General information
Splitting data to train and test datasets is essential to ensure that the developed ML model works correctly by testing it on previously unseen data. By doing so we have the ability to check if the model is overfitting or underfitting, so we can further improve its architecture or data preprocessing.
Description
Brick Locations
Bricks → Data Manipulation → Split Data
Brick Parameters
- Test size
The fraction of the dataset withheld for validation (0.1 stands for 90% training and 10% test split).
- Shuffle
A checkbox that indicates whether the data should be shuffled.
- Stratify columns
Allows you to perform stratified sampling on specified columns (you can add multiple columns by clicking the '+' button). Note that it’s possible only if the data is shuffled.
- Brick frozen
Enables the frozen run for this brick. It means that the train and test sets are saved and don’t change at every pipeline run.
Brick Inputs/Outputs
- Inputs
Brick takes a dataset
- Outputs
- train
- test
Brick produces two datasets:
Example of usage
Split Data Brick should be directly connected to the dataset we would like to split.
Let’s use the ‘titanic.csv’ dataset in this example.
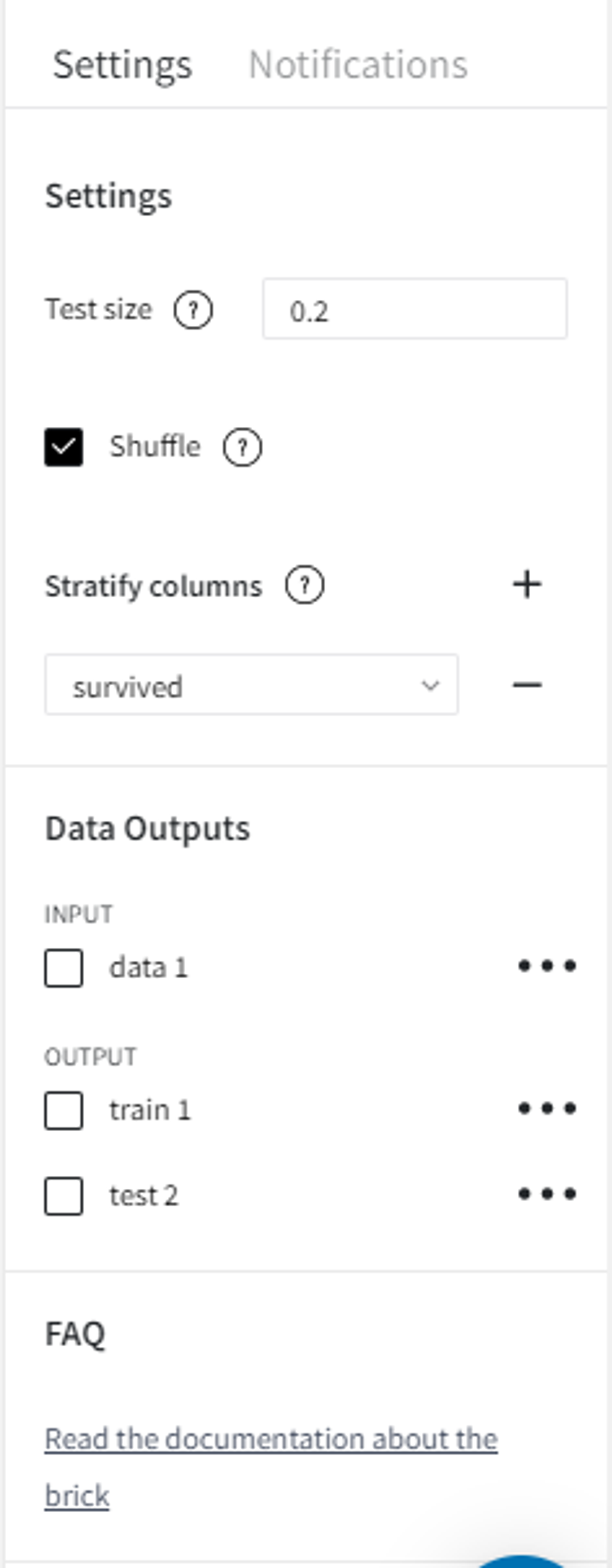
As for the split parameters, first, we should select the test split ratio to determine what fraction of the dataset will be withheld for the model's validation.
