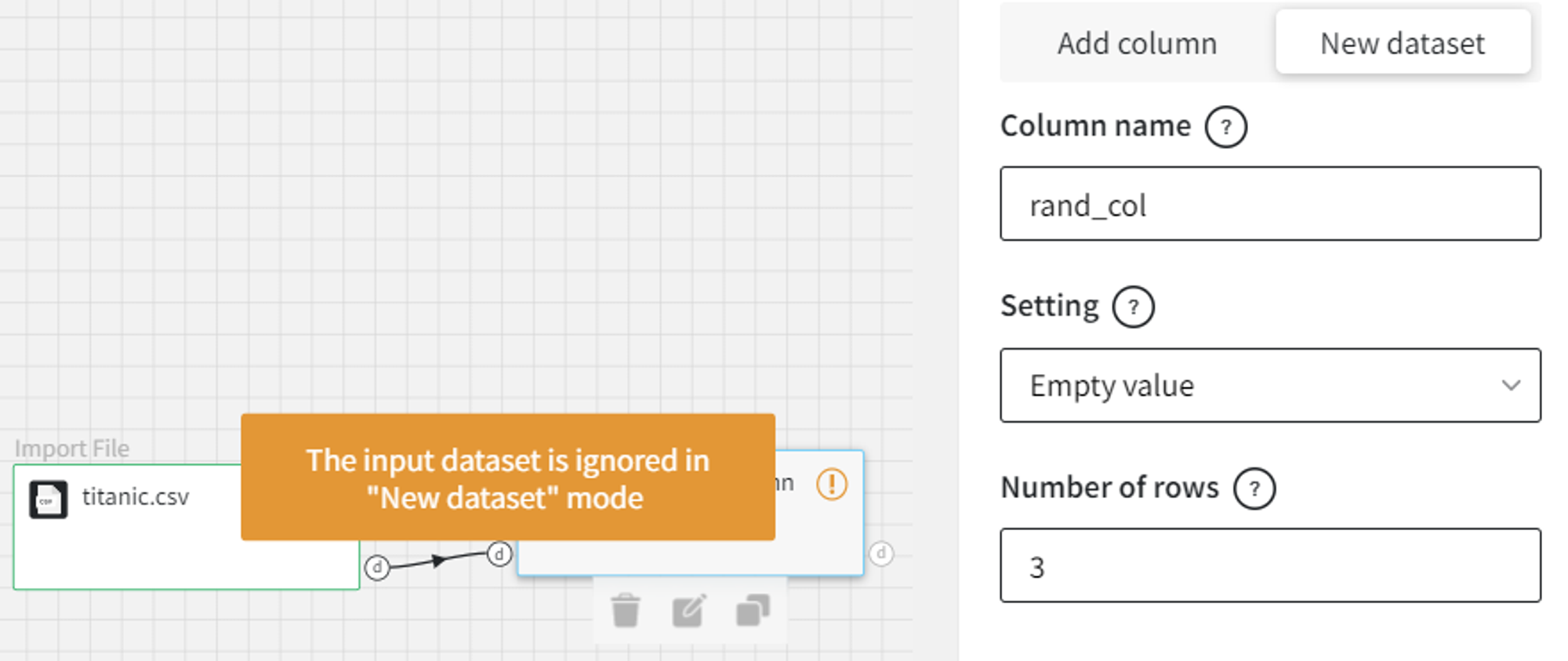
- Empty value
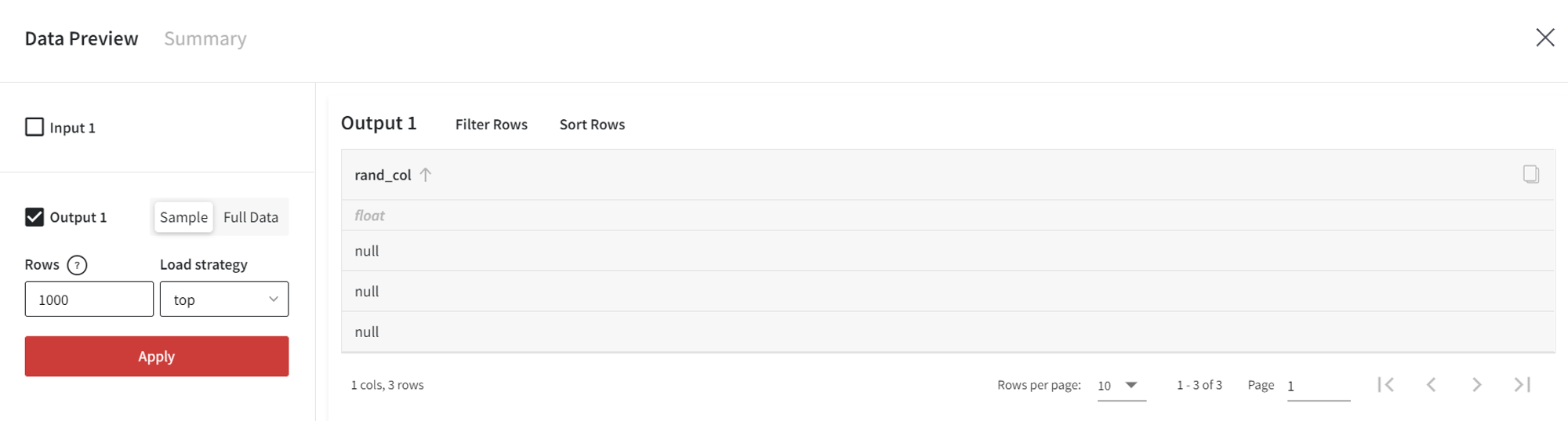
First, let’s create a new dataset with an empty column of size 3 named ‘empty_col’.
For ‘New dataset’ the input dataset is optional and will be ignored.
In the output, we get:
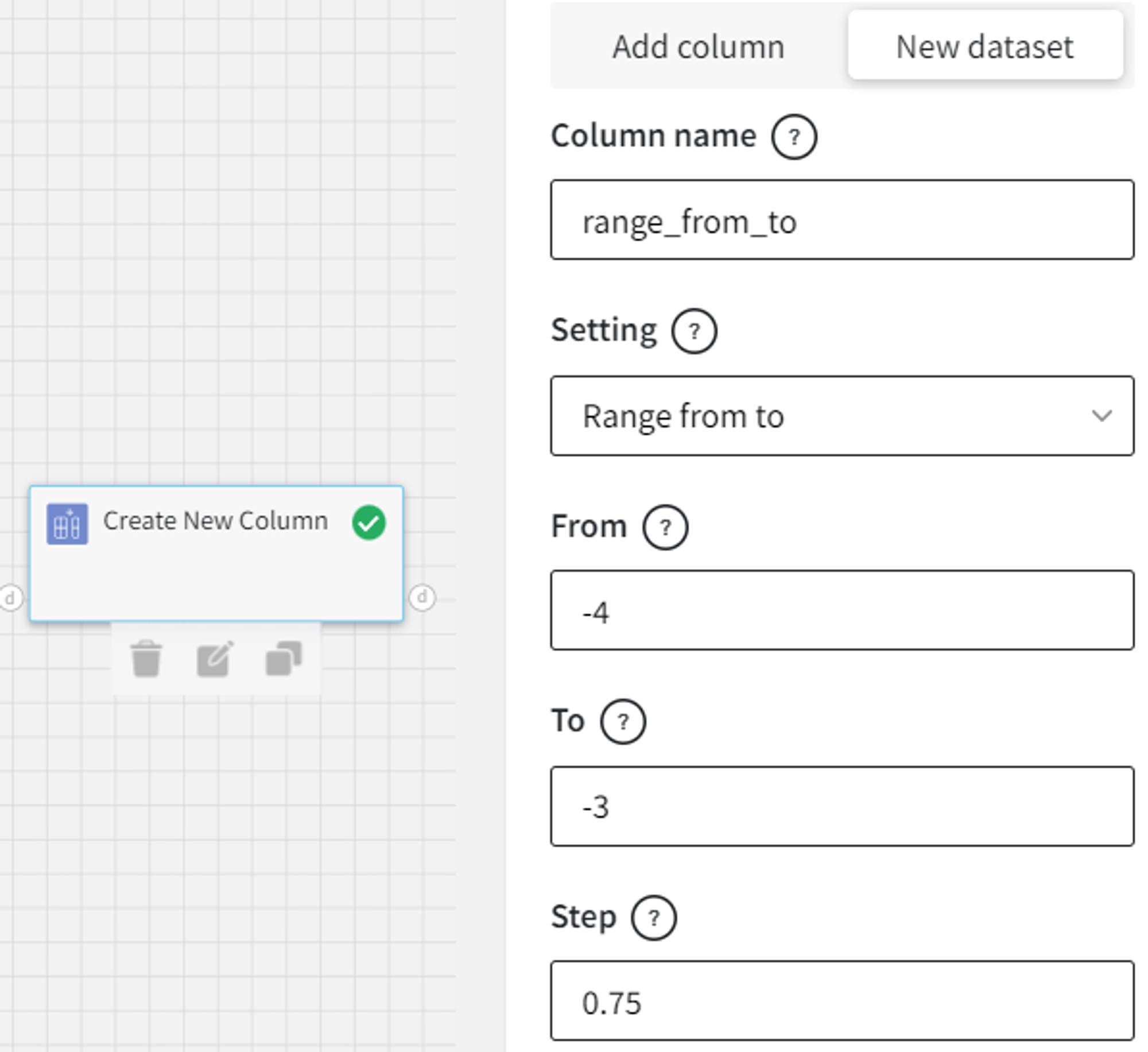
- Range from to
‘Range from to’ allows the creation of a new column from the range of values.
