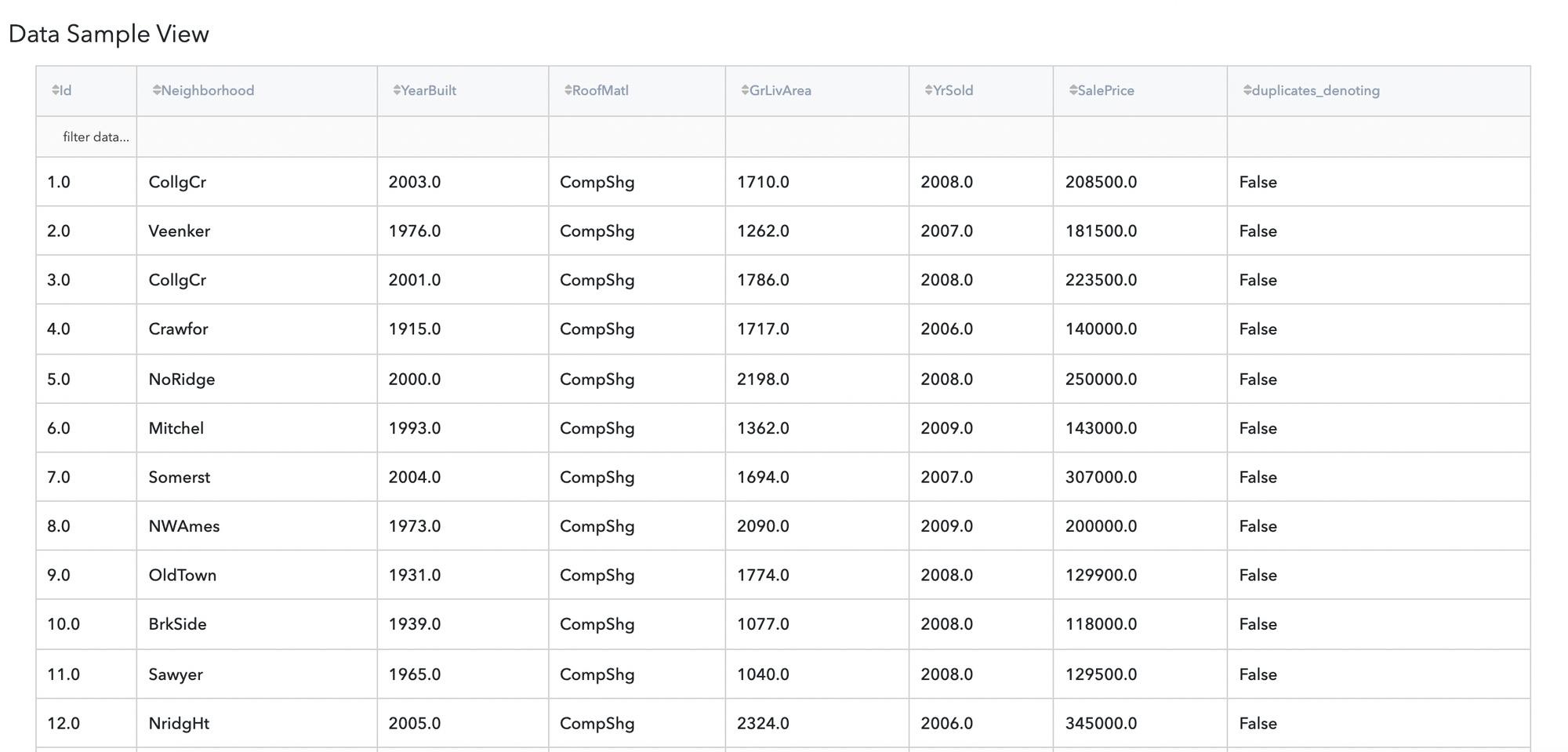
General information
Brick provides a possibility to inspect or remove duplicated rows.
Description
Brick Locations
Bricks → Analytics → Duplicates Treatment
Brick Parameters
- Outcome
- Select Duplicates which select rows which are duplicates.
- Denote Duplicates add an additional boolean column duplicates_denoting that emphasize duplicates.
