General Information
Each brick have some inputs and outputs, which may be either 'data' or 'model' type.
In case, when brick's input/output has 'data' type stored, they can be found in the 'Preview' section of the settings (usually, under all other sections, closer to the bottom):

There are several ways you can interact with the data stored inside them.
1. Preview Data
To view the data, you just need to mark the checkbox next to the desired input or output, as in the following image:

Right after that, the pipeline's working zone (center of the screen) will be changed to the 'Data Sample Preview' dashboard. This dashboard has two sections:
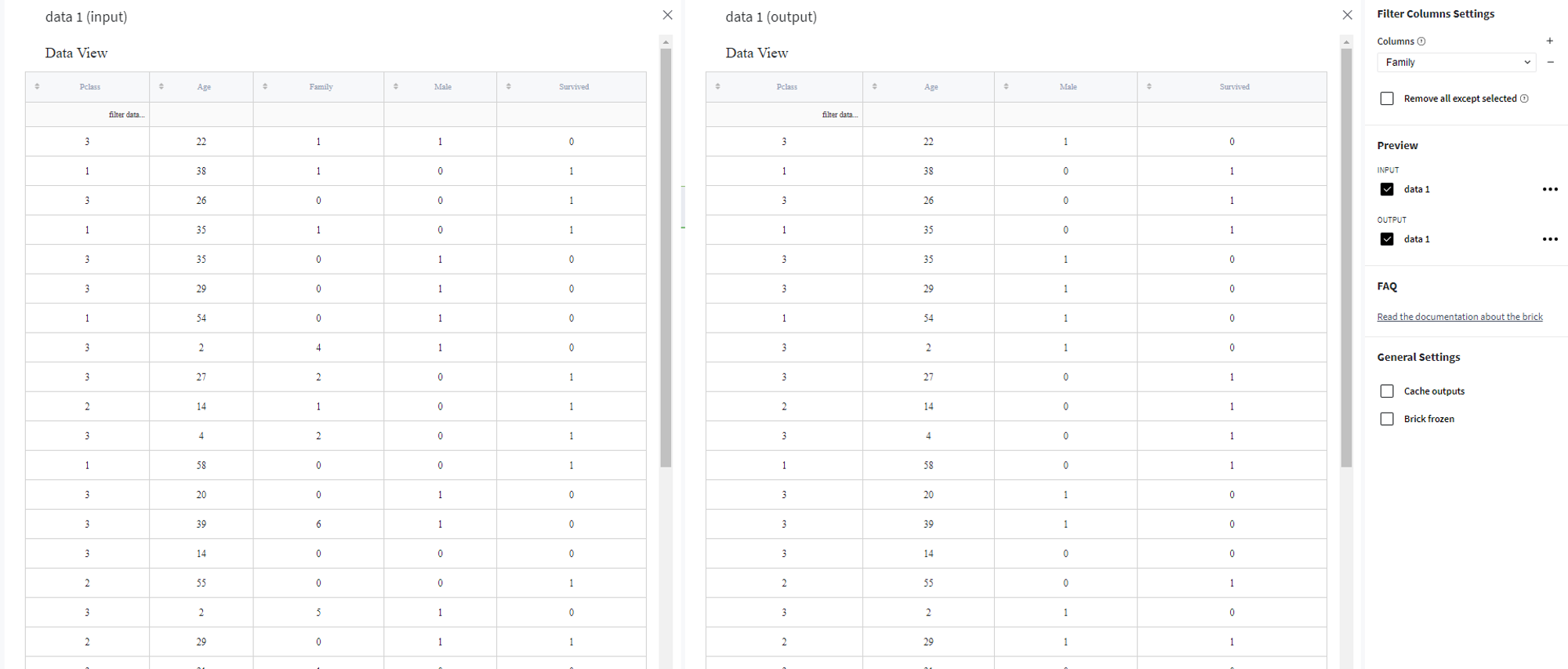
- Data Sample View
This part displays the sample of the stored data. You can check columns and their values here:
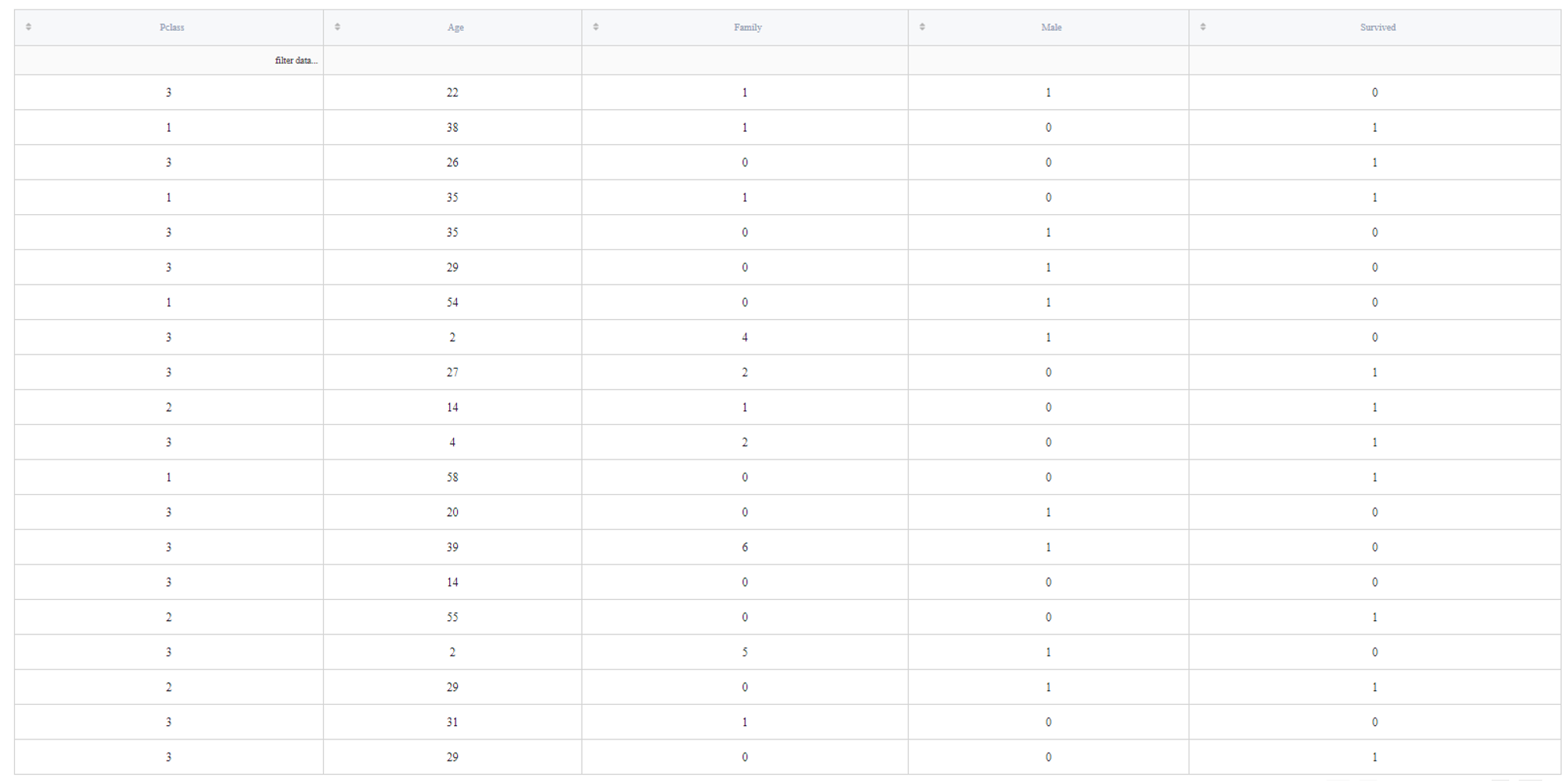
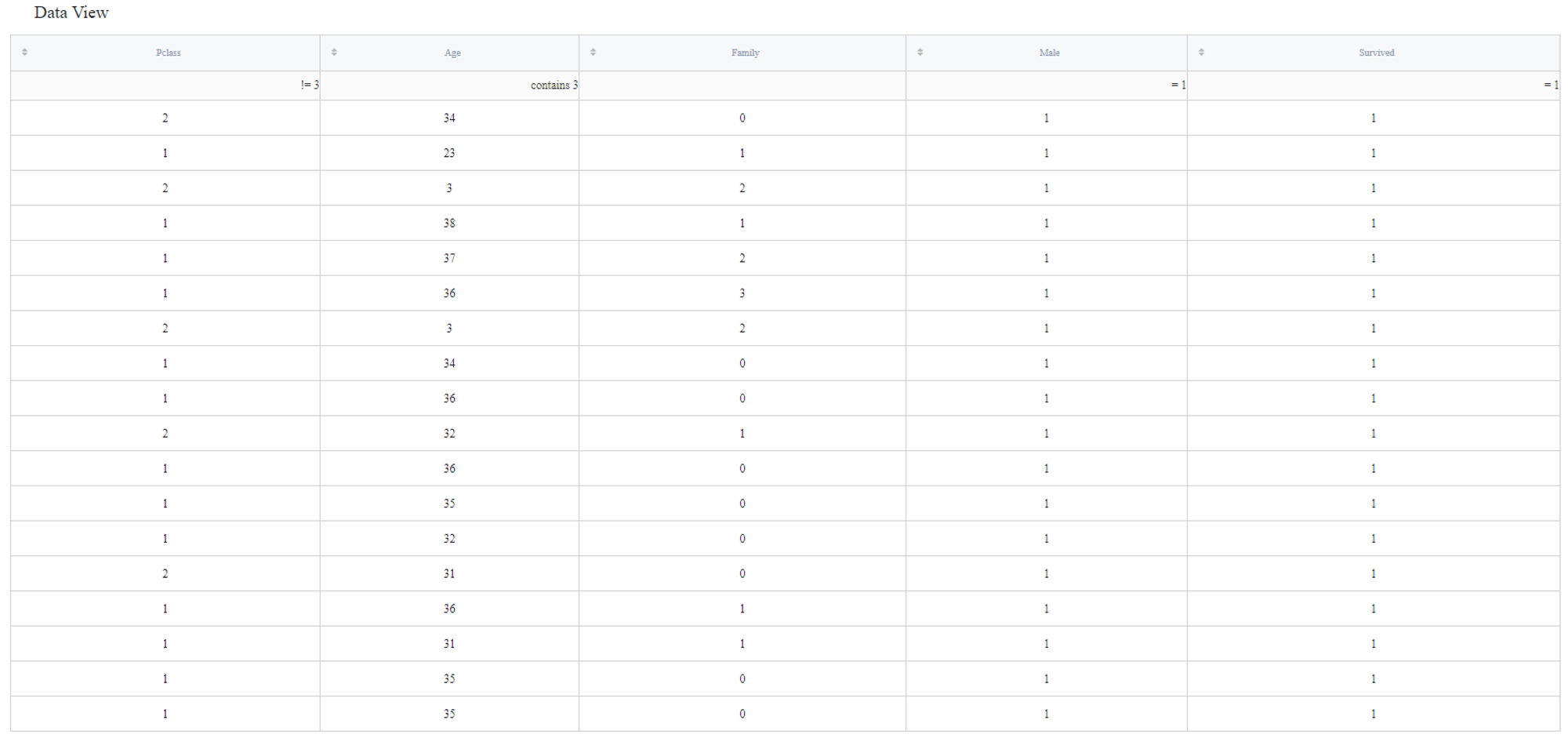
