General information
The Transform brick applies one or multiple rules of transformation from the bricks with the transformers to the new data.
Description
Brick Locations
Bricks → Transformation → Transform
Brick Parameters
Brick Inputs/Outputs
- Inputs
Brick takes the dataset and one or many transformers from the transformation bricks.
- Outputs
Brick produces the dataset with the transformed data.
Example of usage
Let’s consider the ‘House price prediction’ problem. First, we need to do data preprocessing in order to use any regression model as we have several columns that are non-numerical.
The initial preprocessing includes filtering the unnecessary ‘Id’ column and splitting the entire data into train and test sets.
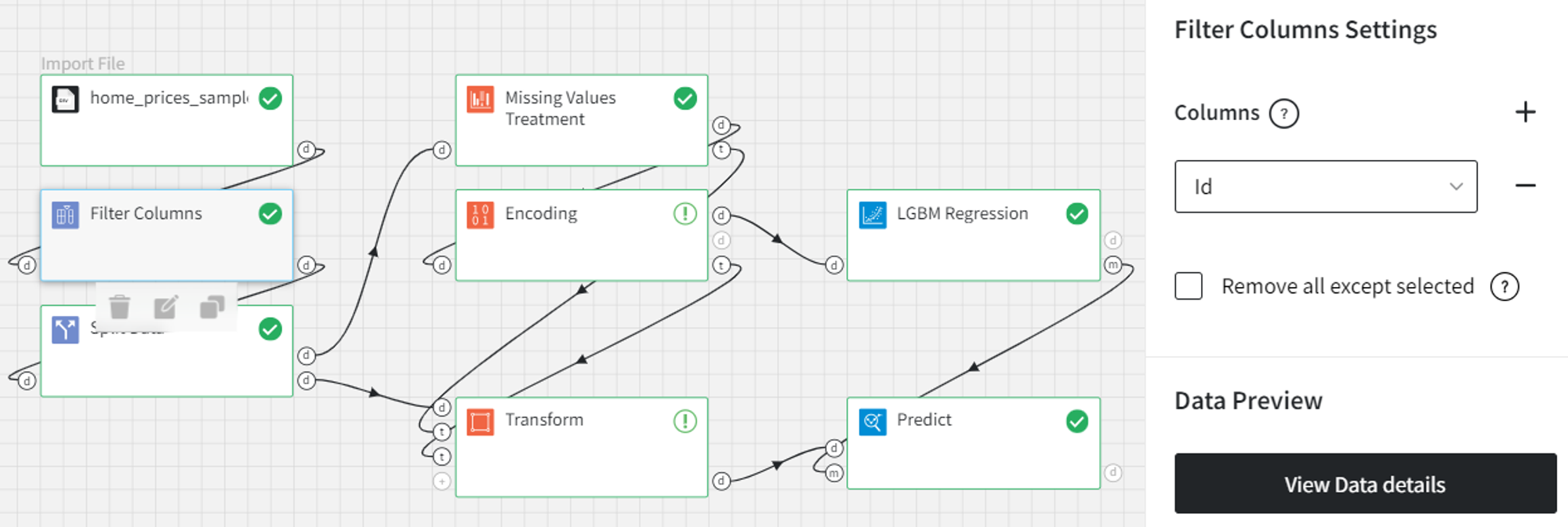
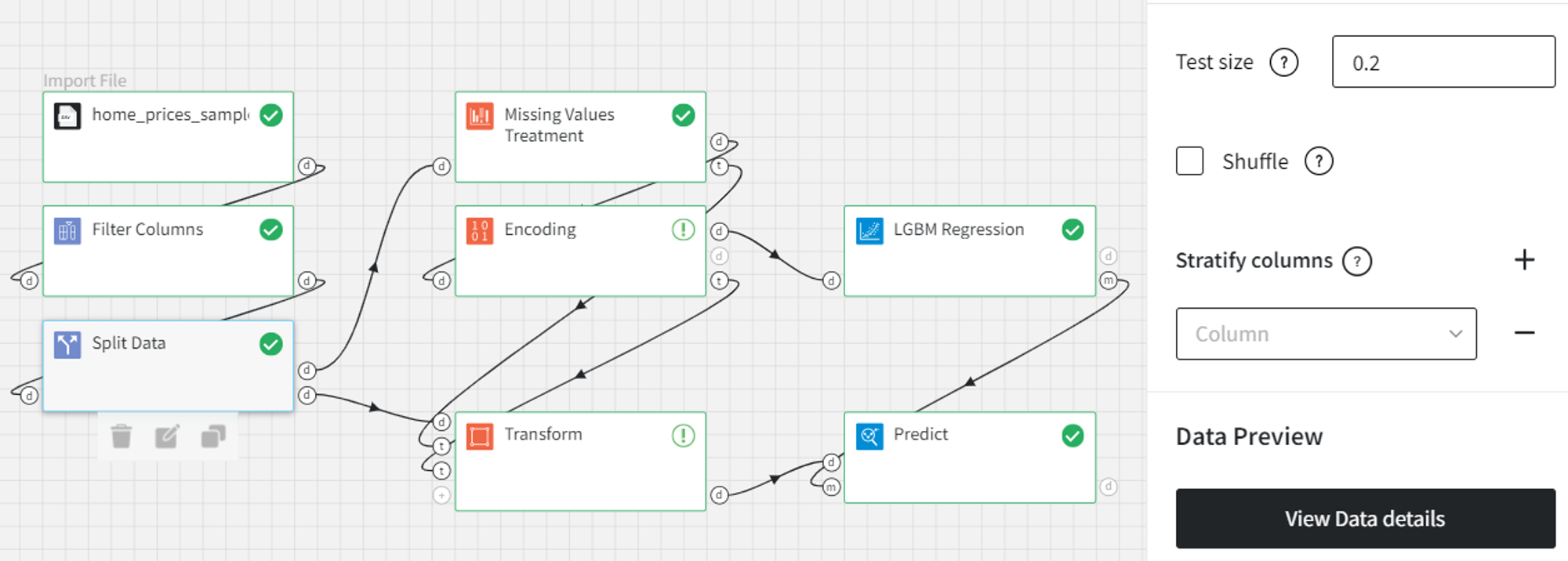