- Remove Duplicates remove duplicated rows from dataset with a chosen strategy
Specifies dataset type to be returned. Few options available here:
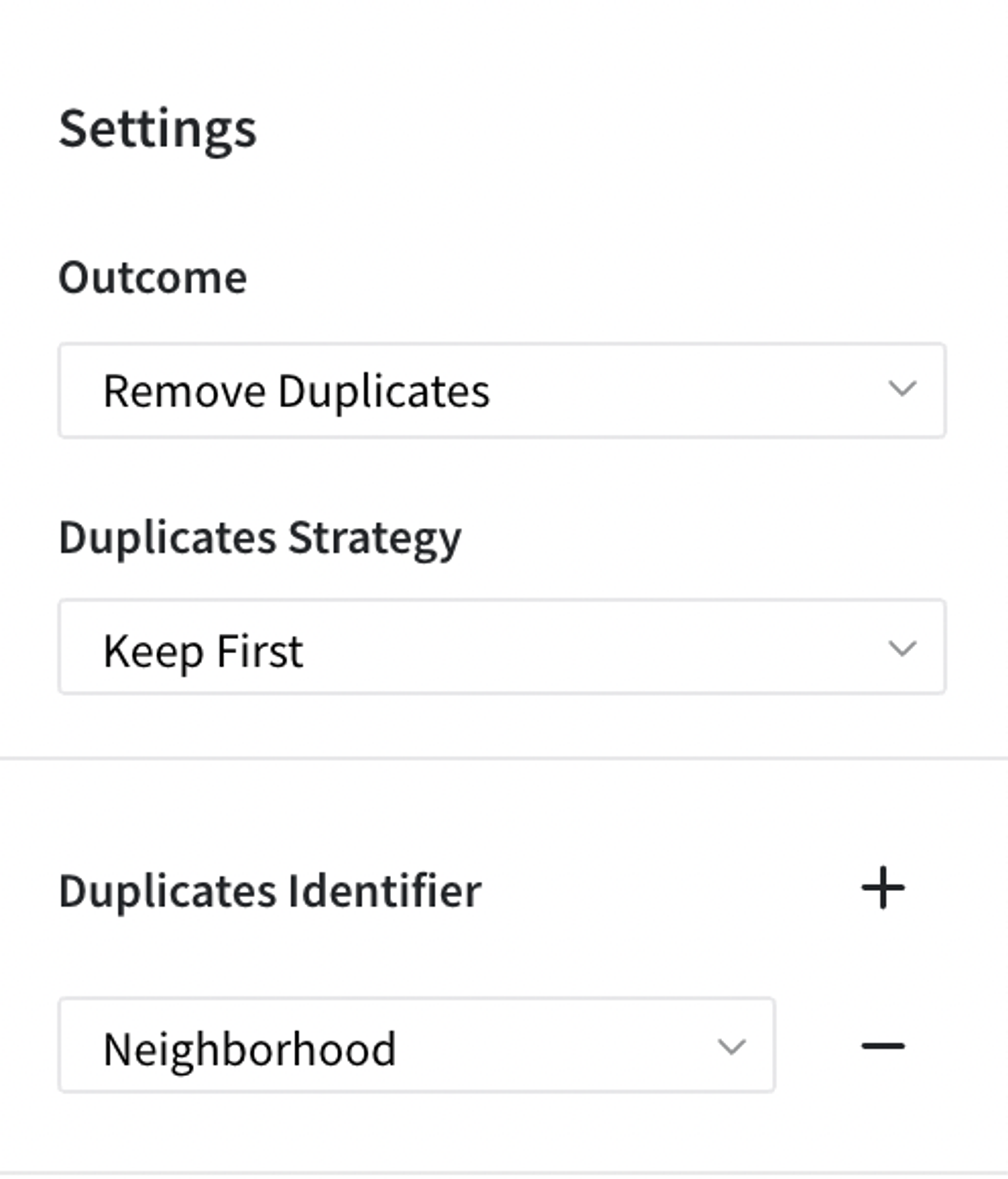
- Remove Duplicates Strategy
- Keep First - first row from the duplicated ones would be kept
- Keep Last - last row from the duplicated ones would be kept
- Remove All - all duplicated rows would be removed
Only available for the output type "Remove Duplicates".