In addition, you can perform some basic filtering operations: =, !=, >, >=, <, <=, contains, datestartswith; which must be written down to the first row (marked with 'filter data...' placeholder). Here is an example:
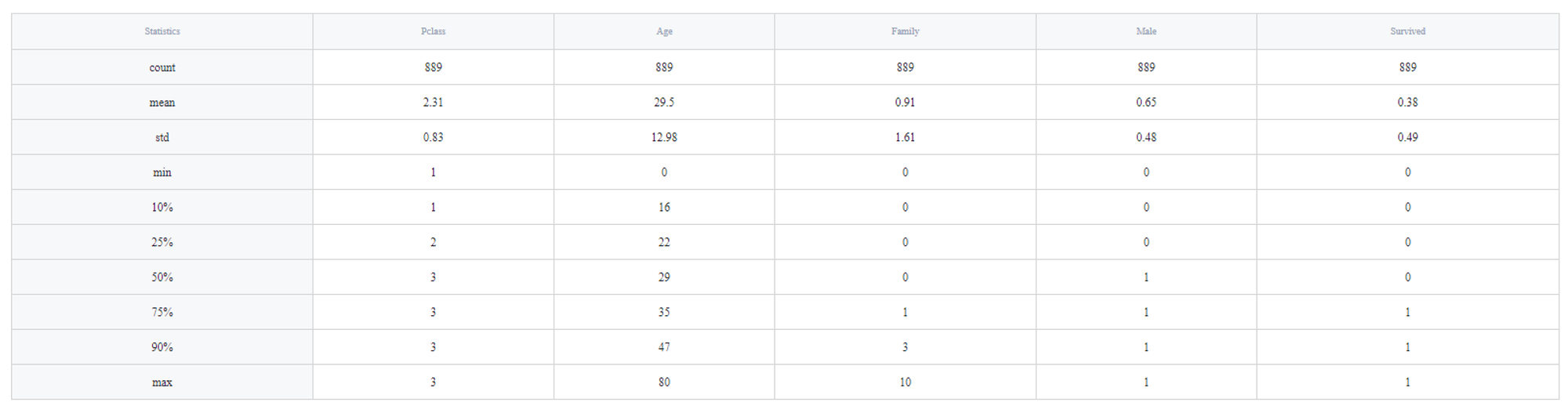
- Data Summary
This part is dedicated to data statistics (min and max values, mean, etc.). They are automatically calculated for each column and are displayed the following way:
To close the data previewer you will need to uncheck the input or the output.
In addition, you can open multiple windows of such data previewers to compare how data was changed. Just check several checkboxes:

The results will be displayed as follows:
2. Download the data
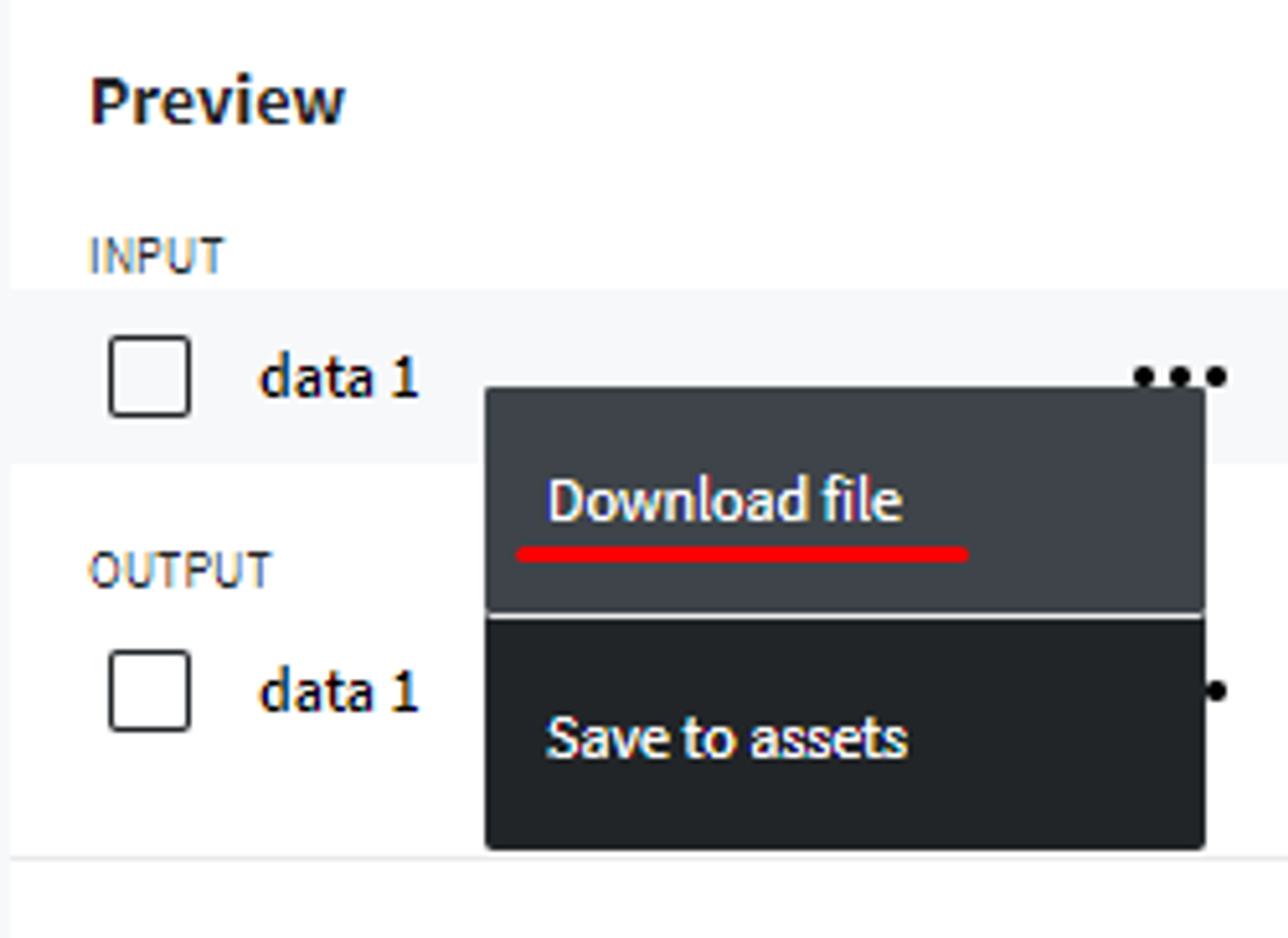
You can always download processed data for your own needs. It is pretty simple: just press the three dots button and choose the "Download file" option:
Then the browser's dialog window will be opened where you will need to specify the download path. Please notice, that data sets are stored in a parquet file format.
3. Save data as asset
This option is viable if you want to reuse your processed data in a different pipeline. The process is similar to the downloading option: press the three dots button and choose the "Save to assets" option:
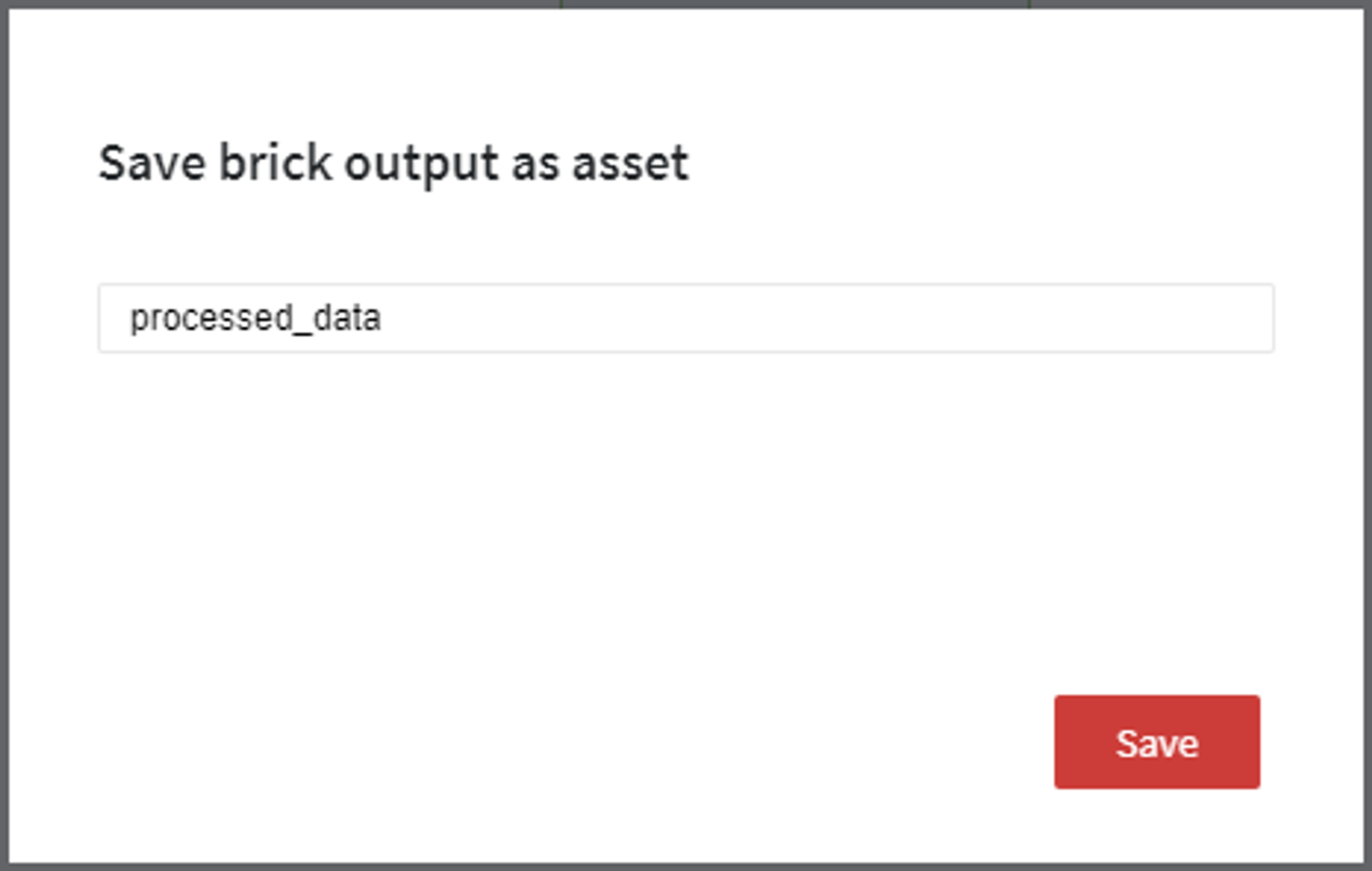
After that, specify the asset name in the modal window:
Now your data will appear in the 'Storage' section of the left sidebar: