General information
Brick provides a possibility to transpose the dataset (flips over its diagonal). That is, it switches the row and column indices of the dataset by producing another dataset. Repeating the process on the transposed dataset returns the elements to their original position.
Description
Brick Location
Bricks → Data Manipulation → Convert / Replace → Transpose
Brick Parameters
- Filter columns settings
- Columns
- Remove all except selected
List of columns that are going to be excluded. It is possible to choose several columns by clicking on the '+' button in the brick settings.
If the checkbox is on, only the selected columns will be considered, otherwise, they will be filtered out.
- Settings
- keep first column
- keep column names
If the checkbox is on, the first column will become column names, otherwise, it will become the first row.
If the checkbox is on, column names will become the first column, otherwise, they will be omitted.
Brick Inputs/Outputs
- Inputs
Brick takes the dataset.
- Outputs
Brick produces the result as a new dataset.
Example of usage
Let's consider the dataset from the binary classification problem . The general information about the dataset is represented below:
- passengerid (category) - ID of passenger
- name (category) - Passenger's name
- pclass (category) - Ticket class
- sex (category) - Gender
- age (numeric) - Age in years
- sibsp (numeric) - Number of siblings / spouses aboard the Titanic
- parch (category) - Number of parents / children aboard the Titanic
- ticket (category) - Ticket number
- fare (numeric) - Passenger fare