Specifies the strategy that would be applied to delete duplicated rows. Few options are available here:
- Duplicates Identifier
A column that would be used as a unique key. It is possible to choose several columns by clicking on the '+' button in the brick settings or fewer columns by clicking on the “-” button. At least one column should be specified.
Brick Inputs/Outputs
- Inputs
Brick takes the dataset.
- Outputs
Brick produces the result as a new dataset, with an additional column duplicates_denoting in the case of outcome Denote Duplicates.
Example of usage
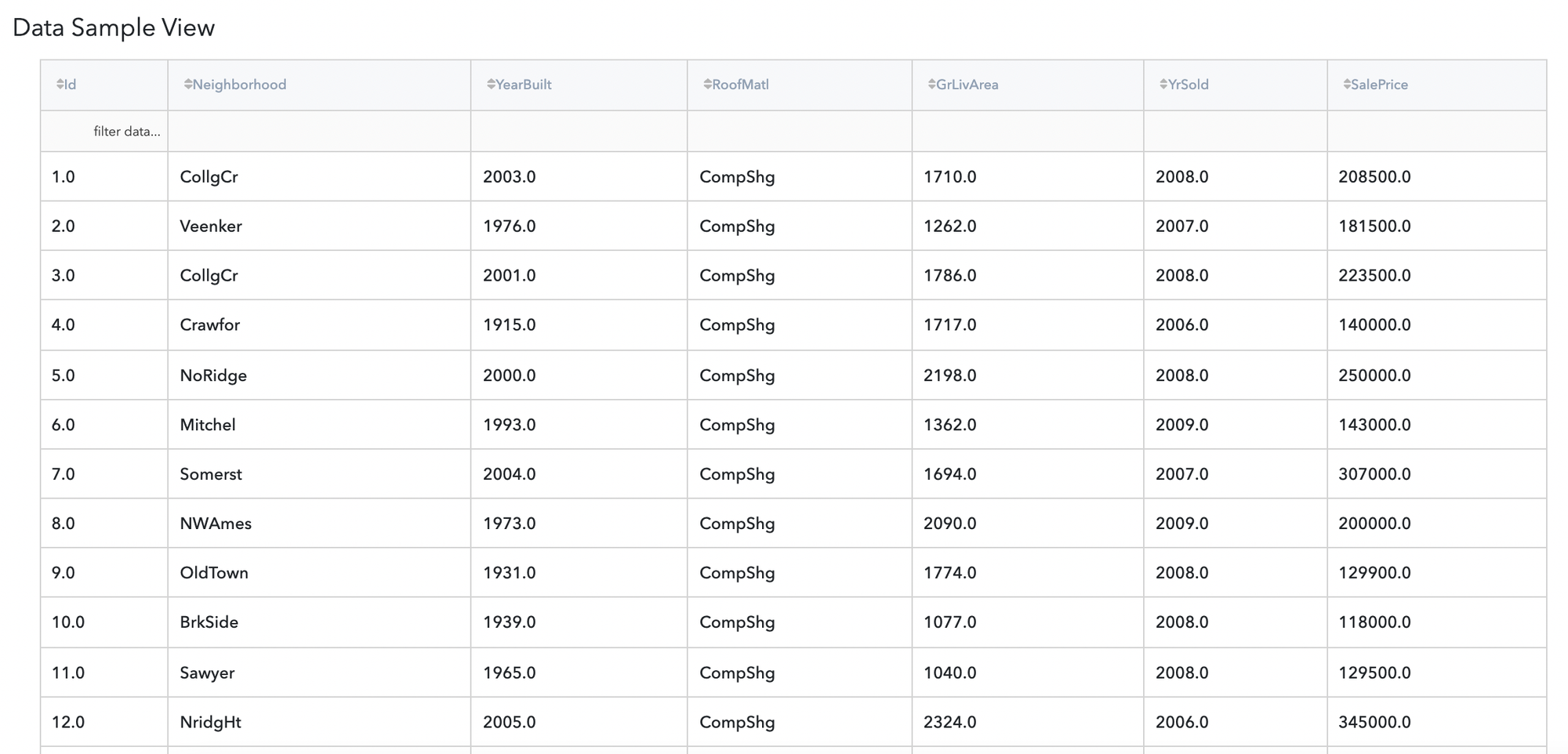
Let’s assume we have data about house prices dataset. It consists of many columns, they are:
- id (category) - unique id of house
- Neighbourhood (string) - name of region where house take place
- YearBuilt (int) - year when house was built
- RoofMatl (string)
- GrLivArea (float) - house living area
- YrSold (int) - year when house was sold
- SalePrice (float) - house price
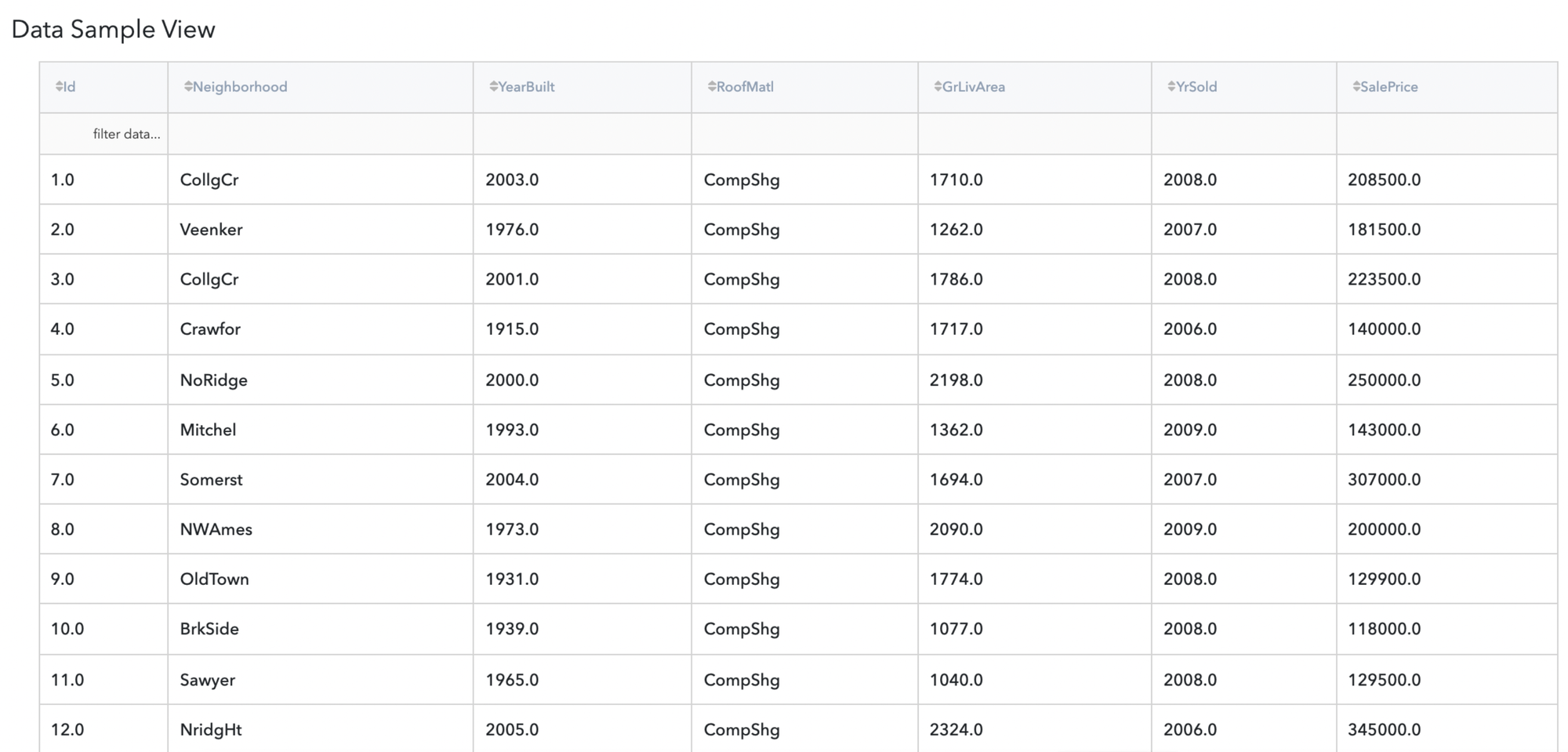
Firstly we want to perform Remove Duplicates option of the Brick, so we choose a column we want to perform duplicates removal in our case it is for example Neighbourhood and we take Keep First option.
Let’s move to result:
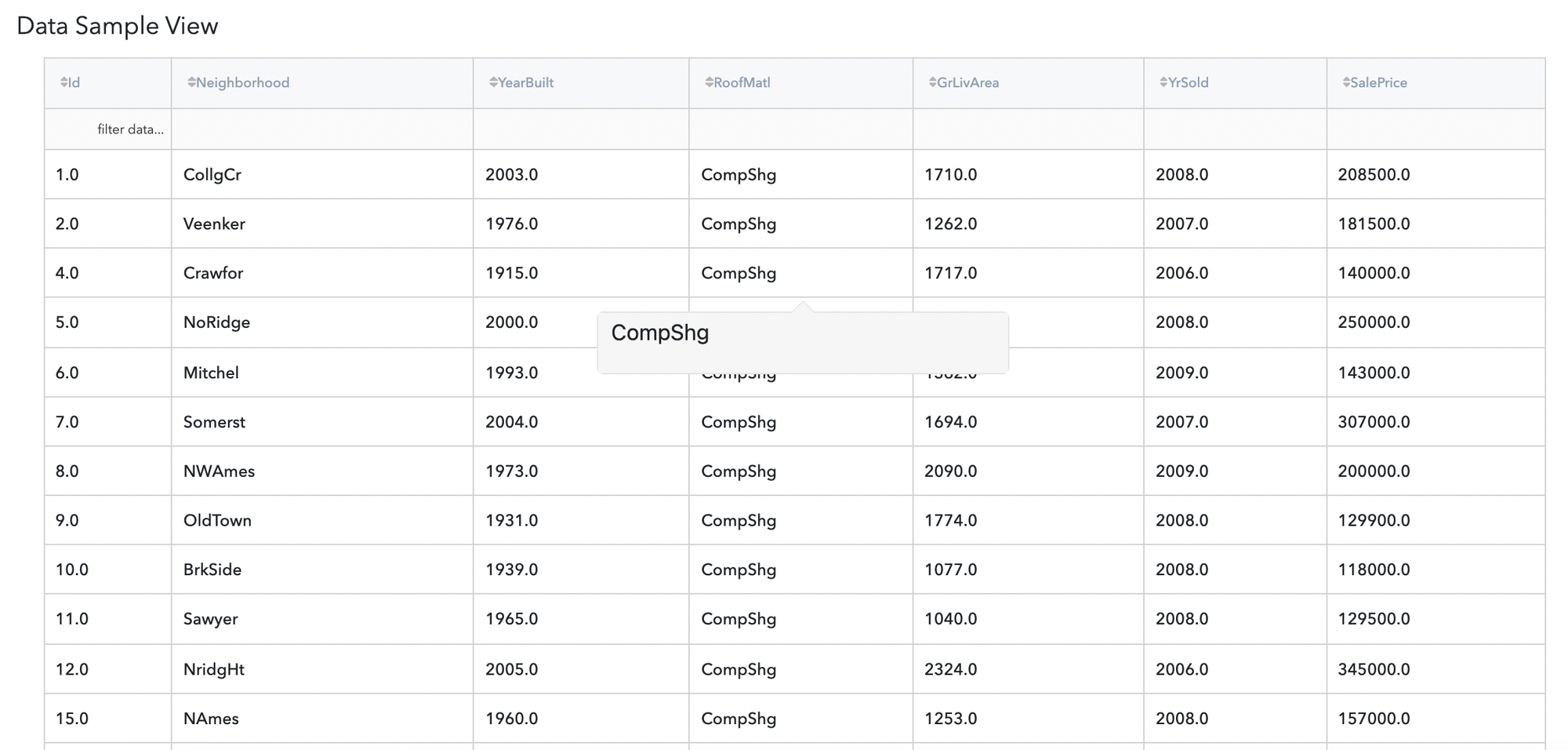
Secondly let’s try option where we would select duplicates on column Neigbourhood
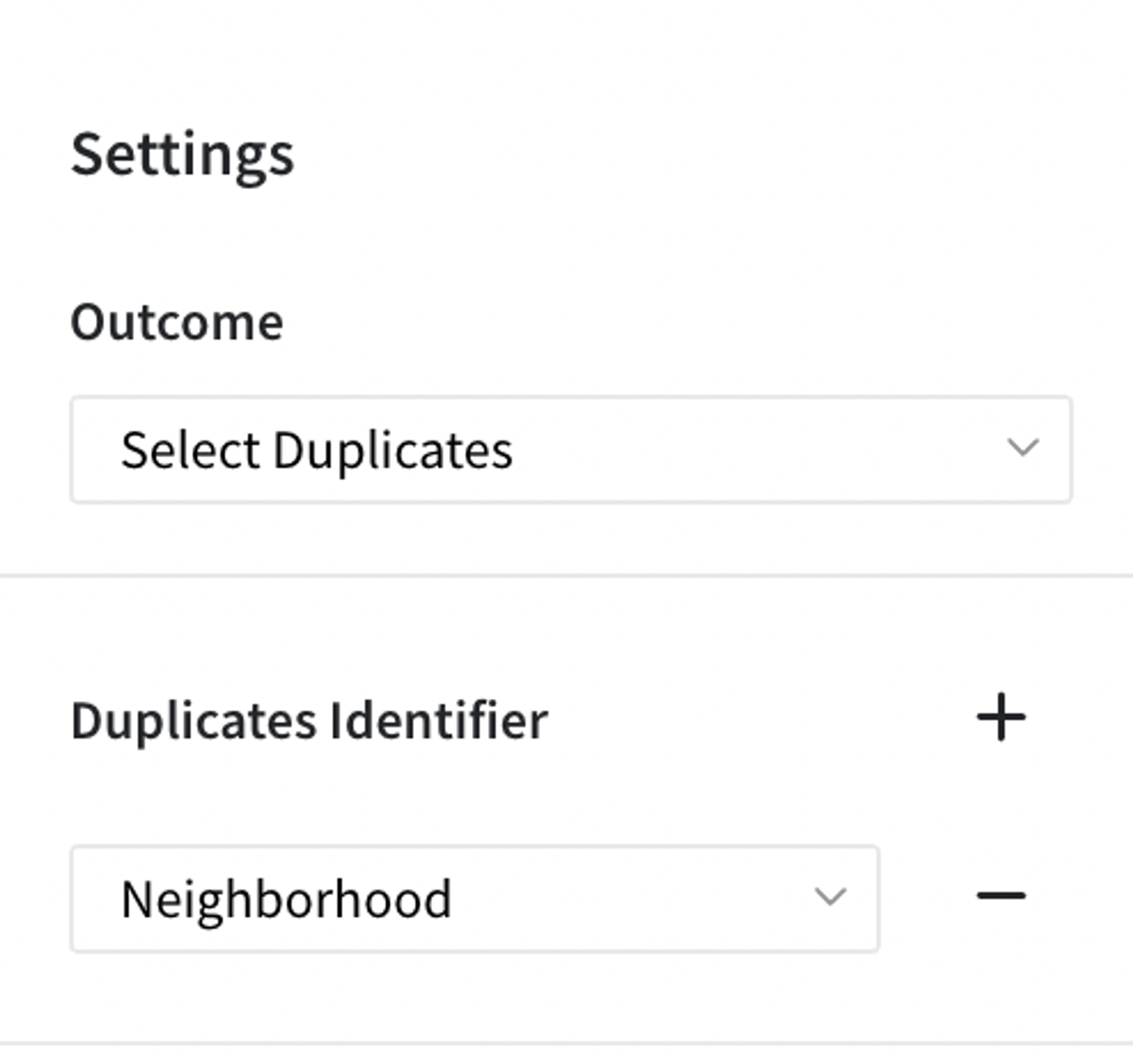
The result is the same as an dataset on input, it’s because all rows are duplicates of other rows in column Neigbourhood:
Thirdly, let’s move to the option of Denote Duplicates, there for instance we will take id column to show the difference.
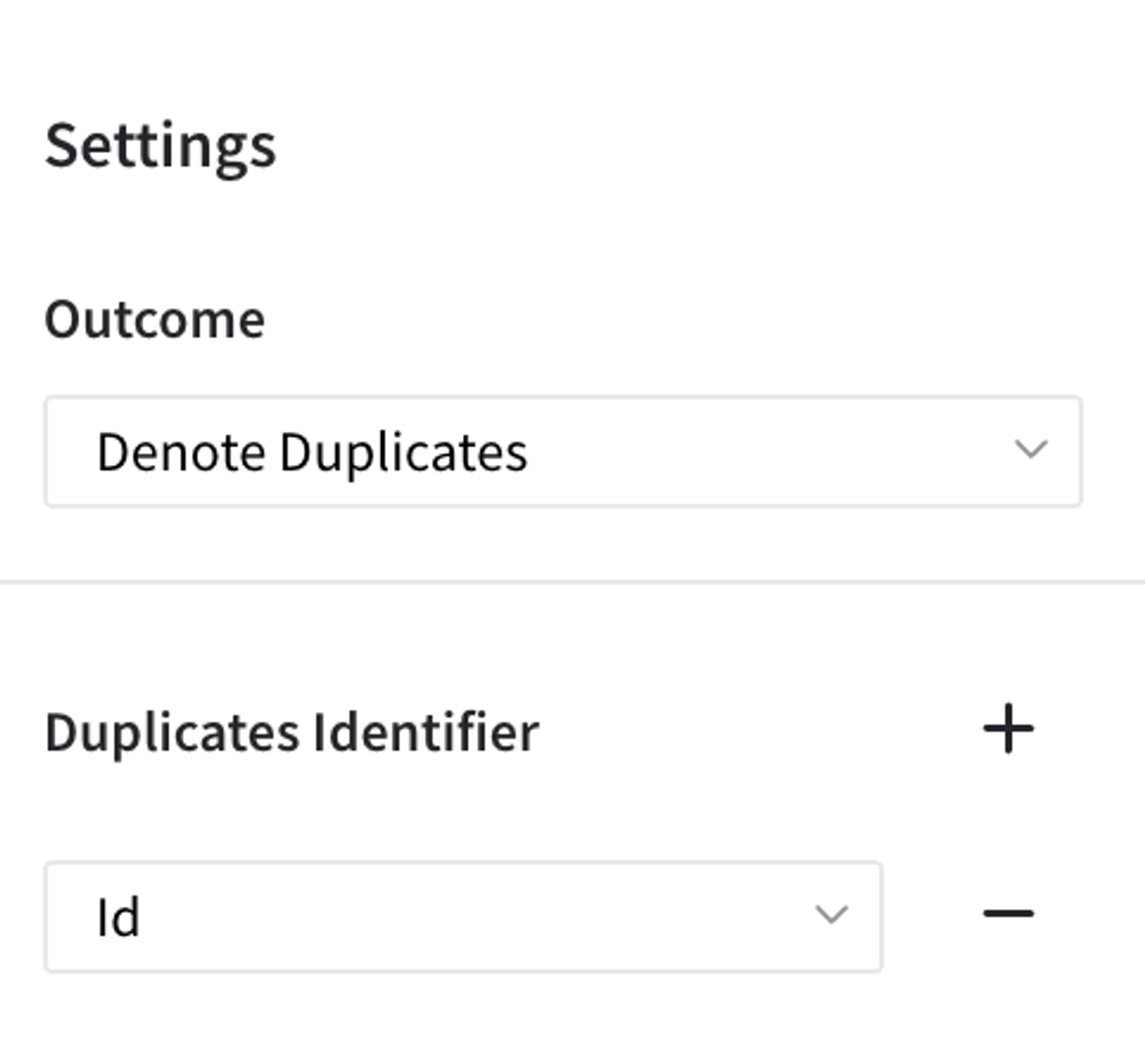
The result is straightforward because all values of column id are unique: