Description
Pipeline for demonstration of the Datrics abilities to customize any intellectual data analysis solution via including bricks with custom code. The proposed solution can be used as a part of the Customer Support System - automatic detection of the customers' claims categories at the first-line support stage.
Problem Statement
Categorization of the customers' complaints received about financial products and services.
Dataset
Subsampling form Customer Complaints public dataset, which contains 3473 records with customers messages accompanied by corresponded topic of compline - product/service.
Data Description
Name
Tags
Complaint category, which should be recognised - 16 unique classes
Textual message that contains the detailed description of the customer complaint regarding specific product or service
Target Variable
- Product
Data Analysis Scenario
General Schema of the Customer Comments Categorization can be depicted in diagram:
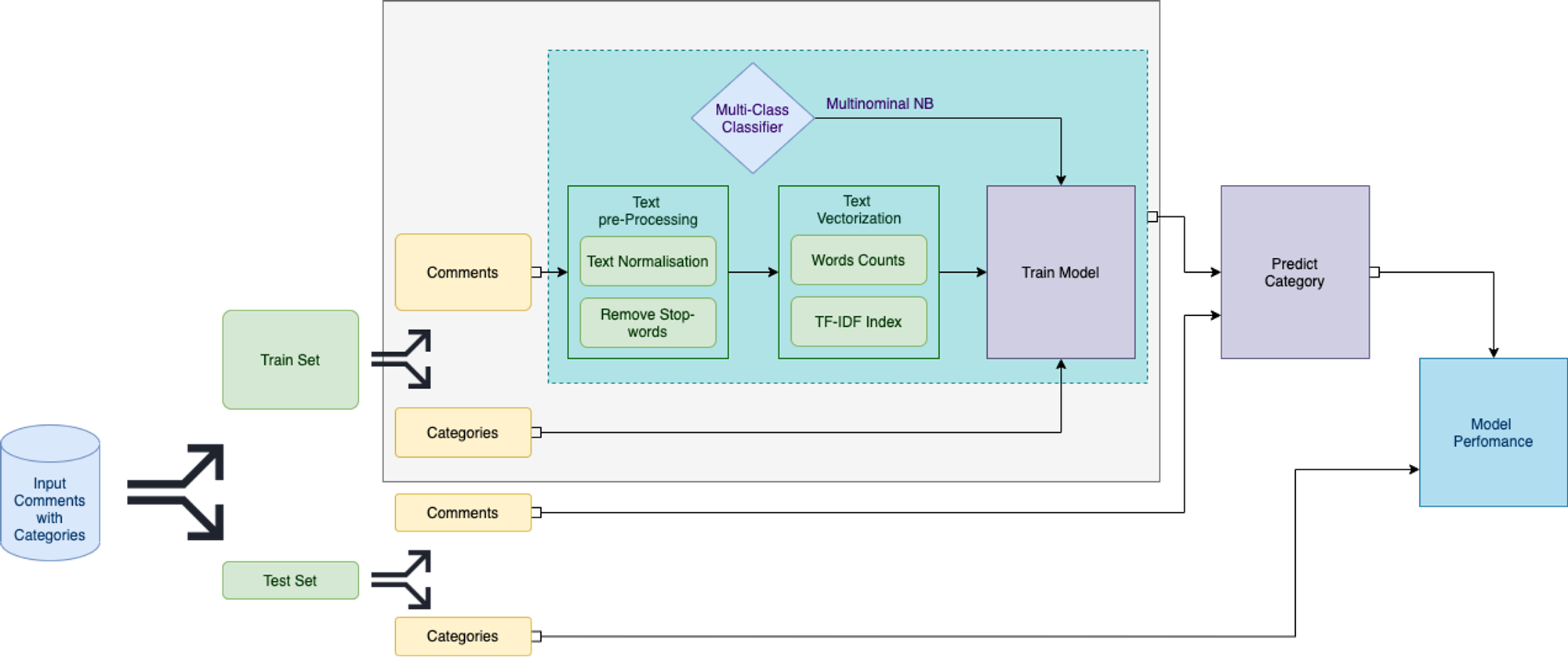
- All comments are divided into two subgroups with respect to the output classes distribution
- For the comments in the train set the Text processing pipeline is created:
- Text Cleansing and Normalisation
- Text Vectorizer (Words Count and TF-IDF index)
- Multiclass classifier (Multinomial Naive Bayes Classifier, that is appropriate for sparse data)
- Model Applying for new data (Test set)
- Model Perfomance Assessment
Datrics Pipeline
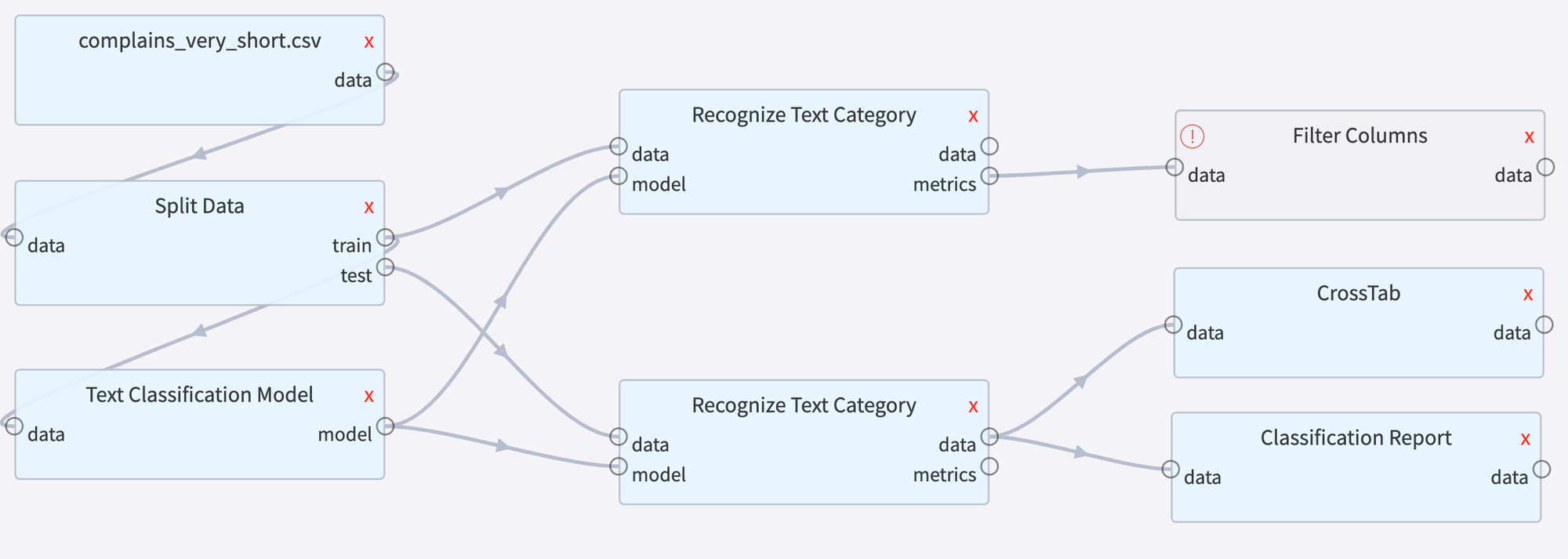
Datrics Custom Code Bricks
In order to implement the presented schema in Datrics we have prepared some custom bricks:
Text Classifier
Text Classification Pipeline- train Text Classification Pipeline, which includes countVectorizer, tfidfTransformer and Multinominal Naive Bayes Classifier.
Brick
Input
- Dataset with Comments (input)
- Categories (output)
Output
- Text Classification Pipeline (model)
Arguments
{"comments":"Consumer Complaint", "categories":"Product"}
Arguments Validation
def validate_args(self, args): import json def is_json(myjson): try: json_object = json.loads(myjson) except ValueError as e: return False return True if check_argument_exists(self.args, 'value', self.messages): if (not is_json(self.args['value'])) and (not self.args['value']=="\n"): self.messages.append("Incorrect format of arguments") return True else: return True return True
Inputs Validation
def validate_inputs(self): check_number_of_inputs(self, 1) if check_argument_exists(self.args, 'value', self.messages): if not self.args['value']=="\n": df = self.get_input_by_index(0).value if check_argument_exists(self.args, 'comments', self.messages): if self.args['comments'] not in df.columns: self.messages.append('Column '+self.args['comments']+" is absent") if check_argument_exists(self.args, 'categories', self.messages): if self.args['categories'] not in df.columns: self.messages.append('Column '+self.args['categories']+" is absent") return len(self.messages) == 0
Execution
def perform_execution(self, ctx: ExecutionContext): from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.naive_bayes import MultinomialNB from sklearn.utils.class_weight import compute_class_weight, compute_sample_weight from sklearn.metrics import classification_report from sklearn.pipeline import Pipeline try: df = self.get_input_by_index(0).value comments = df[self.args['comments']] categories = df[self.args['categories']] pipe = Pipeline([('vect',CountVectorizer(stop_words='english', ngram_range=(1,1))), ('tfidf', TfidfTransformer()), ('clf', MultinomialNB())]) sw = compute_sample_weight('balanced',categories) pipe.fit(comments, categories, clf__sample_weight=sw) pred = pipe.predict(comments) self.fill_outputs_by_type_with_value('model', pipe) self.status = BrickStatus.SUCCESS except: self.status = BrickStatus.FAILED self.messages.append("Can't train the model")
Recognize Text Category
RecognizeText Categories - recognize the categories of the provided comments.
Brick

Input
- Dataset with Comments (input)
- Categories (optional)
Output
- Dataset with predicted categories
- Metrics (if categories were provided)
Arguments
{"comments":"Consumer Complaint", "categories":"Product"} //Optional
Arguments Validation
def validate_args(self, args): import json def is_json(myjson): try: json_object = json.loads(myjson) except ValueError as e: return False return True if check_argument_exists(self.args, 'value', self.messages): if (not is_json(self.args['value'])) and (not self.args['value']=="\n"): self.messages.append("Incorrect format of arguments") return True else: return True return True
Inputs Validation
def validate_inputs(self): check_number_of_inputs(self, 2) if check_argument_exists(self.args, 'value', self.messages): if not self.args['value']=="\n": df = self.get_input_by_type('data').value if check_argument_exists(self.args, 'comments', self.messages): if self.args['comments'] not in df.columns: self.messages.append('Column '+self.args['comments']+" is absent") if check_argument_exists(self.args, 'categories', None): if self.args['categories'] not in df.columns: self.messages.append('Column '+self.args['categories']+" is absent") return len(self.messages) == 0
Execution
def perform_execution(self, ctx: ExecutionContext): from sklearn.metrics import classification_report try: df = self.get_input_by_type('data').value pipe = self.get_input_by_type('model').value comments = df[self.args['comments']] if check_argument_exists(self.args, 'categories', None): categories = df[self.args['categories']] pred = pipe.predict(comments) if check_argument_exists(self.args, 'categories', None): metrics = classification_report(categories, pred, output_dict=True) metrics = pandas.DataFrame(metrics) metrics = metrics.transpose() metrics = metrics.reset_index() df['predicted_category'] = pred self.fill_outputs_by_name_with_value('data', df) if check_argument_exists(self.args, 'categories', None): self.fill_outputs_by_name_with_value('metrics', metrics) self.status = BrickStatus.SUCCESS except: self.status = BrickStatus.FAILED self.messages.append("Can't make a prediction")
CrossTab
Cross Tabulation - simple cross-tabulation of two factors
Brick
Input
- Dateset with expected and recognised categories
Output
- Cross-tabulation matrix
Arguments
{"X":"Product", "Y":"predicted_category"}
Arguments Validation
def validate_args(self, args): import json def is_json(myjson): try: json_object = json.loads(myjson) except ValueError as e: return False return True if check_argument_exists(self.args, 'value', self.messages): if (not is_json(self.args['value'])) and (not self.args['value']=="\n"): self.messages.append("Incorrect format of arguments") return True else: return True return True
Inputs Validation
def validate_inputs(self): check_number_of_inputs(self, 1) if check_argument_exists(self.args, 'value', None): if not self.args['value']=="\n": df = self.get_input_by_index(0).value if check_argument_exists(self.args, 'X', self.messages): if self.args['X'] not in df.columns: self.messages.append('Column '+self.args['X']+" is absent") if check_argument_exists(self.args, 'Y', self.messages): if self.args['Y'] not in df.columns: self.messages.append('Column '+self.args['Y']+" is absent") return len(self.messages) == 0
Execution
def perform_execution(self, ctx: ExecutionContext): try: df = self.get_input_by_index(0).value X = df[self.args['X']] Y = df[self.args['Y']] res = pandas.crosstab(X,Y) res = res.reset_index() self.fill_outputs_by_type_with_value('data', res) self.status = BrickStatus.SUCCESS except: self.status = BrickStatus.FAILED
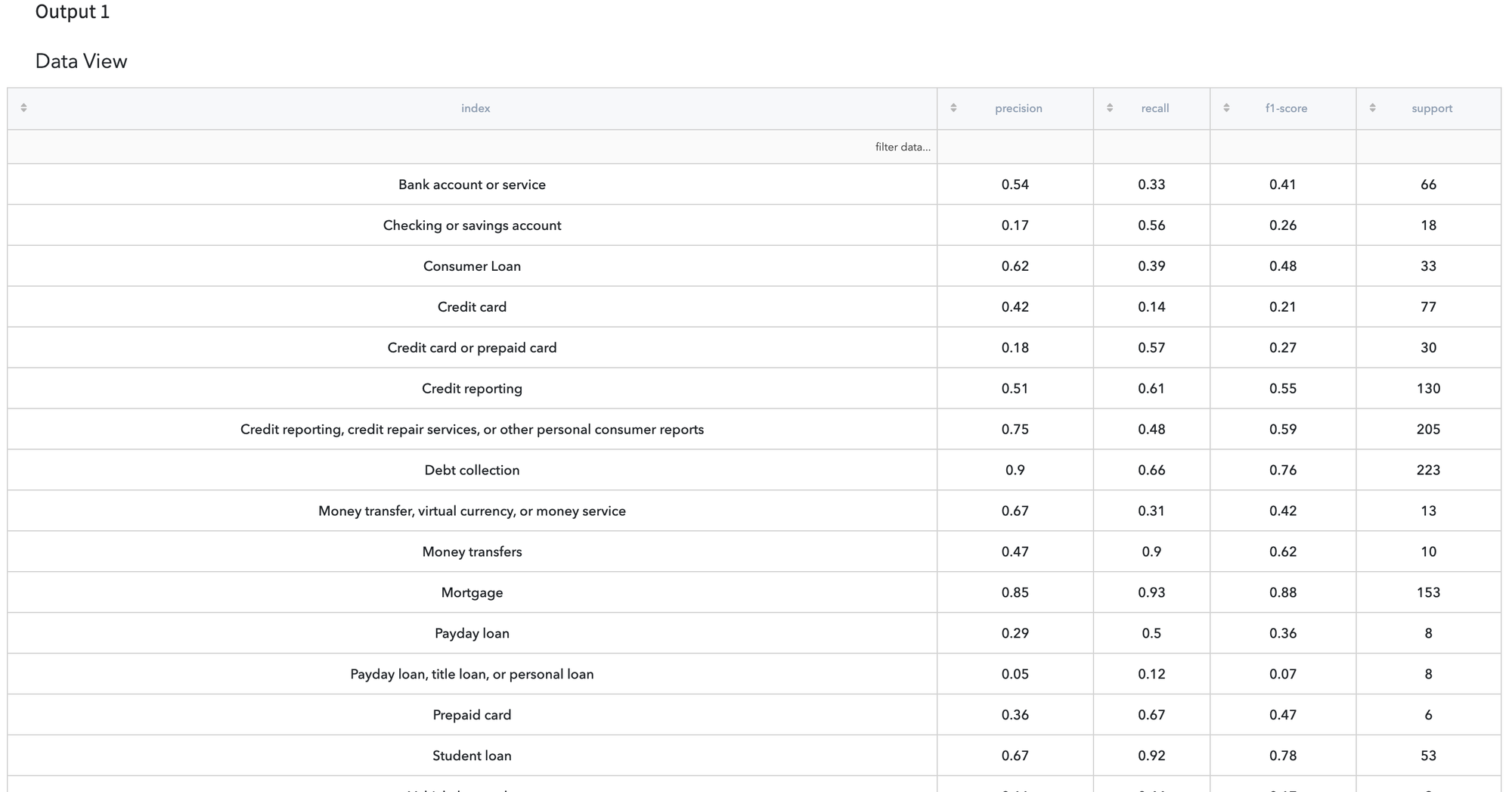
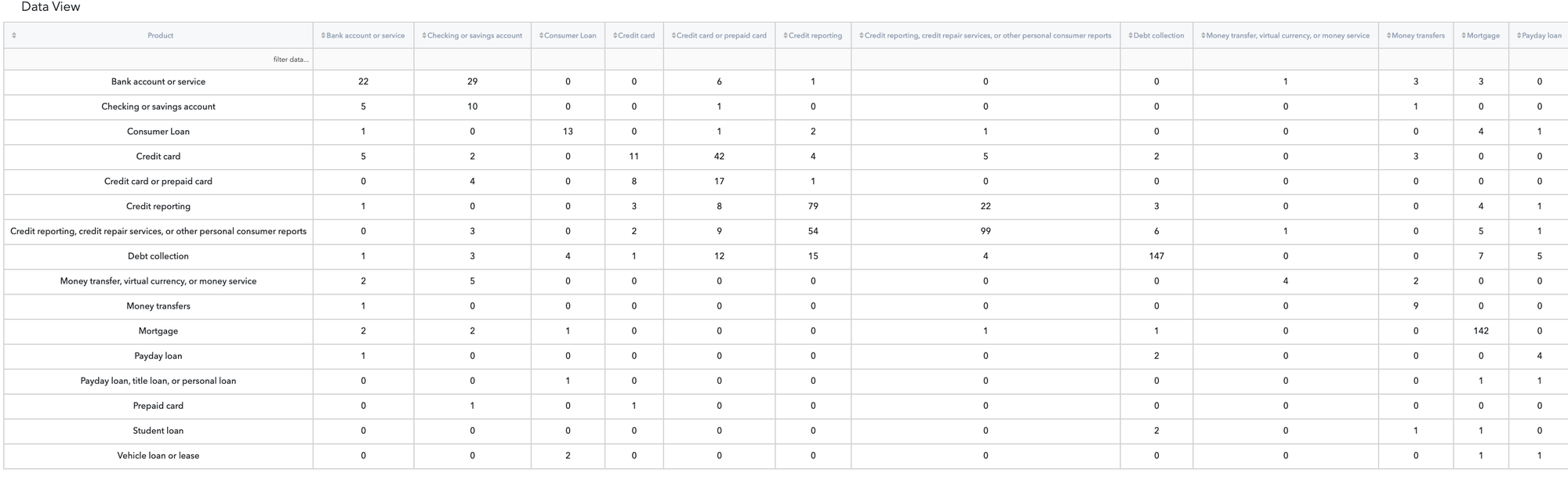
Output View
Classification Report
Classification Report - table with classification metrics for each class - precision, recall, f1-score and accuracy.
Brick
Input
- Dateset with expected and recognised categories
Output
- Classification report table
Arguments
{"X":"Product", "Y":"predicted_category"}
Arguments Validation
def validate_args(self, args): import json def is_json(myjson): try: json_object = json.loads(myjson) except ValueError as e: return False return True if check_argument_exists(self.args, 'value', self.messages): if (not is_json(self.args['value'])) and (not self.args['value']=="\n"): self.messages.append("Incorrect format of arguments") return True else: return True return True
Inputs Validation
def validate_inputs(self): check_number_of_inputs(self, 1) if check_argument_exists(self.args, 'value', None): if not self.args['value']=="\n": df = self.get_input_by_index(0).value if check_argument_exists(self.args, 'X', self.messages): if self.args['X'] not in df.columns: self.messages.append('Column '+self.args['X']+" is absent") if check_argument_exists(self.args, 'Y', self.messages): if self.args['Y'] not in df.columns: self.messages.append('Column '+self.args['Y']+" is absent") return len(self.messages) == 0
Execution
def perform_execution(self, ctx: ExecutionContext): from sklearn.metrics import classification_report, accuracy_score, f1_score try: df = self.get_input_by_index(0).value X = df[self.args['X']] Y = df[self.args['Y']] metrics = classification_report(X, Y, output_dict=True) metrics = pandas.DataFrame(metrics) metrics = metrics.transpose() metrics = metrics.reset_index() self.fill_outputs_by_type_with_value('data', metrics) self.status = BrickStatus.SUCCESS except: self.status = BrickStatus.FAILED
Output View