General information
Joins two datasets into one based on the related column similarly to SQL ‘Join’ command.
Description
Brick Locations
Bricks → Data Manipulation → Join Data
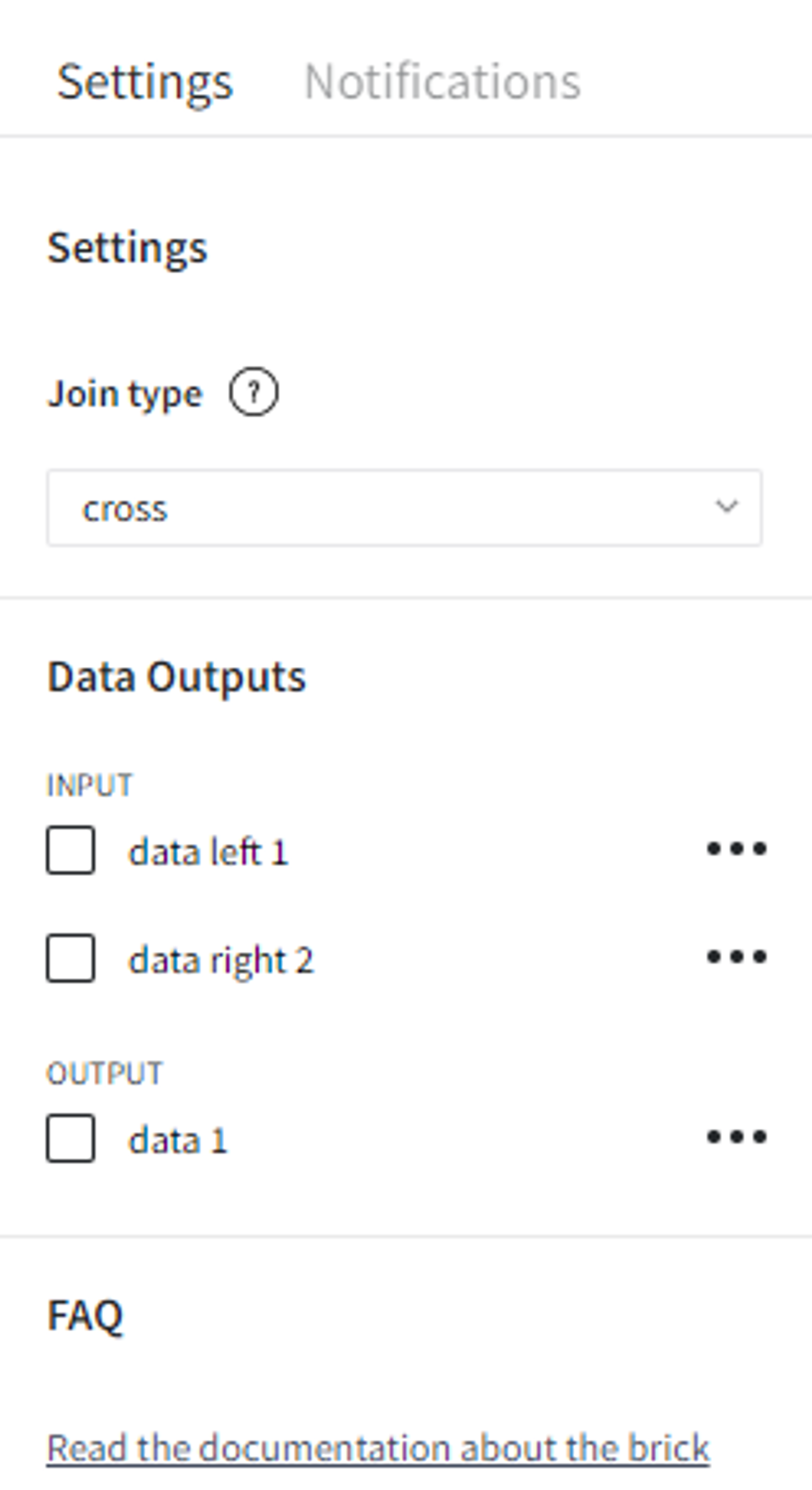
Brick Parameters
- Join type
- inner (returns records that match in both sets) (by default)
- left (returns all the records from the left set with corresponding matches from the right set)
- right (returns all the records from the right set with corresponding matches from the left set)
- outer (returns all the records from both sets with corresponding matches)
- cross (returns the Cartesian product of two sets)
You can select one of the following join operators:
For left, right, and outer join, if there is no match, the attributes are filled with ‘nan’.
- Join columns left
Columns from the first (left) dataset that are used for matching. Multiple columns can be selected by clicking the + button.
Not available for ‘cross’ join.
- Join columns right
Columns from the second (right) dataset that are used for matching. Multiple columns can be selected by clicking the + button.
Not available for ‘cross’ join.
It’s important that the number of left columns is exactly the same as the number of right columns, otherwise, you will end up with an error.
Brick Inputs/Outputs
- Inputs
Brick takes two datasets
- Outputs
Brick produces the horizontally joint dataset by the specific shared column.
Example of usage
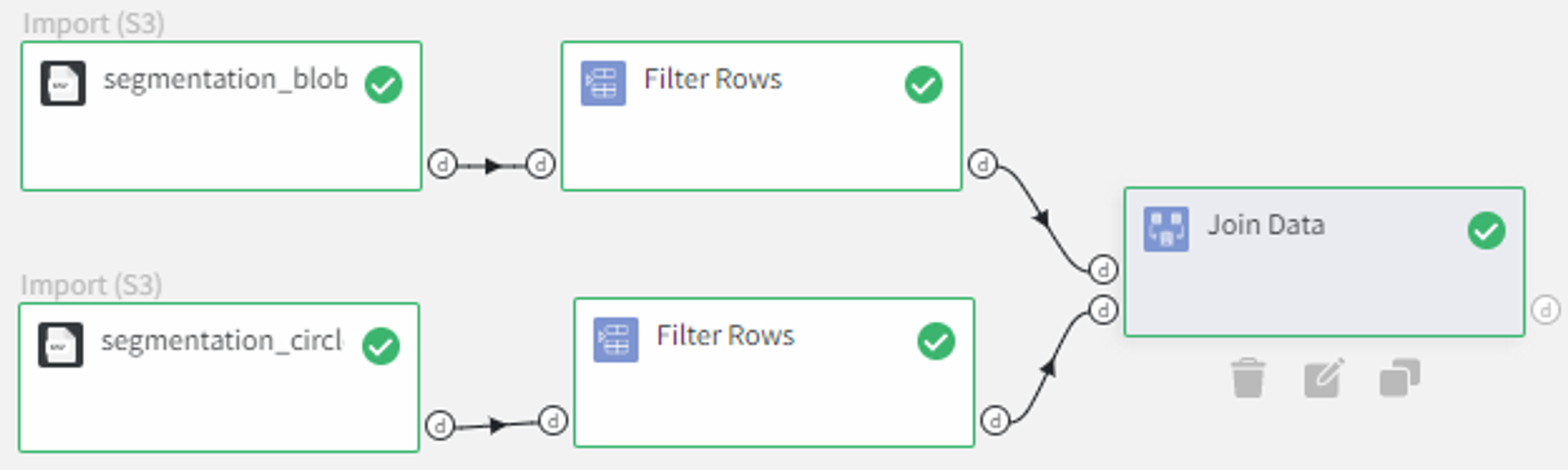
Let’s have a look at how the Join Data Brick can join two datasets into one.