We can also shuffle the dataset before the splitting to get different results on each run and decrease the chances that train and test sets will contain different non-overlapping classes. When working with time series, be mindful that some algorithms expect your data to be sorted, so shuffling might negatively impact model performance.
In addition, we can perform stratified sampling on the ‘survived’ column.
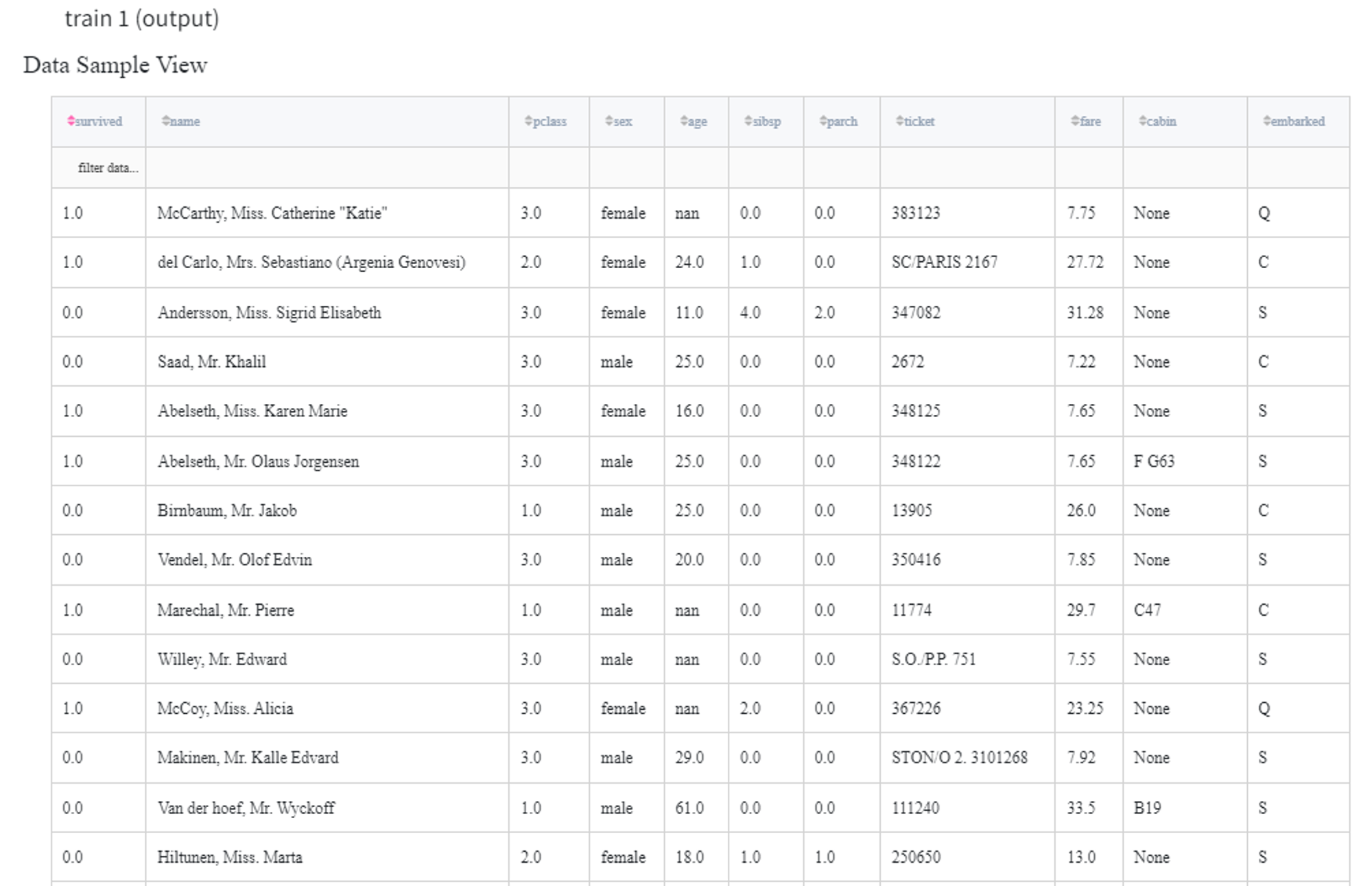
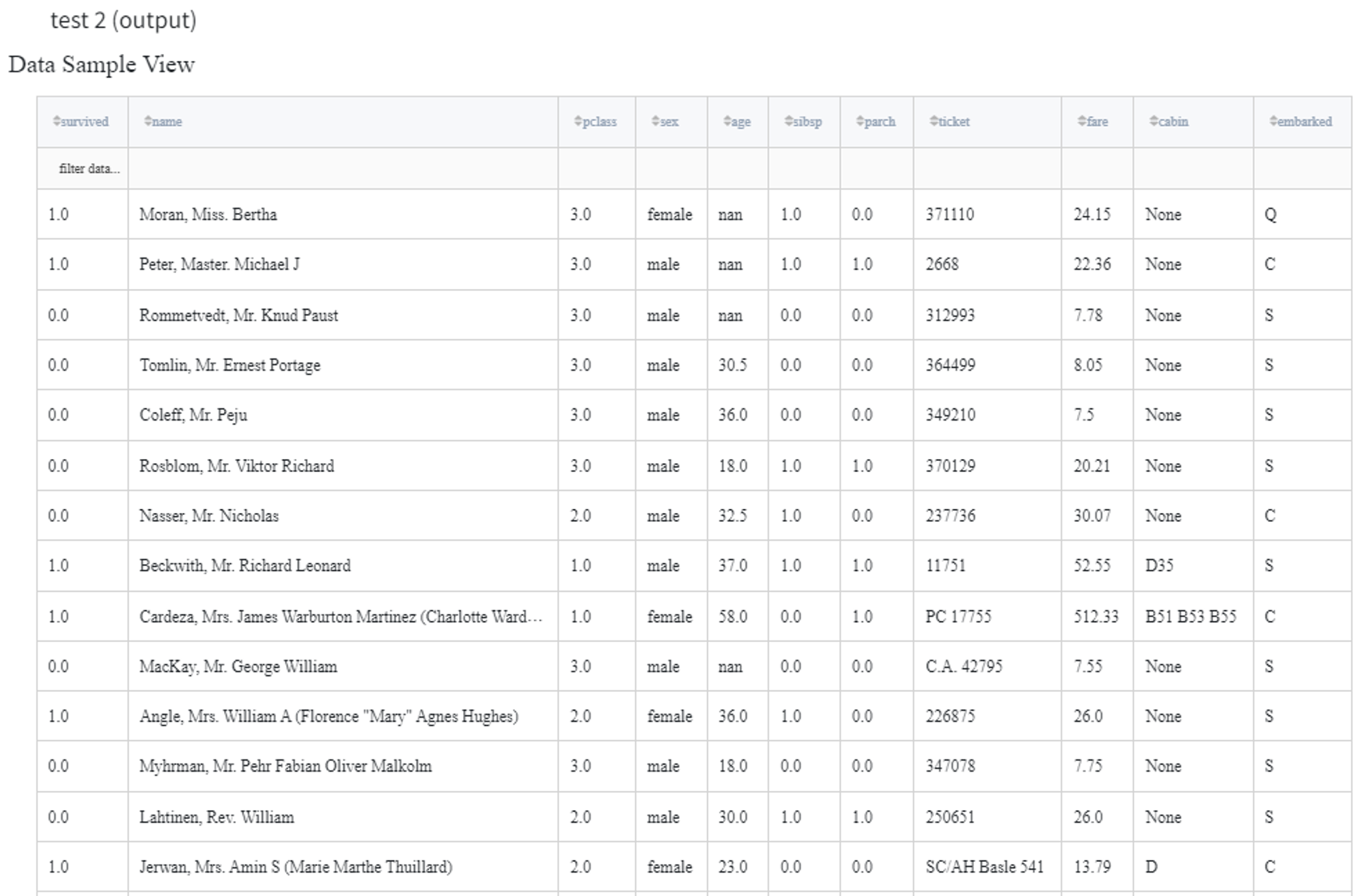
After running the pipeline we get the following train and test datasets:
Recommendations
- Make sure that the test set is representative of the data set as a whole. It's advisable to shuffle the dataset when possible.
- Make sure that the test set is large enough to yield statistically meaningful results (e.g. 500 observations require at least 20% to be withheld for validation, while 1 million records might work well with under 5%).
- Never train on test data. It might cause model overfitting. This dataset is only used for model evaluation and different model comparisons to see how well the model performs on unseen data and evaluate how the model will perform in real-life scenarios.