Data connectors to AWS S3 and Google cloud storage to retrieve csv and parquet files. To retrieve the data - create a data source, create the dataset, and add it to your pipeline.
Datrics updates the data from the files stored in the folder in the cloud storage on each pipeline run. User may specify to load the files from the specified folder/file path, or define the dynamic list of path/s using python code.
Create data source
There are two options to create a data source.
- In the dataset tab in the group or project
- In the dataset creation section on the scene
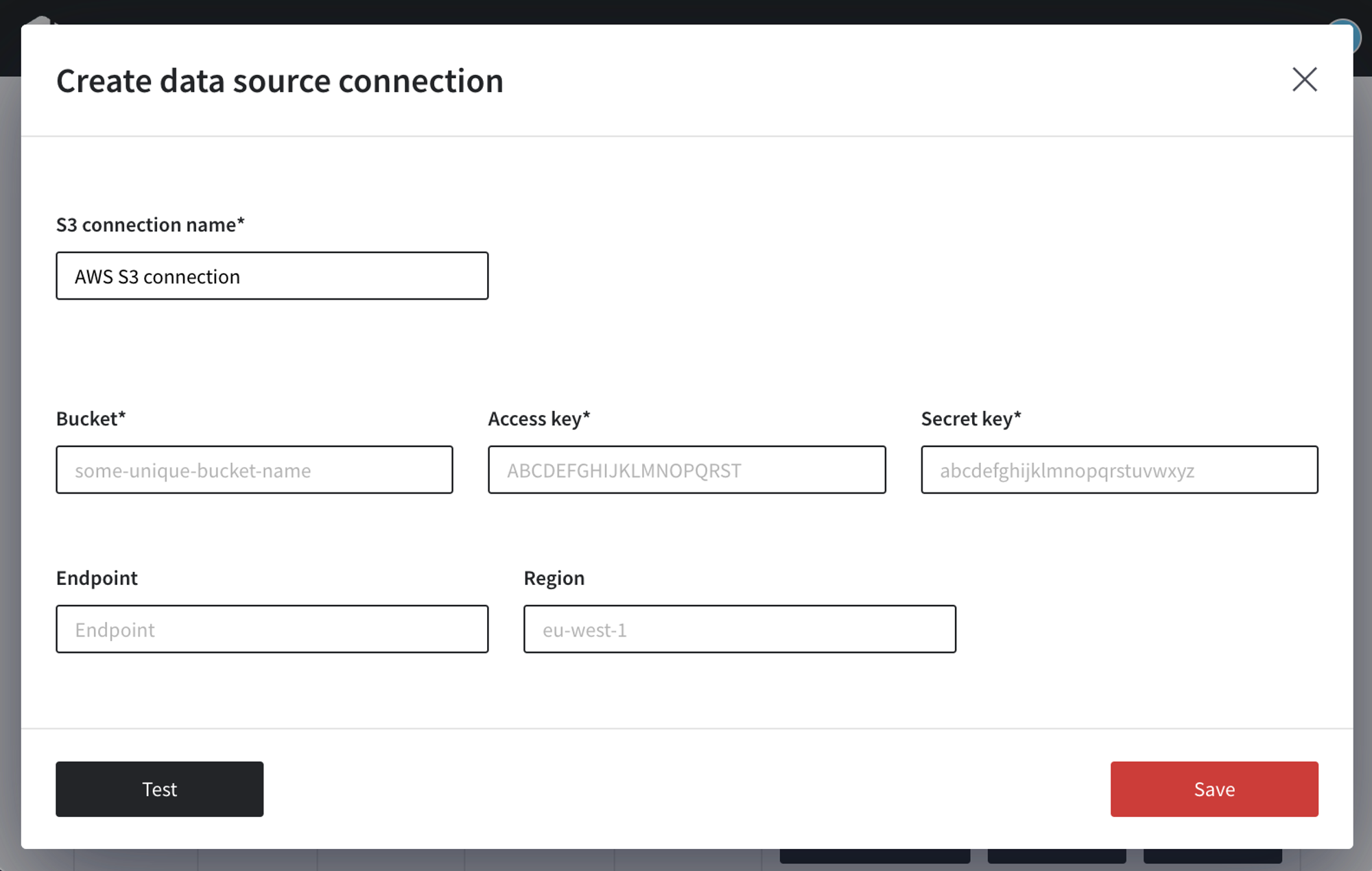
- Select the object storage from the lost of connectors - AWS S3 or Google CS

- Enter credentials to connect to your bucket, test the connection and save the datasource.
Create dataset with the data from files stored in the cloud storage
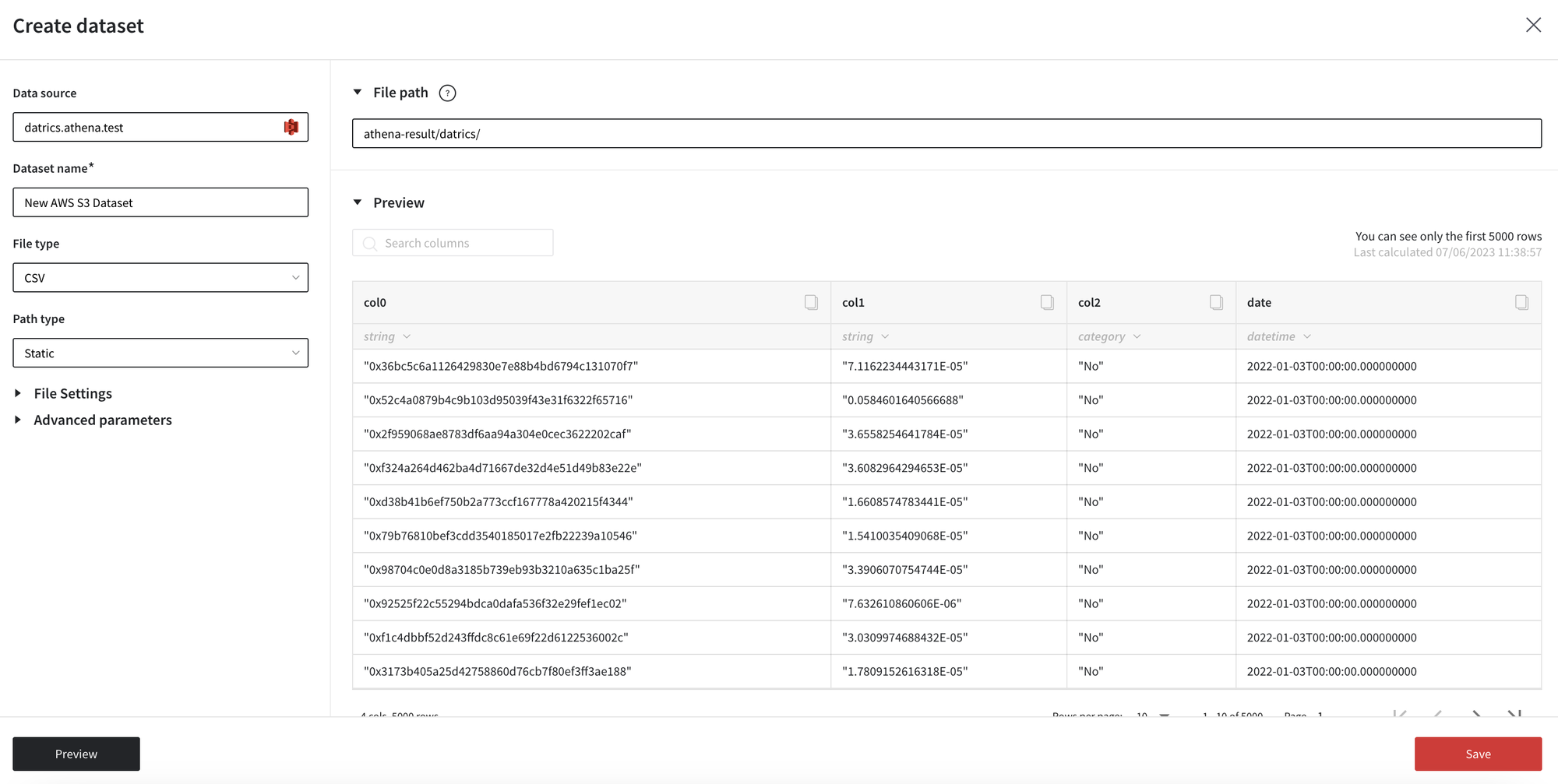
- Select the created data source to upload the data. Specify the dataset name
- Select the file type you would like to upload
- Set up the file path
There are two options to define the file path: static and dynamic.
In Static mode, you may define the direct path to the file or folder in the bucket.
- If you specify a direct file path, then only 1 file is uploaded.
- If you specify a path to the folder, then all files of the selected file will be combined into one dataset. CSV files should be of the same structure. Please note, that files from the subfolder will not be loaded.