After splitting the data we have to treat the missing values and encode the categorical columns. To prevent data leakage, we do that only for the train dataset.
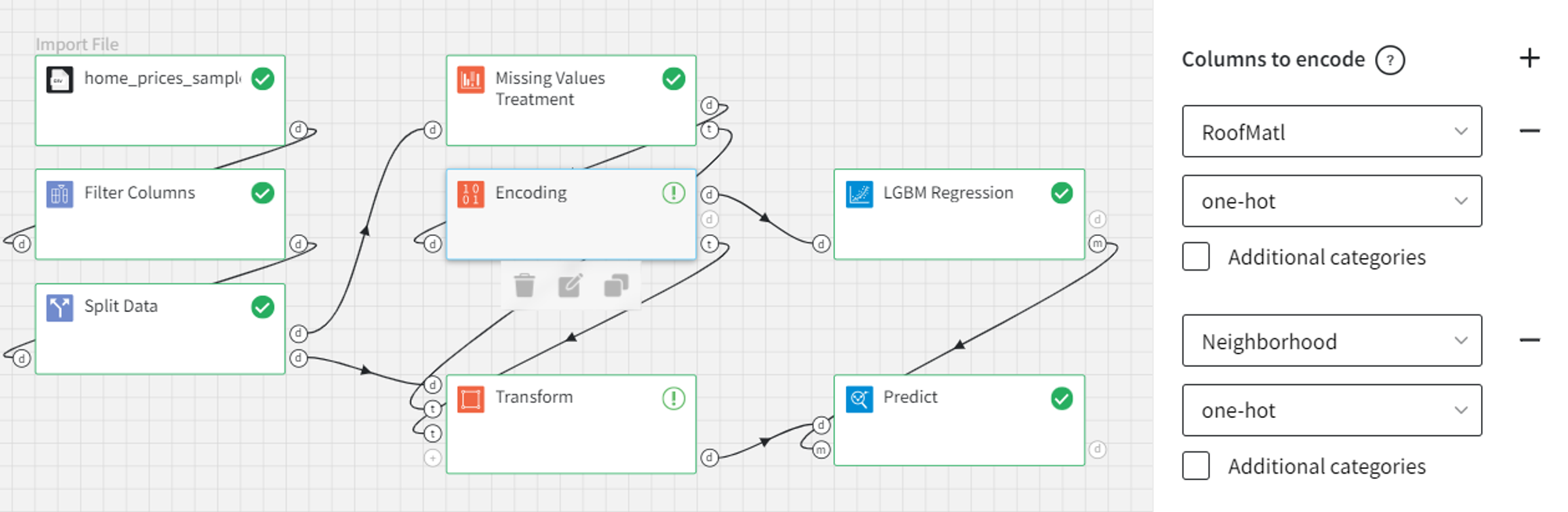
Both Missing Values Treatment and Encoding bricks return datasets along with the trained transformers in their outputs. Those transformers can further be used to modify the unseen data.
Then, we can train a regression model to predict the ‘SalePrice’.
As for the test data, we have to make sure that we do the same transformations as in the train set with the shared parameters. So in this case the Transform brick is a good option. We connect the test data and the transformers retrieved from the Missing Values Treatment and the Encoding bricks to the Transform brick.
Finally, we can use the test data, which was transformed according to the defined rules, for the model prediction.