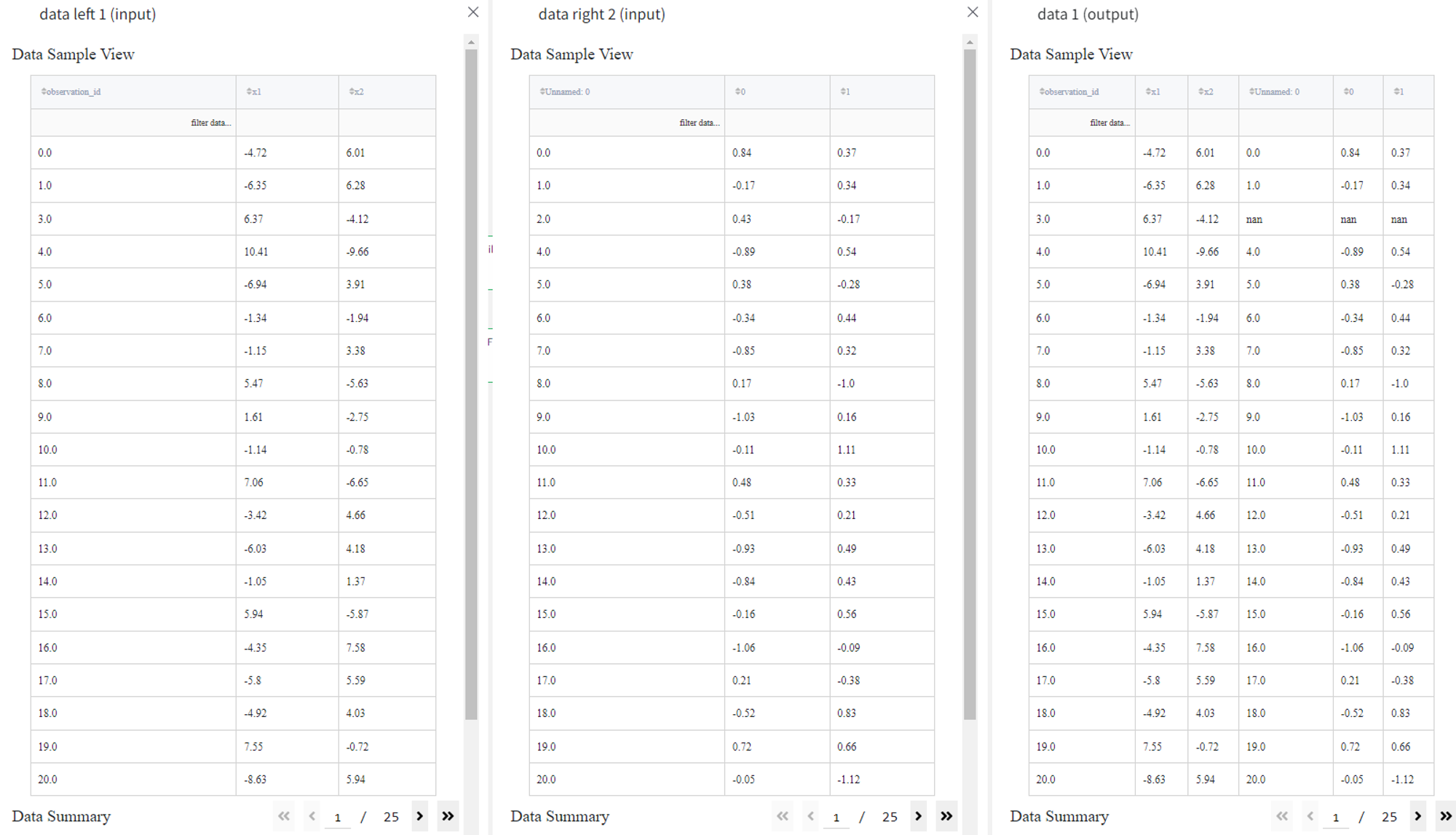
In this example, we will try to join ‘segmentation_blobs.csv’ and ‘segmentation_circles.csv’ datasets.
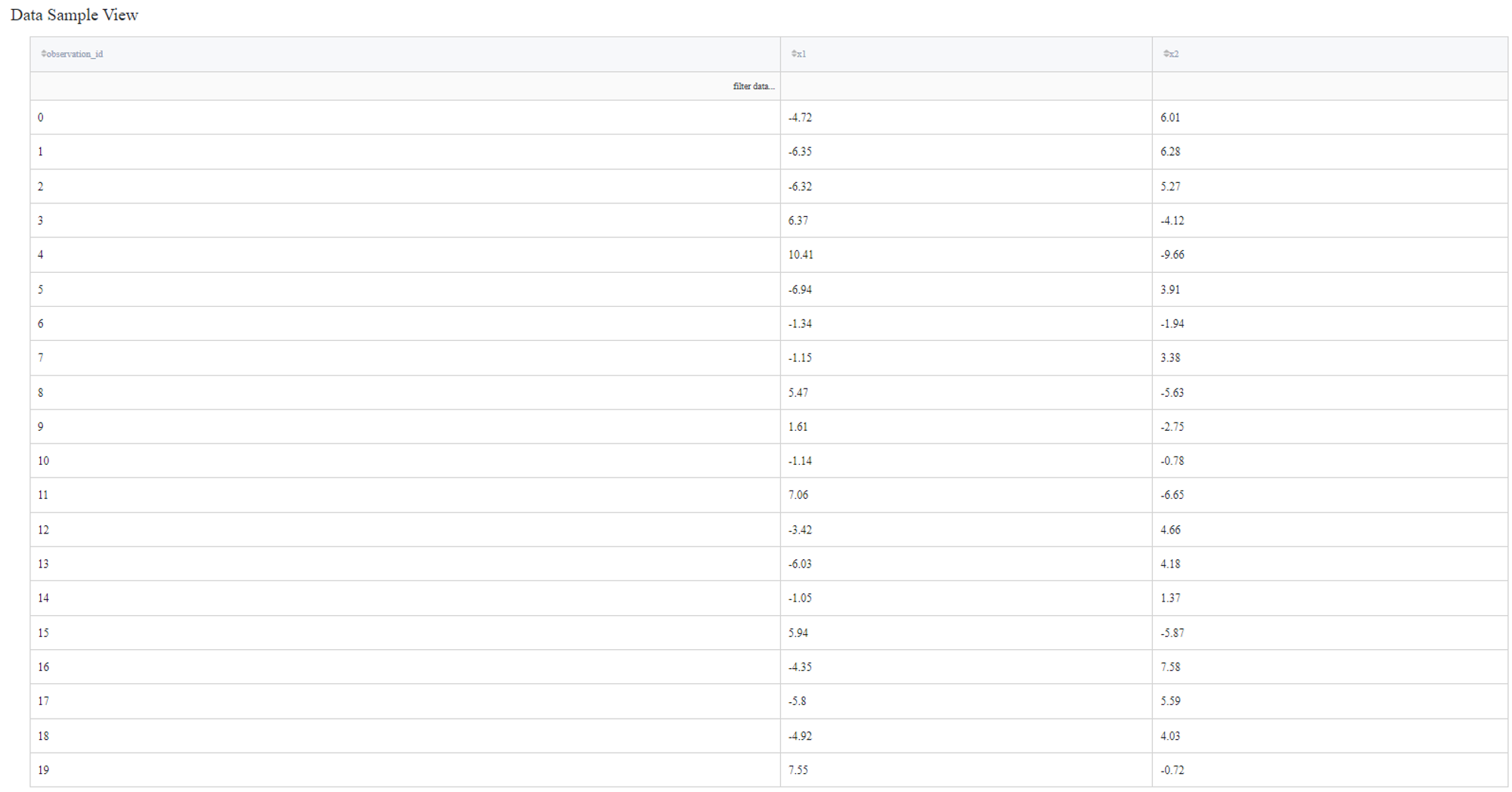
‘segmentation_blobs.csv’ has three columns: ‘observation_id’, ‘x1’, and ‘x2’.
‘segmentation_circles.csv’ also consists of three columns called ‘Unnamed: 0’, ‘0’ and ‘1’.
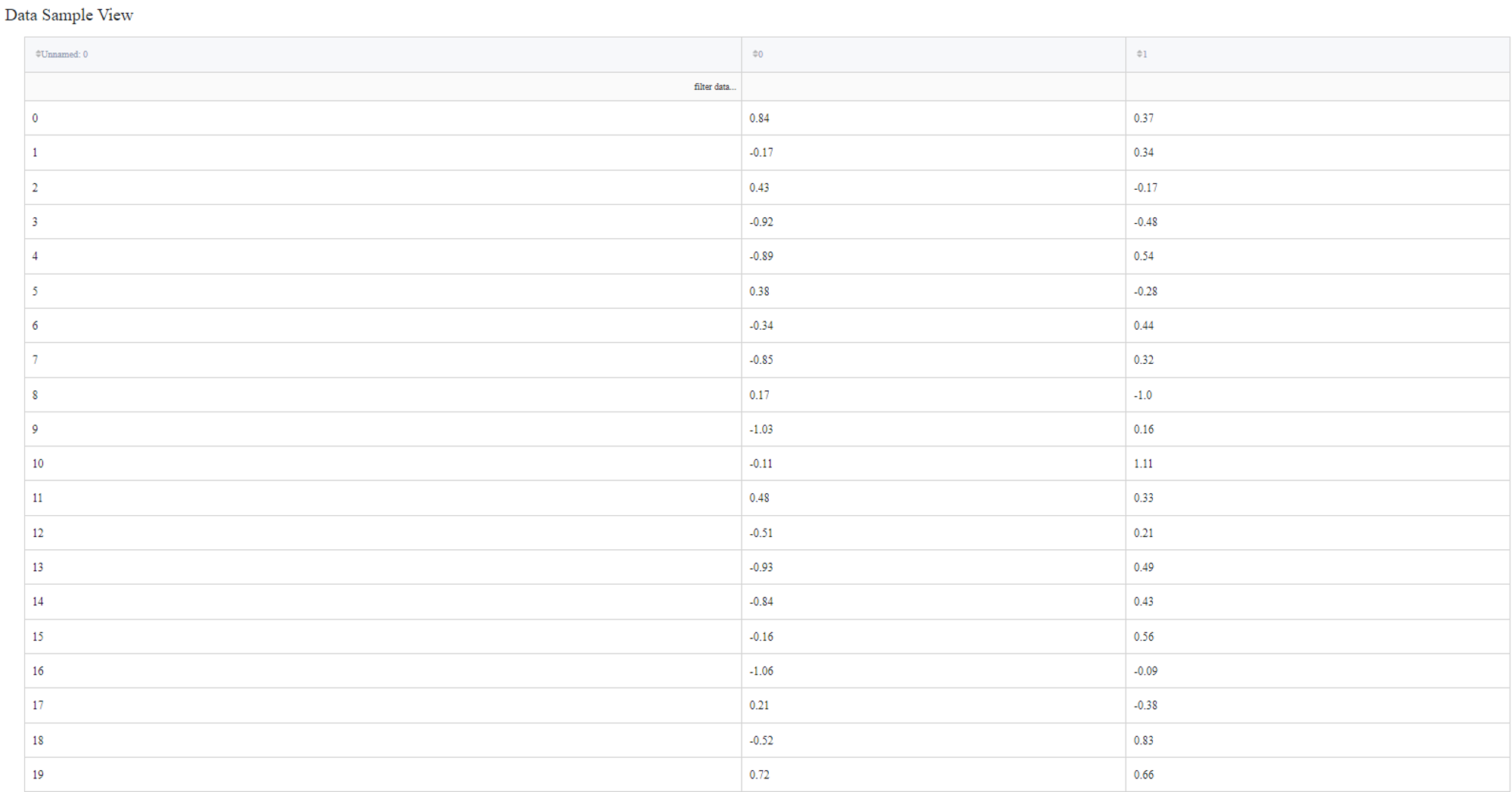
We’ll try to join the datasets based on the first columns as in both cases they have the same meaning and have shared values.
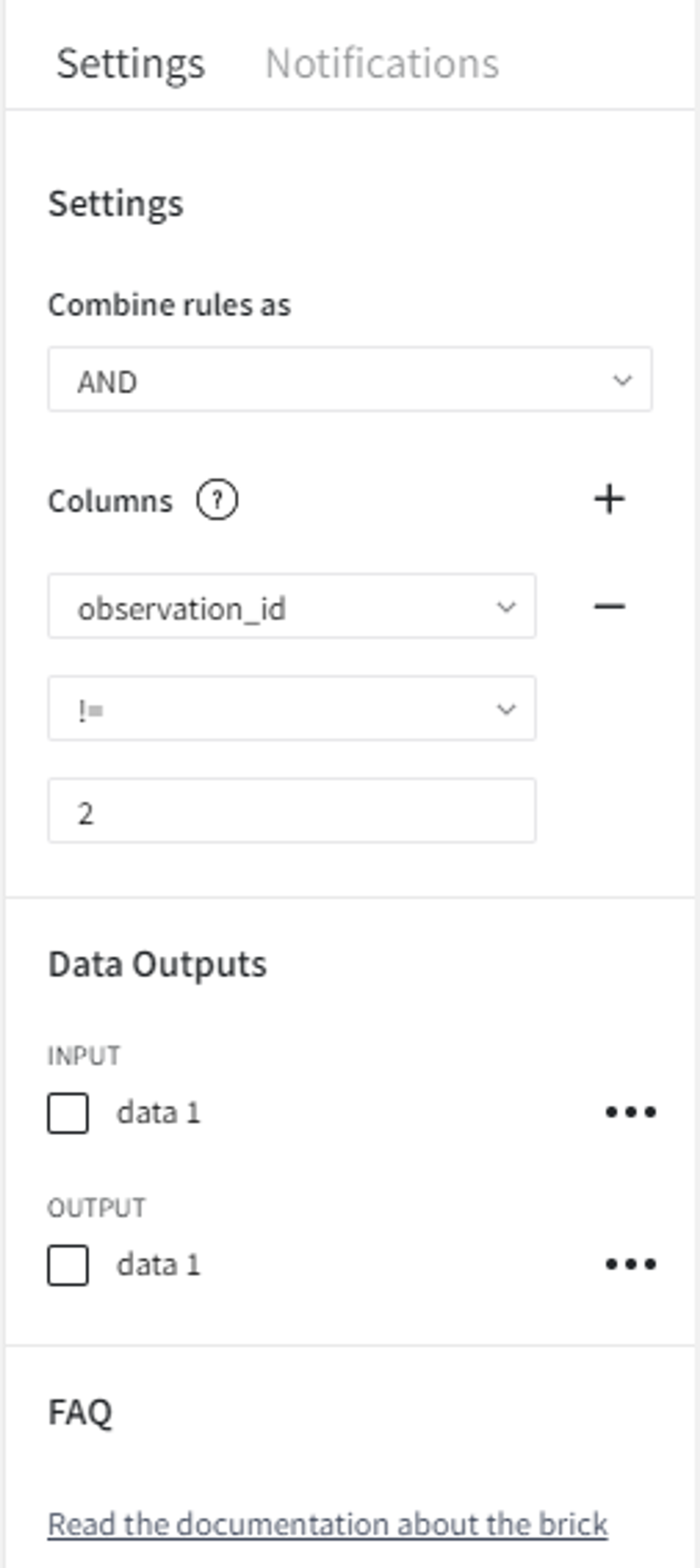
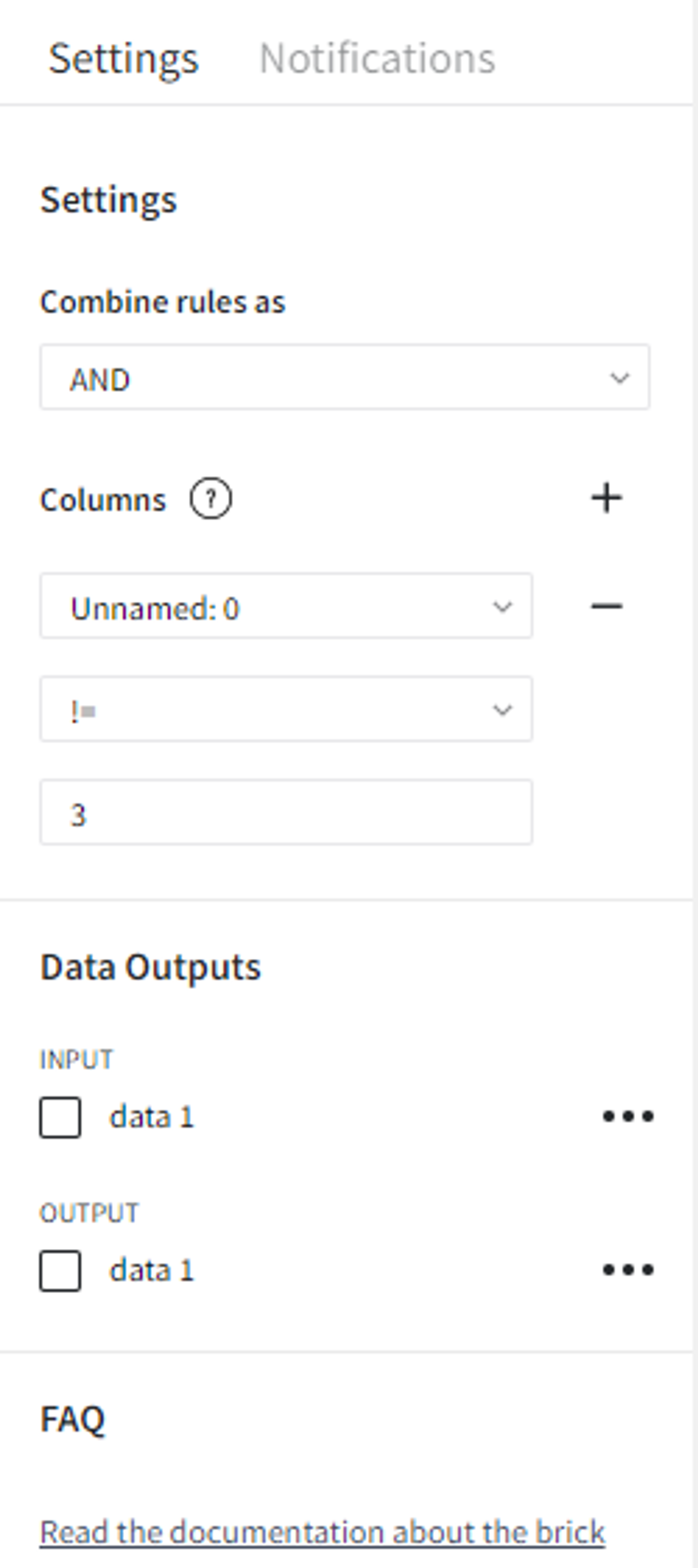
For better representation of what is the difference between the join types, we remove the row with id 2 from the first dataset and the row with id 3 from the second dataset using the Filter Rows Brick.
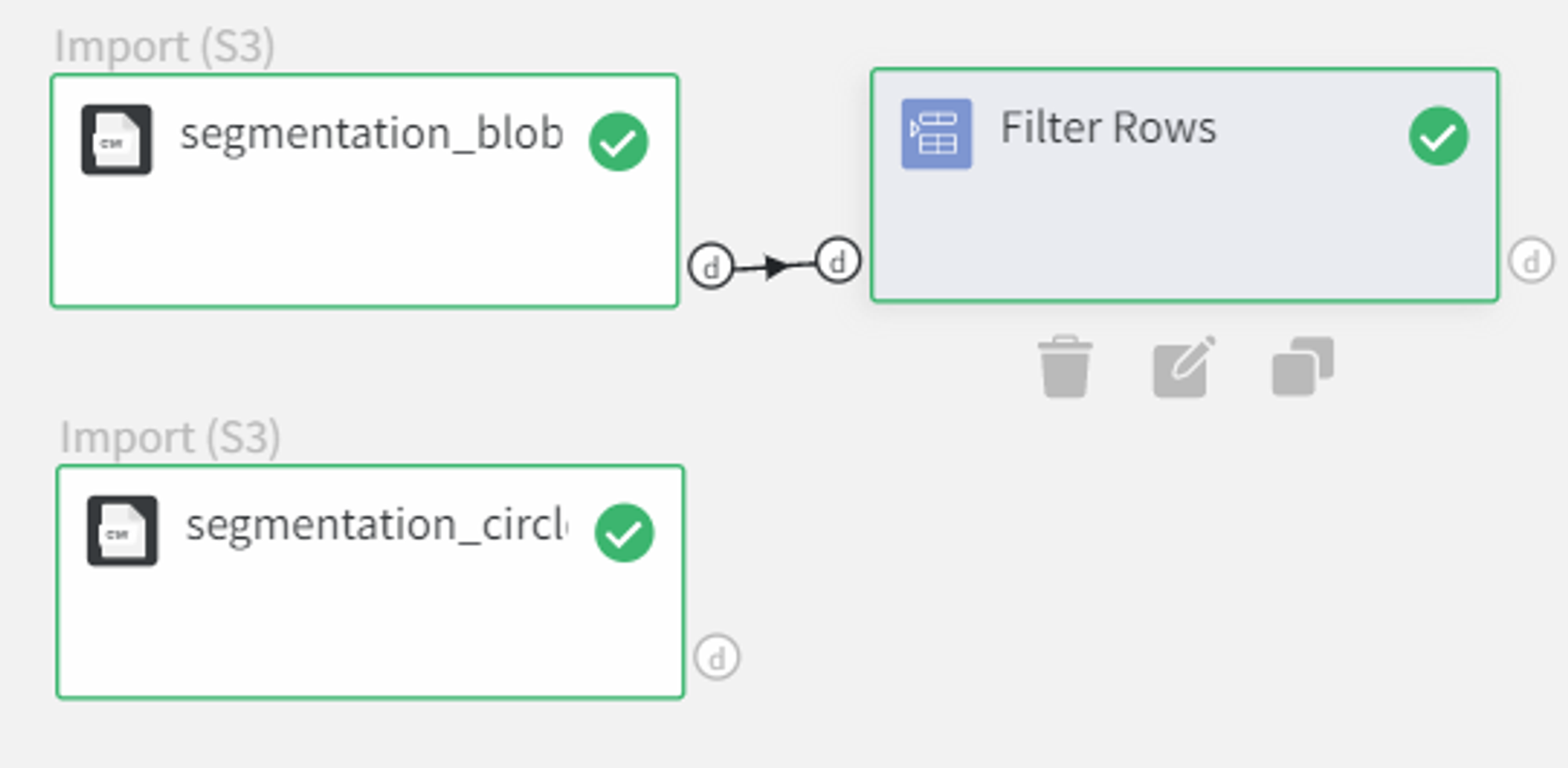
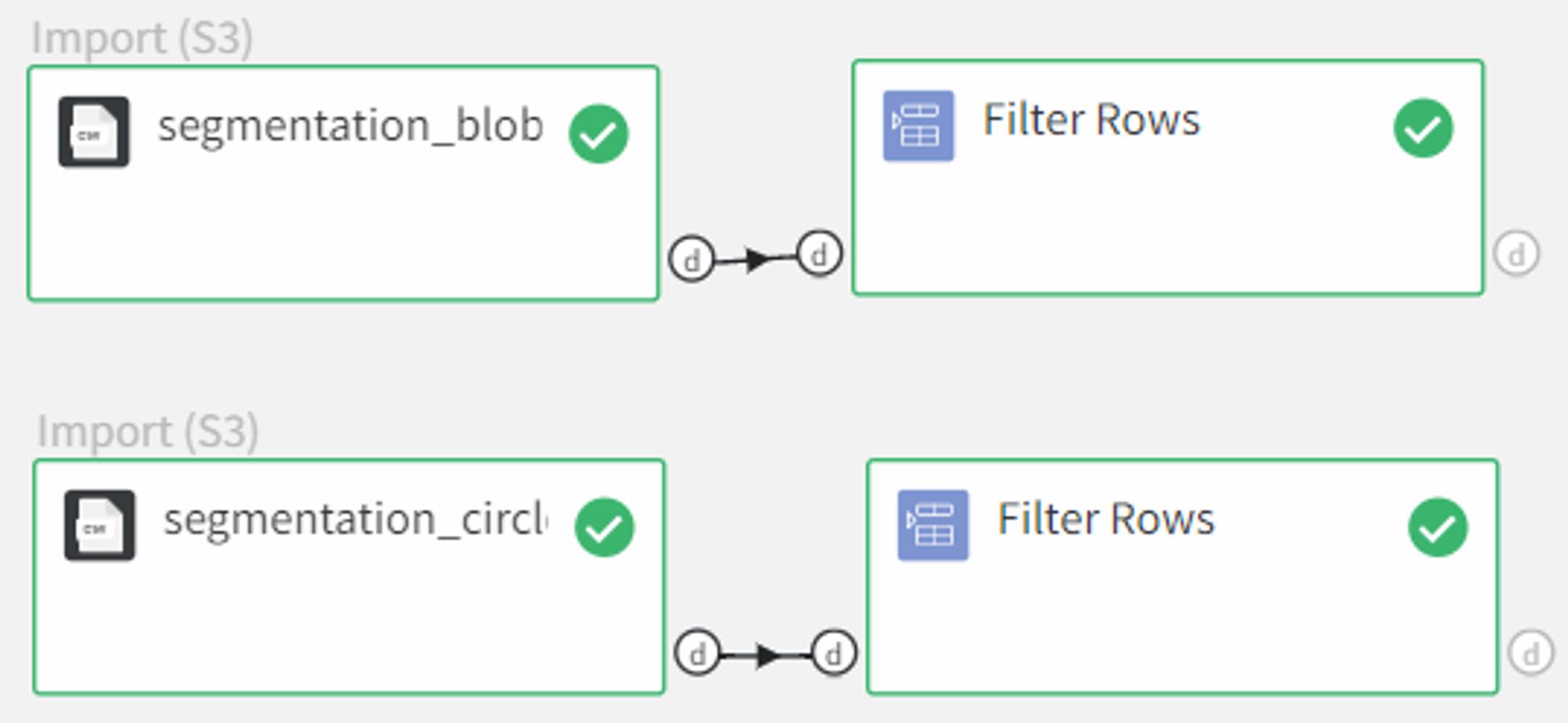
Now we can connect the outputs to the Join Data Brick.
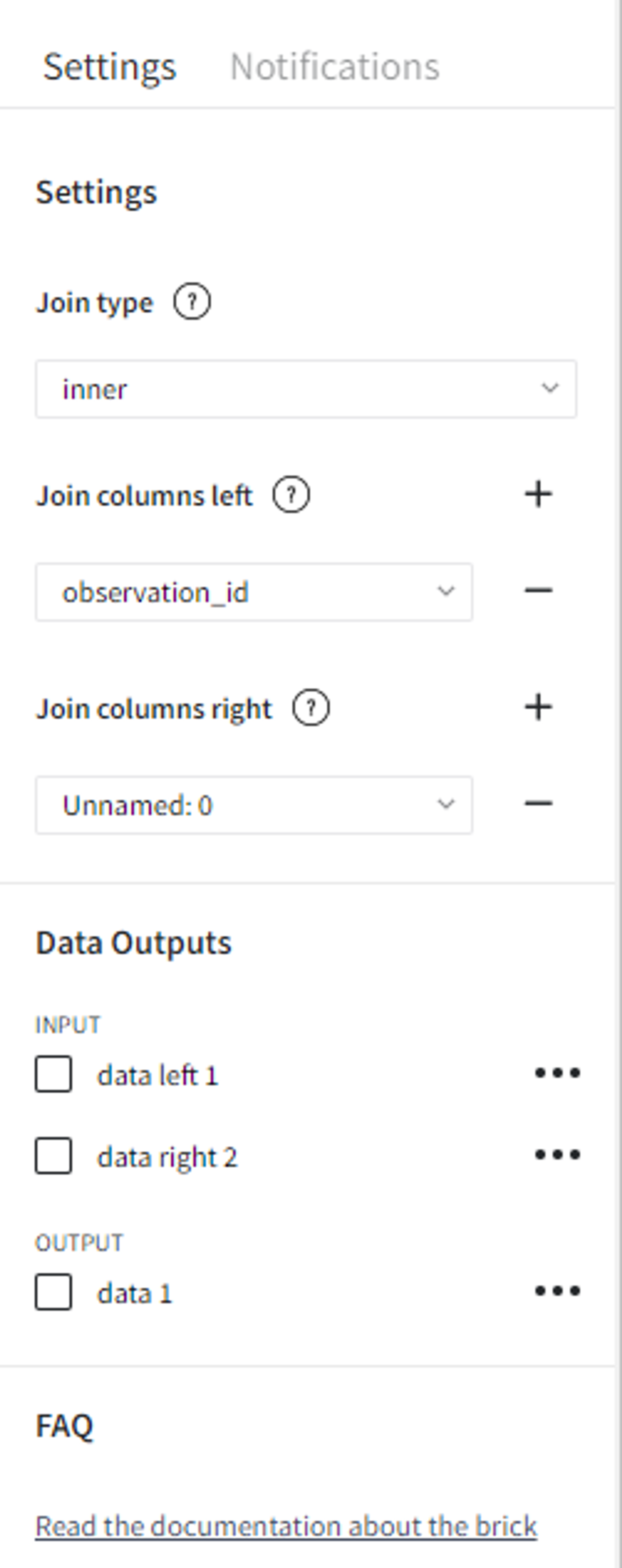
- Inner join
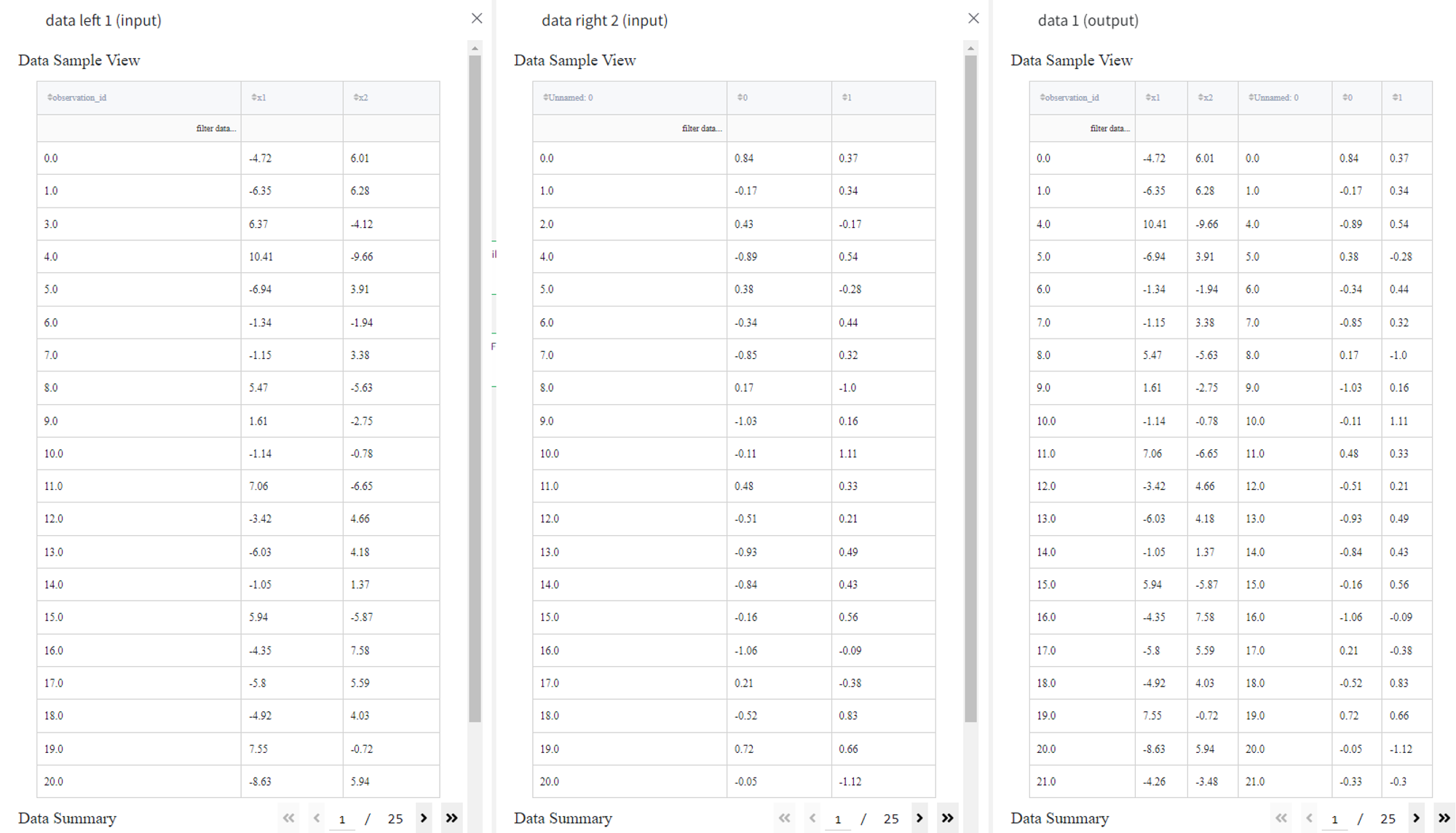
To apply the inner join operation we must select Join type — ‘inner’ and set the shared columns as Join columns left — ‘observation_id’ and Join columns right — ‘Unnamed: 0’. Now we can run the pipeline and see the result in the Output section. Records with id 2 and 3 are not present in the joint dataset since they had no matches for both datasets.
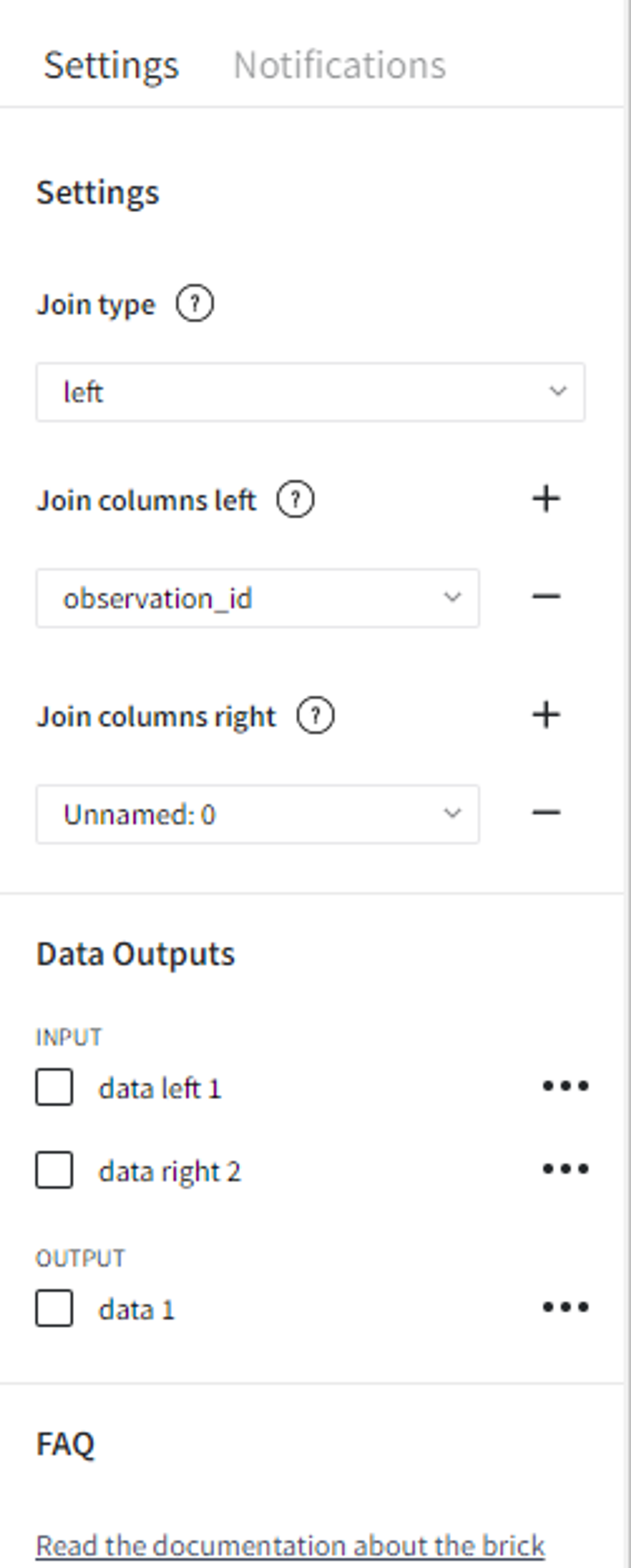
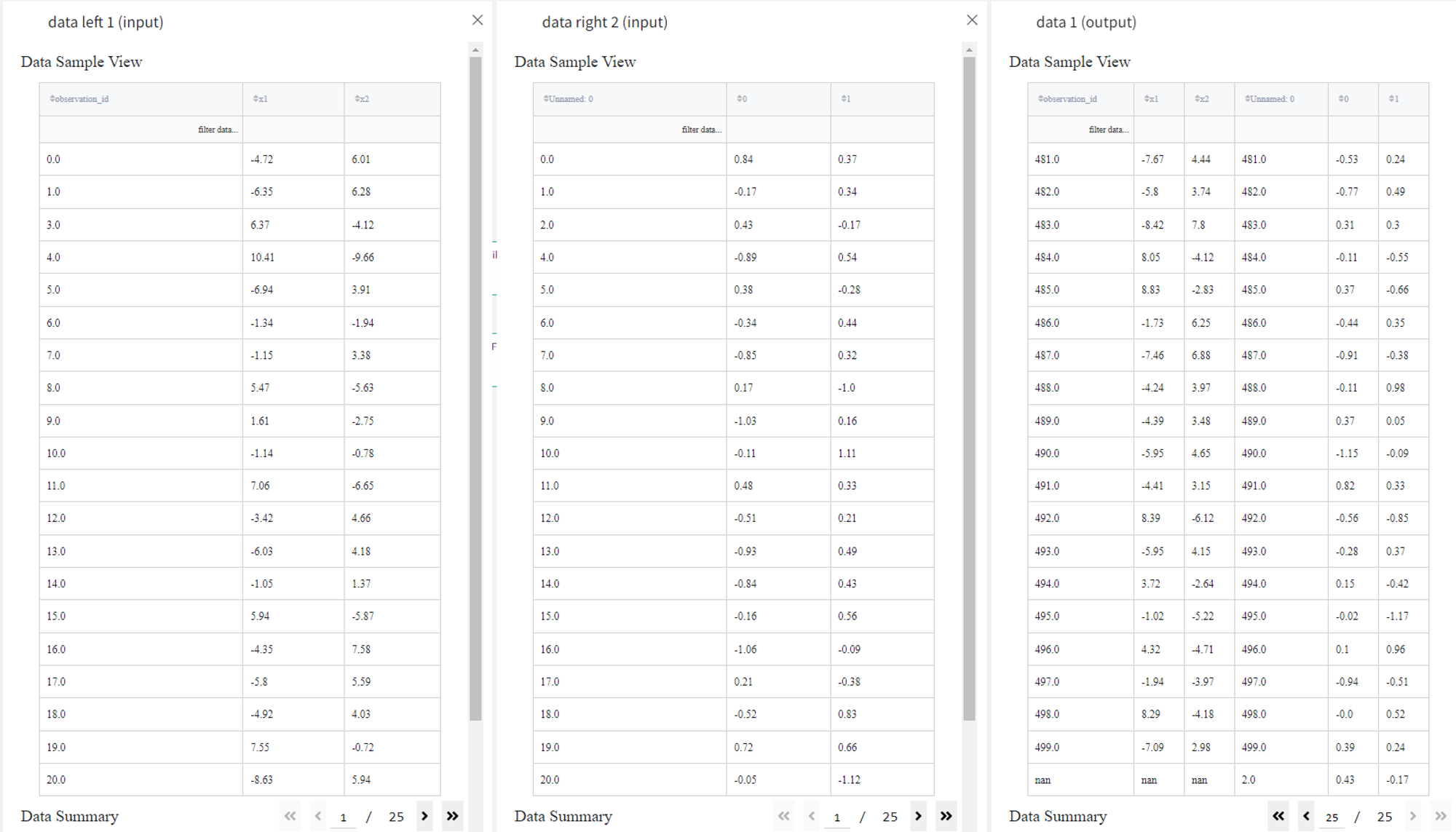
- Left join
If we change the Join type to ‘left’, leave the rest of the settings the same and rerun the pipeline, we get a dataset that has all the records from the first (left) dataset including the row with id 3, but since the id 3 is not in the second (right) dataset, the corresponding values are filled with ‘nan’.
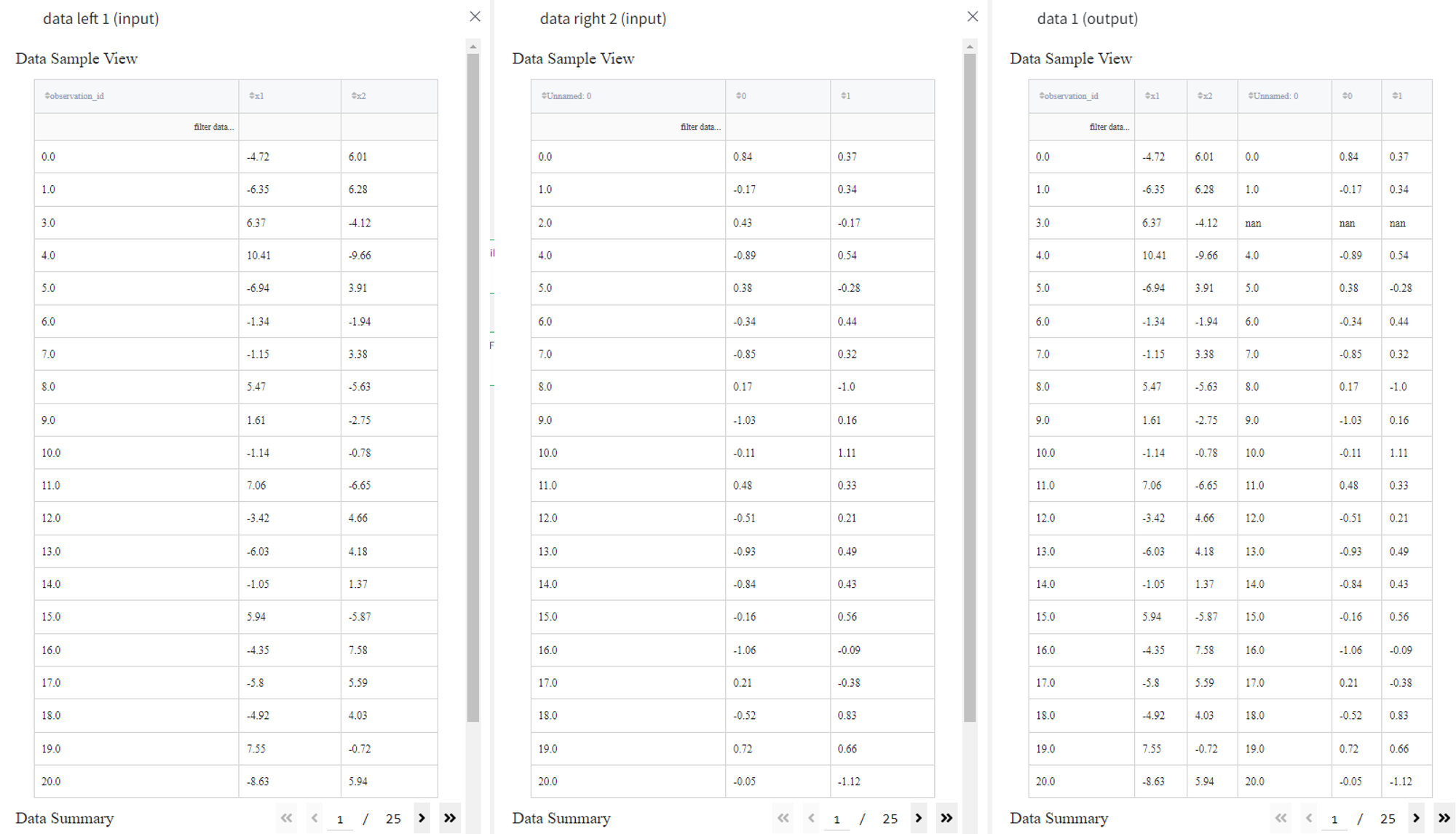
- Right join
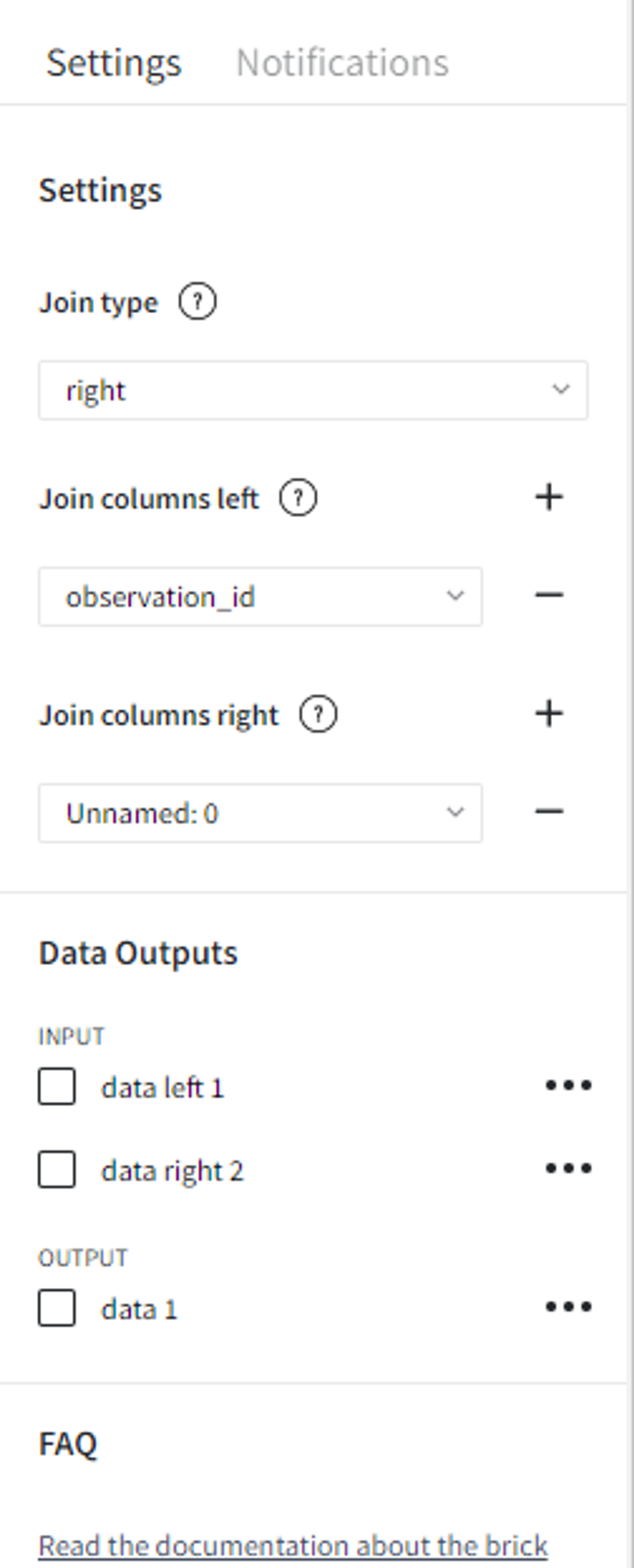
Right join works similarly to left joint, but it results in the dataset with all the records from the second (right) dataset. The values from the left (first) dataset that have no match are filled with ‘nan’.
- Outer join
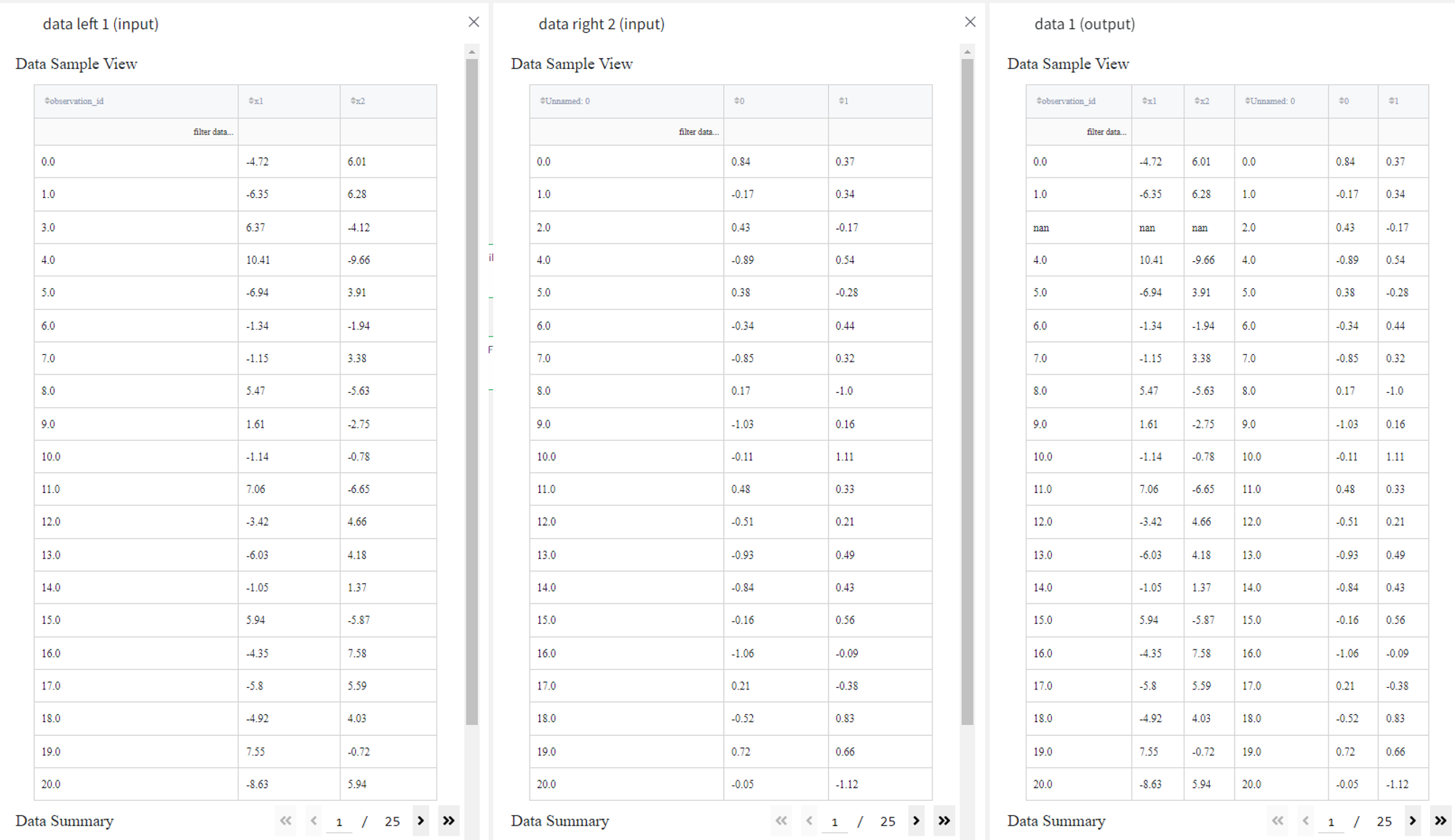
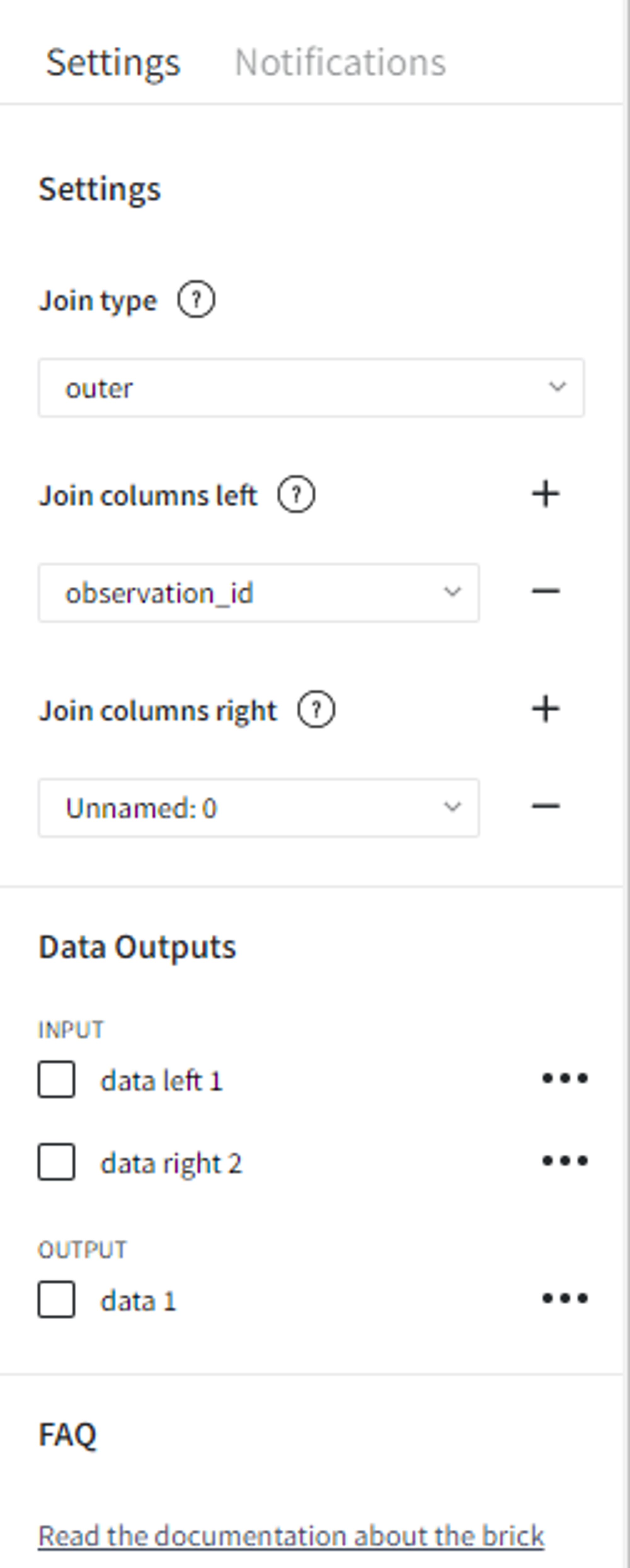
Outer join is a combination of left and joins so in our case we get the dataset with all the records from both sets with their matches.
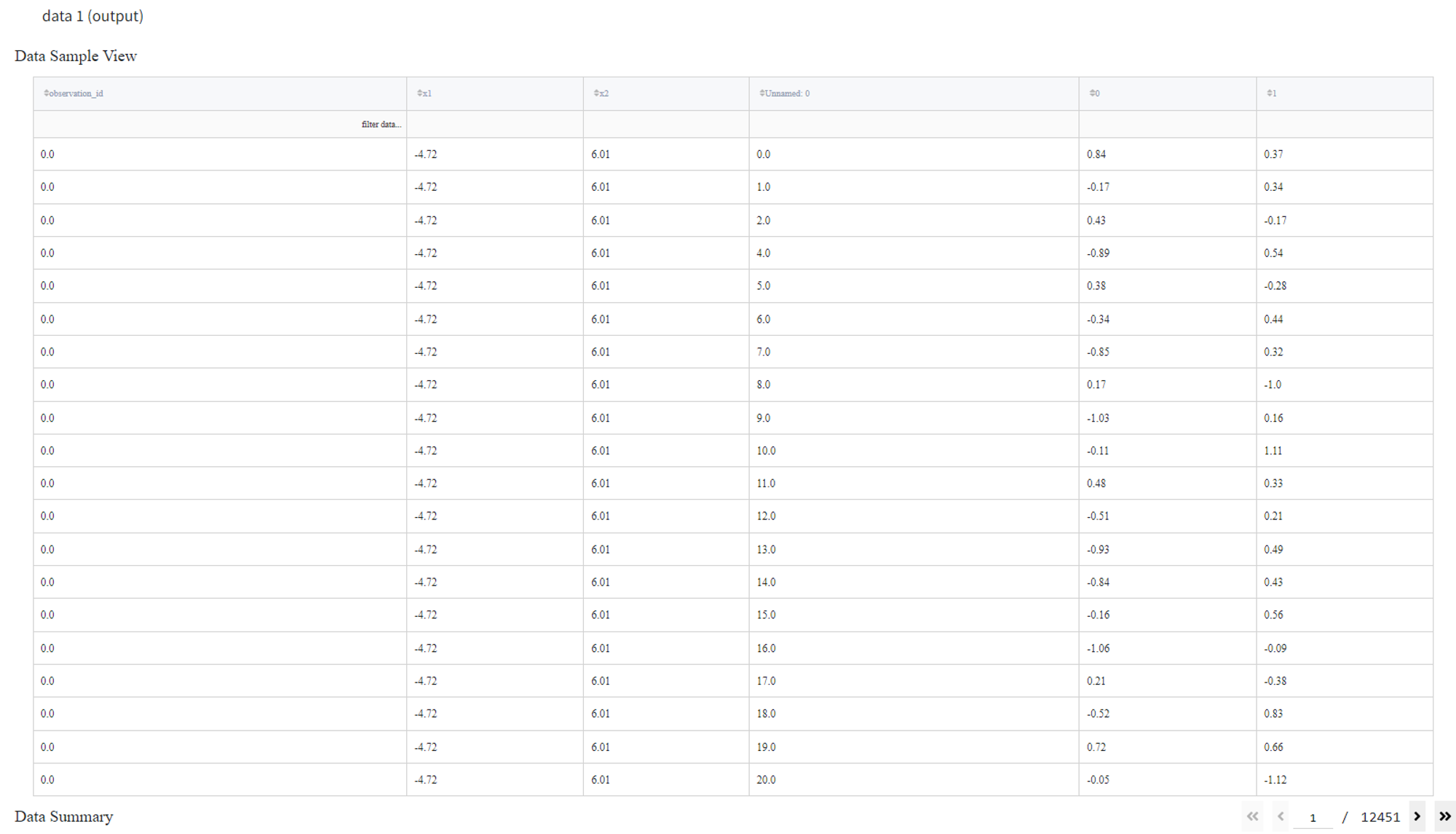
- Cross join
Cross join returns a dataset with all possible combinations of rows.