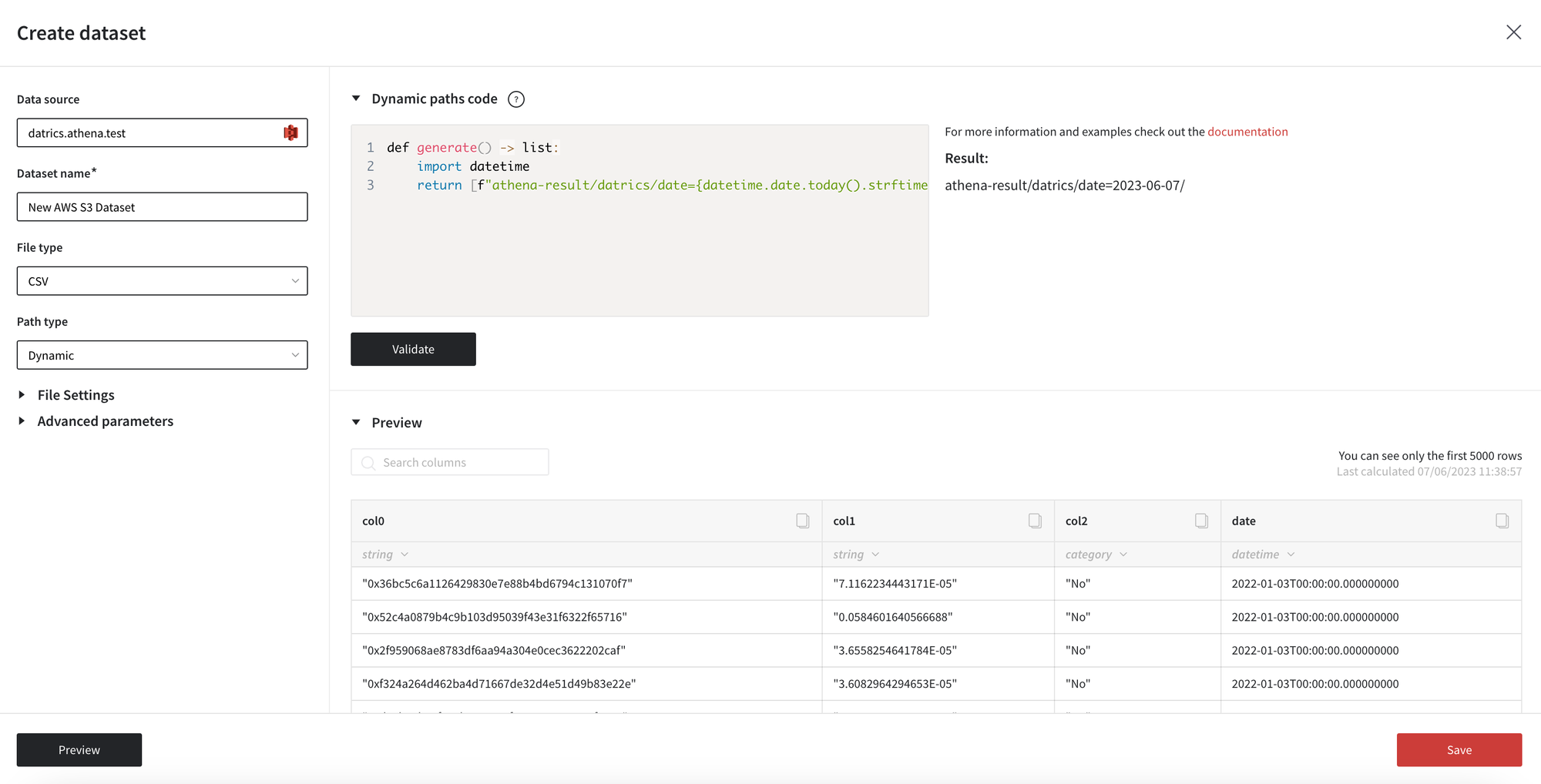
In Dynamic mode, you may define the set of files or folders using python code. For example, when you need to retrieve the file from the folder with today’s date in the name, you may do that with the line of code. In this case, in the pipeline the each day new file will be retrieved.
Validate the code to check that the list of file/folder paths are generated as expected.
Examples of the python code to define dynamic paths to folders:
- List of the folders with the specified dates in the name. Result: path/date=2023-01-04/, path/date=2023-01-03/, path/date=2023-01-02/
def generate() -> list: return ["path/date=2023-01-04/", "path/date=2023-01-03/", "path/date=2023-01-02/"]
- Path to the folder with the current data in the folder name. Result: path/date=2023-06-07/
def generate() -> list: import datetime return [f"path/date={datetime.date.today().strftime('%Y-%m-%d')}/"]
- List of folder paths for the date range. Result of the code below: path/date=2023-06-07/, path/date=2023-06-06/, path/date=2023-06-05/
def generate() -> list: import datetime dates = [(datetime.date.today() - datetime.timedelta(days=x)).strftime('%Y-%m-%d') + "/" for x in range(0, 3)] dates_formatted = [f"path/date={d}" for d in dates] return dates_formatted
Using object storage dataset in the pipeline
Add the dataset to the pipeline from the list of datasets.