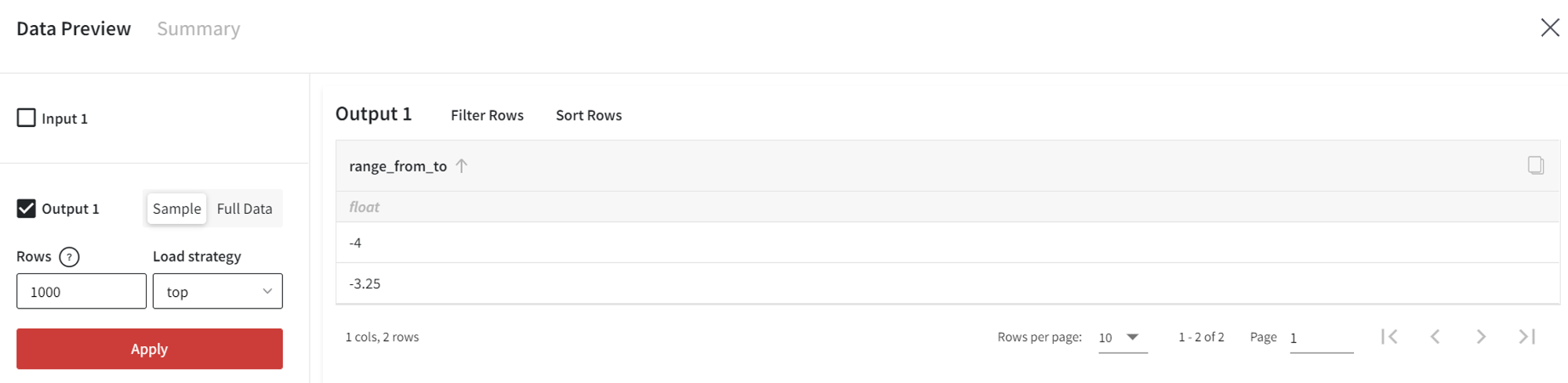
For instance, we can create a range from -4 to -3 with step 0.75.
- Random list
We need to specify the list of values to sample from (with replacement).
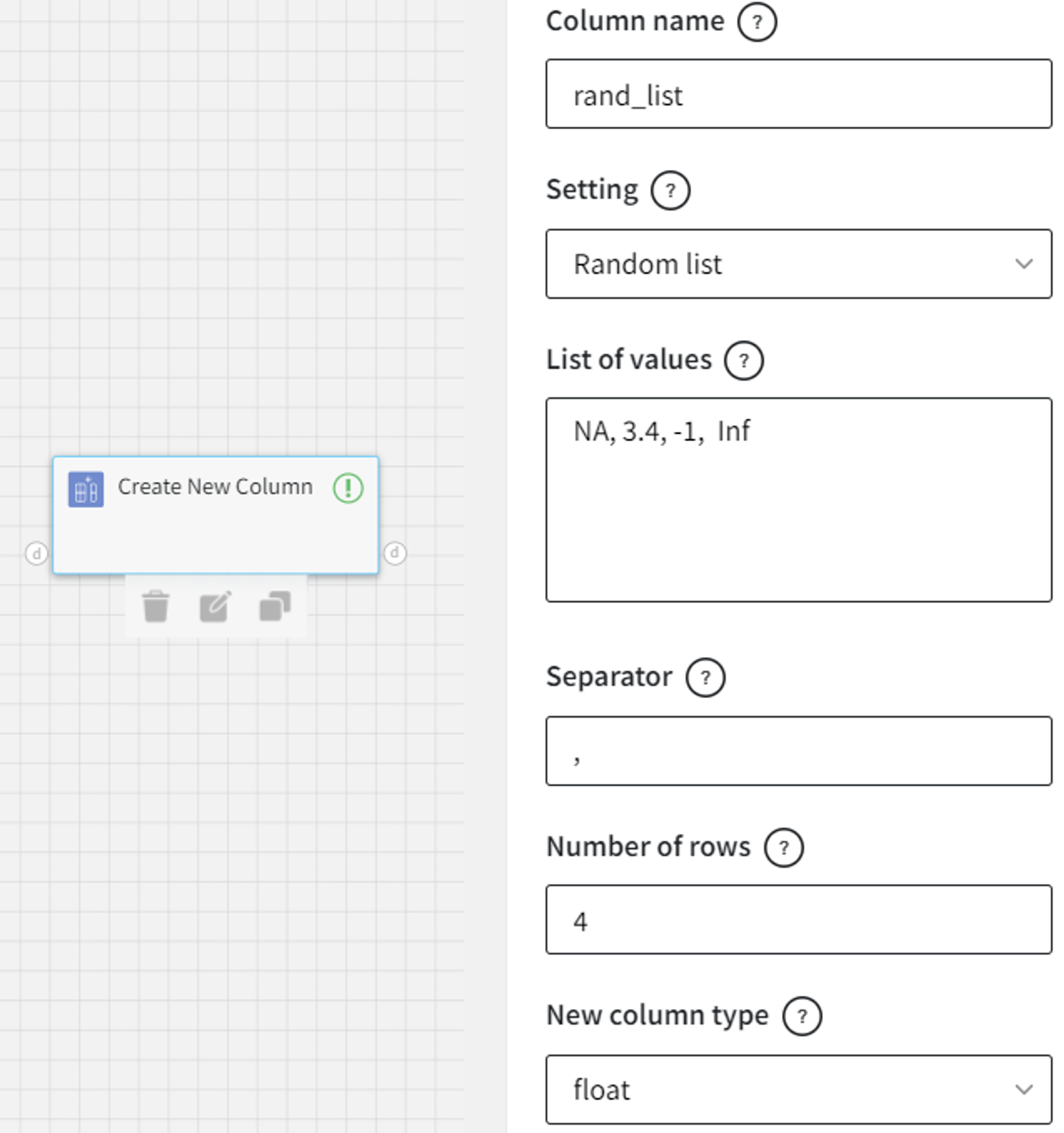
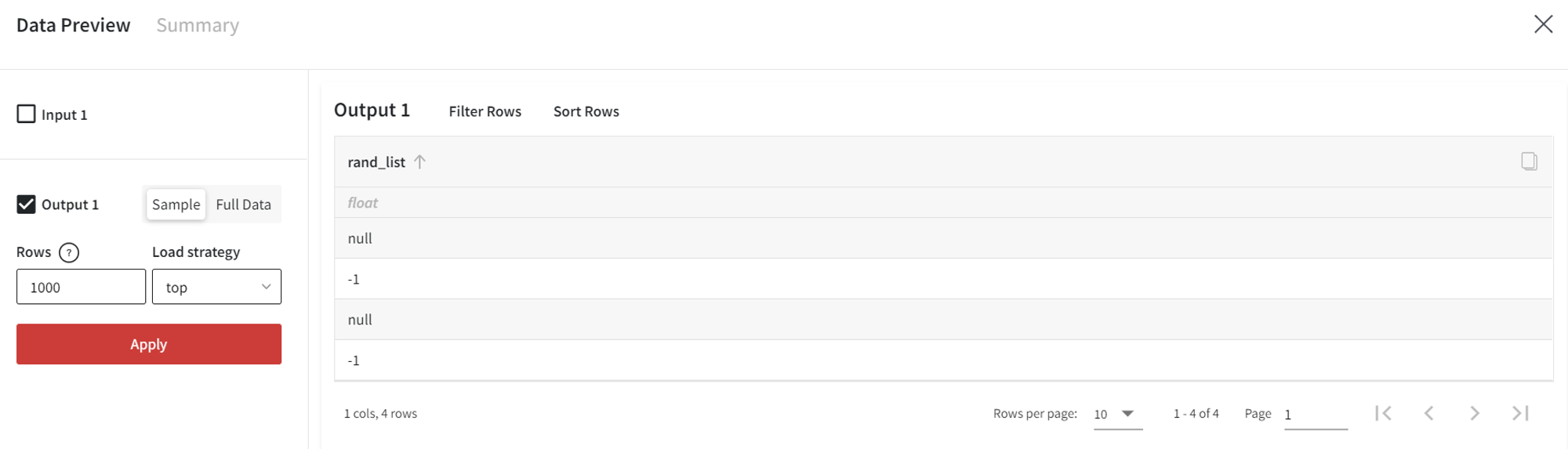
Such settings will create a column of size 4 with the float values from the given list.
NA and Inf, in this case, are nan and infinity correspondingly.
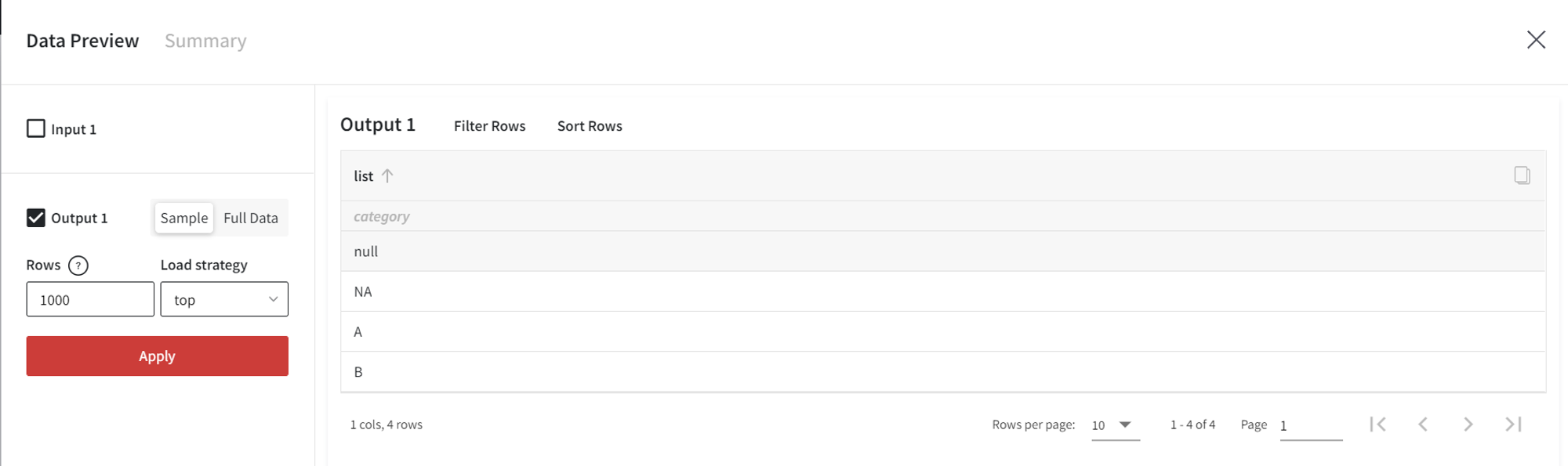
- List
In a similar way, we can create a new column with the list of values.
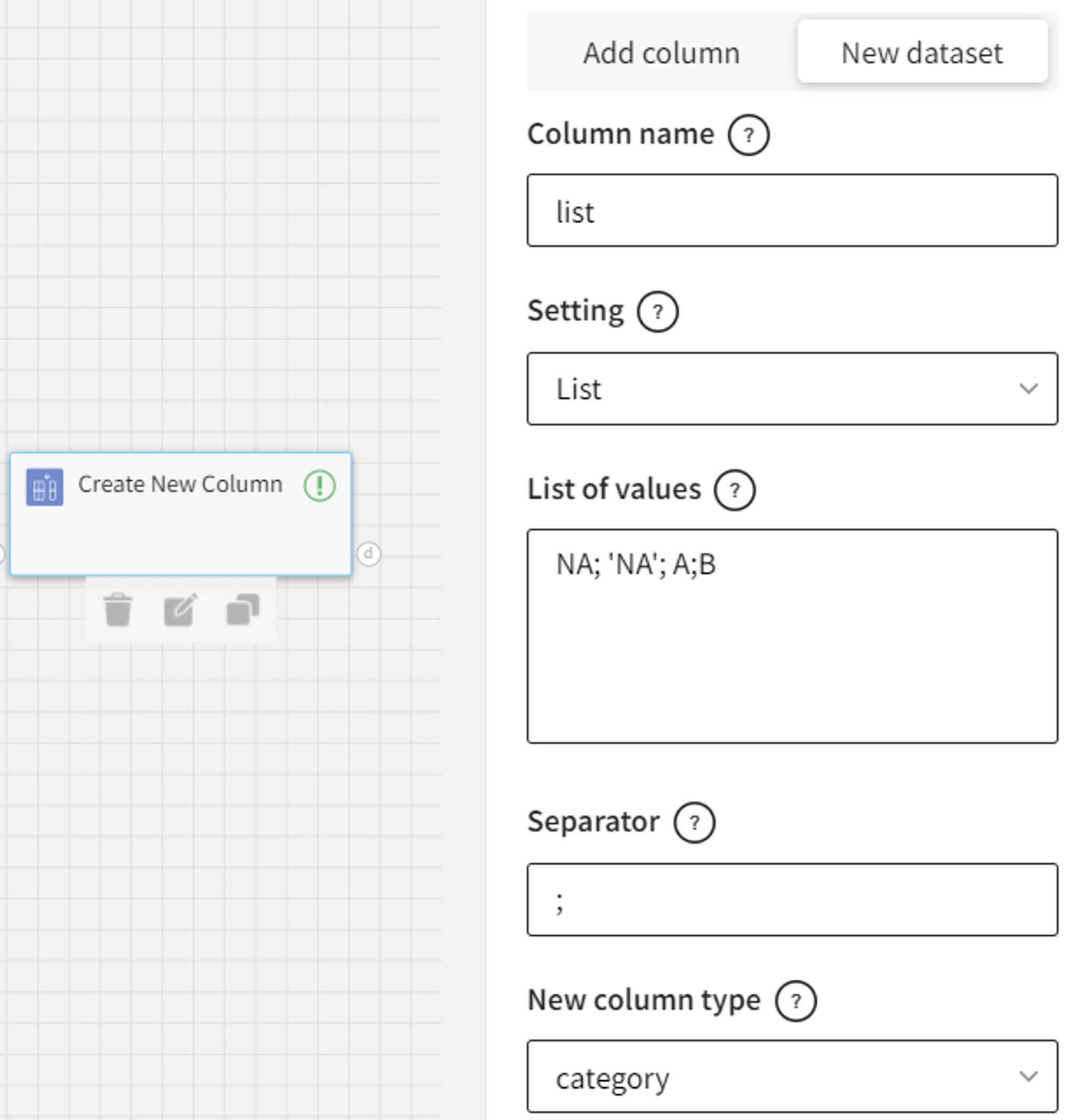
Here, NA is nan, and ‘NA’ is a string representation, so it must be successfully cast to categorical type.