- cabin (category) - Cabin number
- embarked (category) - Port of Embarkation
- survived (boolean) - True/False
Lets take a look on that data:
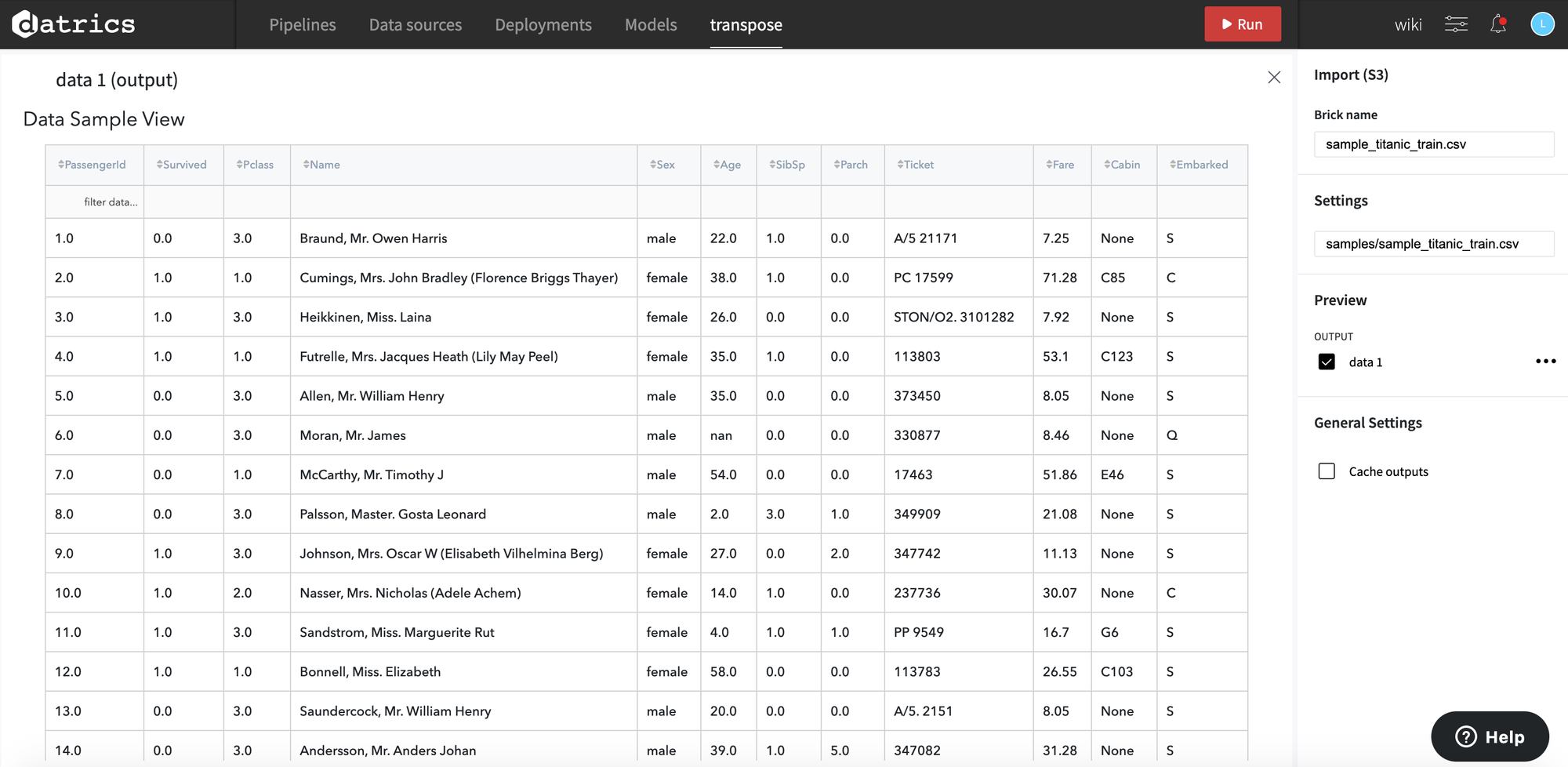
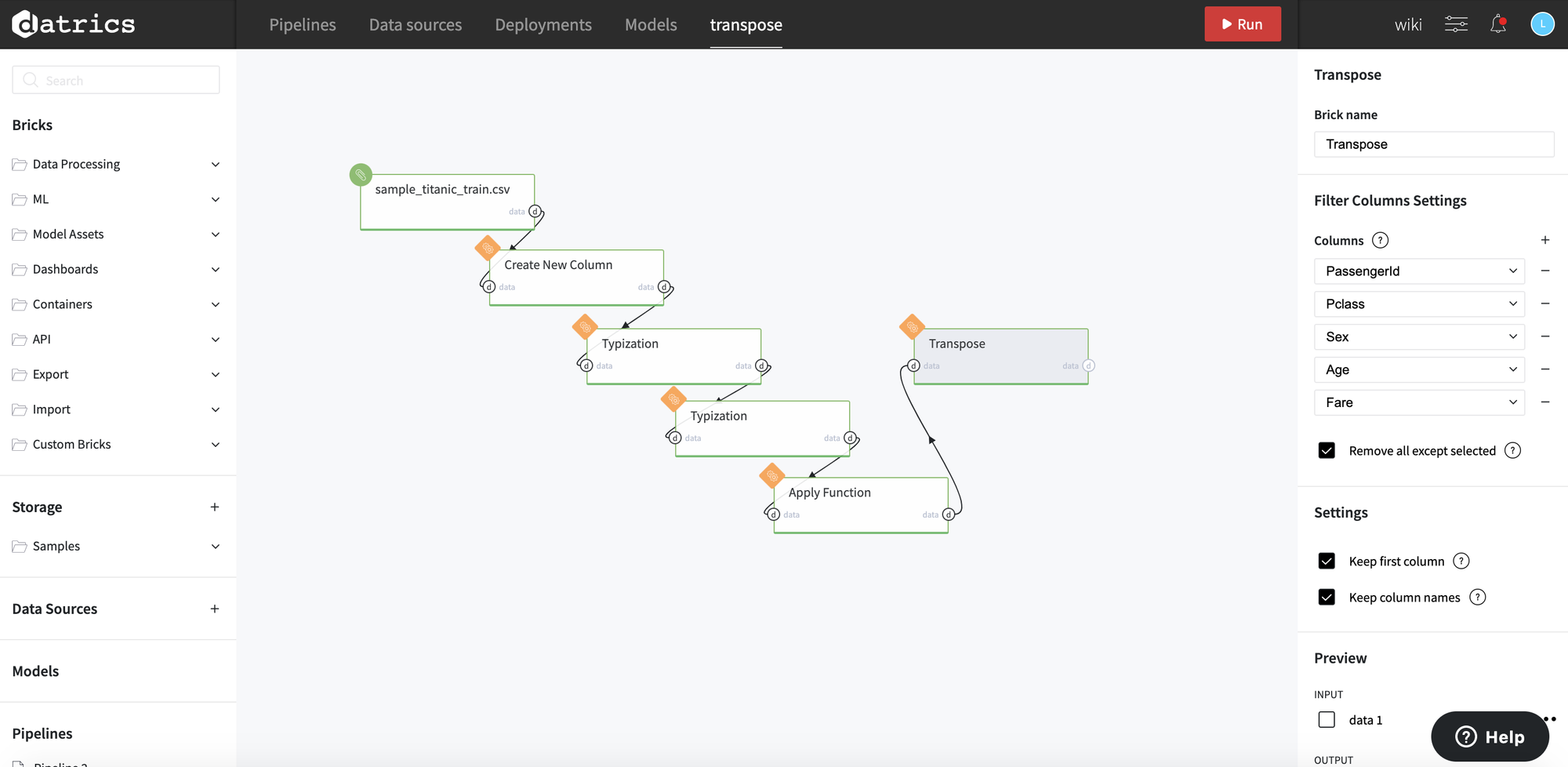
Let's say we want to see the data (e.g. ticket class, sex, age, and fare) for each passenger in a different column, in the more tabular form. To do so, we can use Transpose Brick with the following configuration (with a few additional bricks to preprocess final column names to be more readable):
The output of the Transpose Brick:
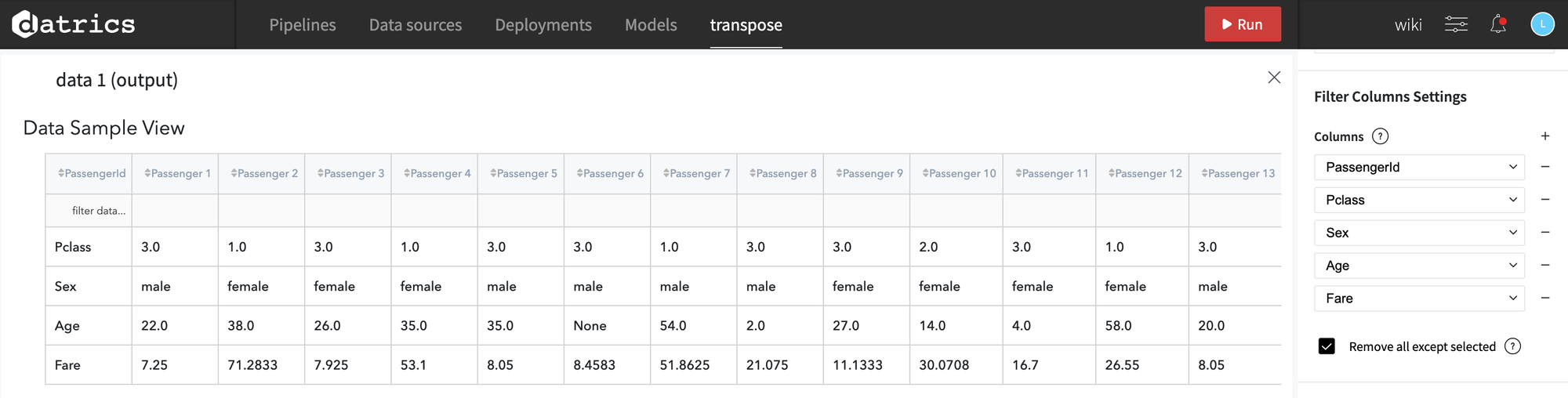
Each row in the first column corresponds to the names of the columns in the initial dataset, and the values from the first column in the initial dataset were used as identifiers of the resulted columns.