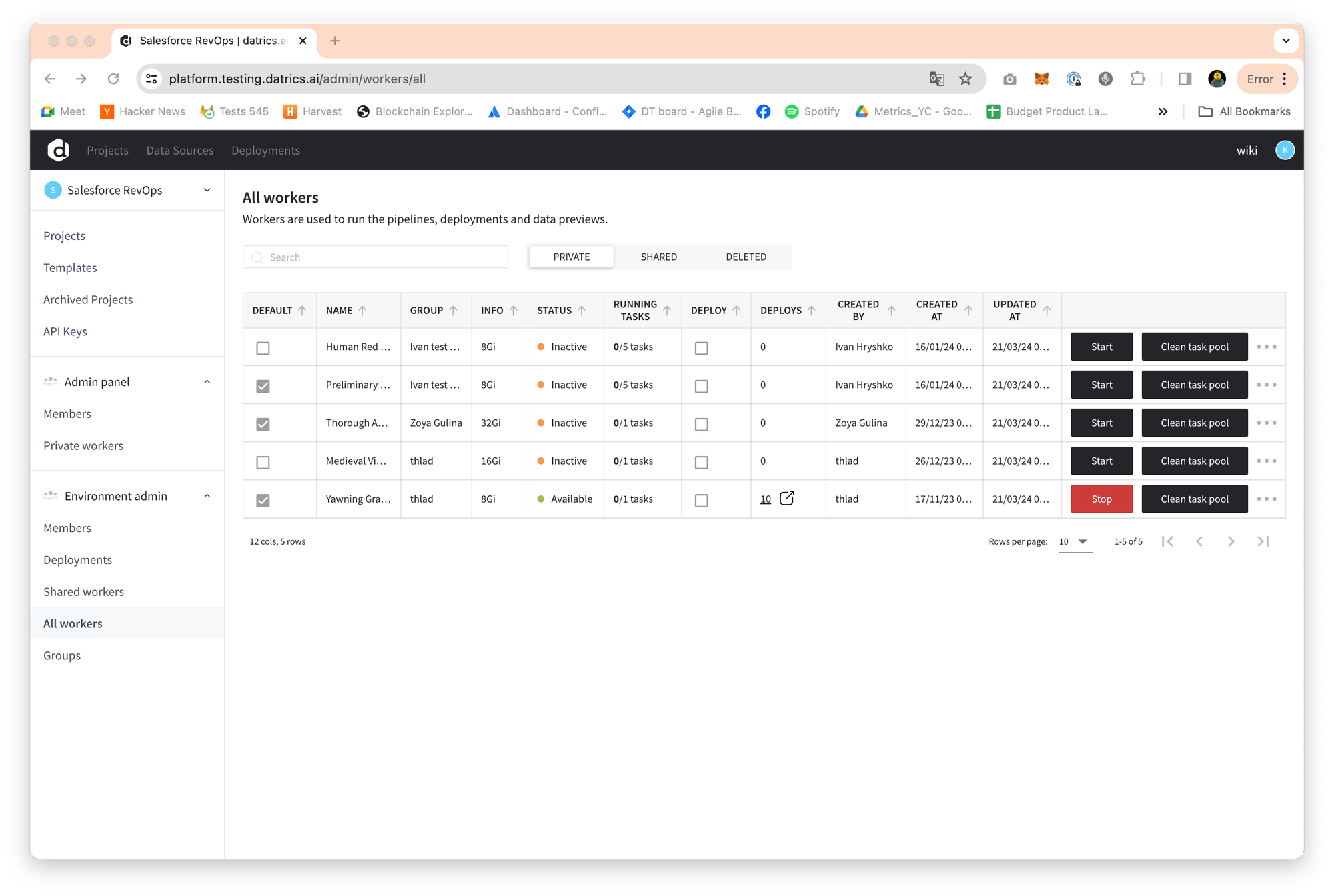
To use the "workers" functionality, users can create a new worker by selecting the size (for example, 16GB RAM and 1 GPU) and setting it to run tasks. The first worker is set as default but this can be changed, and the number of tasks running in parallel can be adjusted.
When running a data pipeline, the default worker will be used unless a different worker is specified. If the worker is deleted or stopped, the pipeline will run on the default worker.
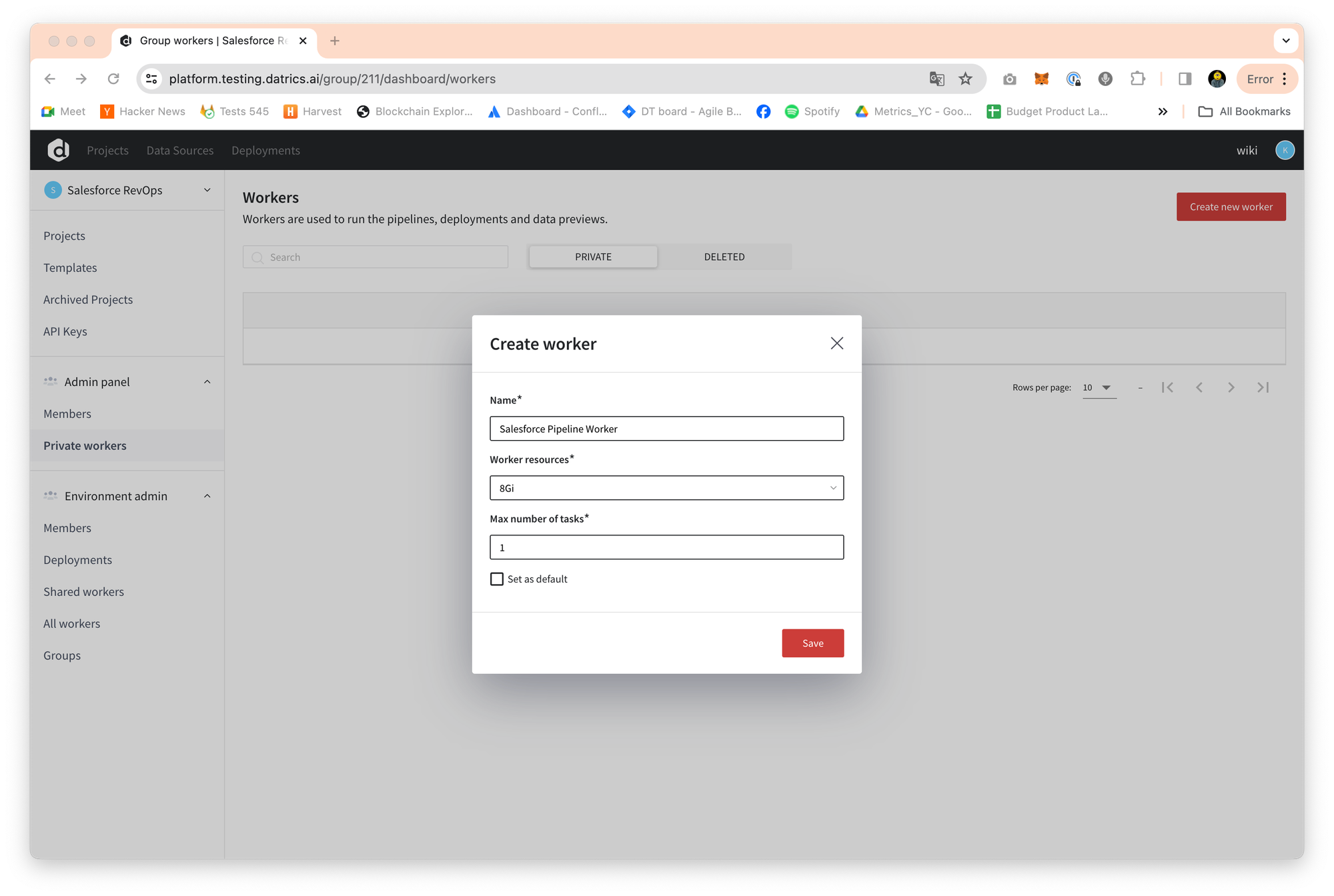
You can manage workers by deleting, stopping/starting, and editing them. However, workers used for deployments cannot be deleted, and workers with tasks running cannot be deleted or stopped.
For deployments, the worker should be selected at the time of deployment, and it cannot be deleted while in use.
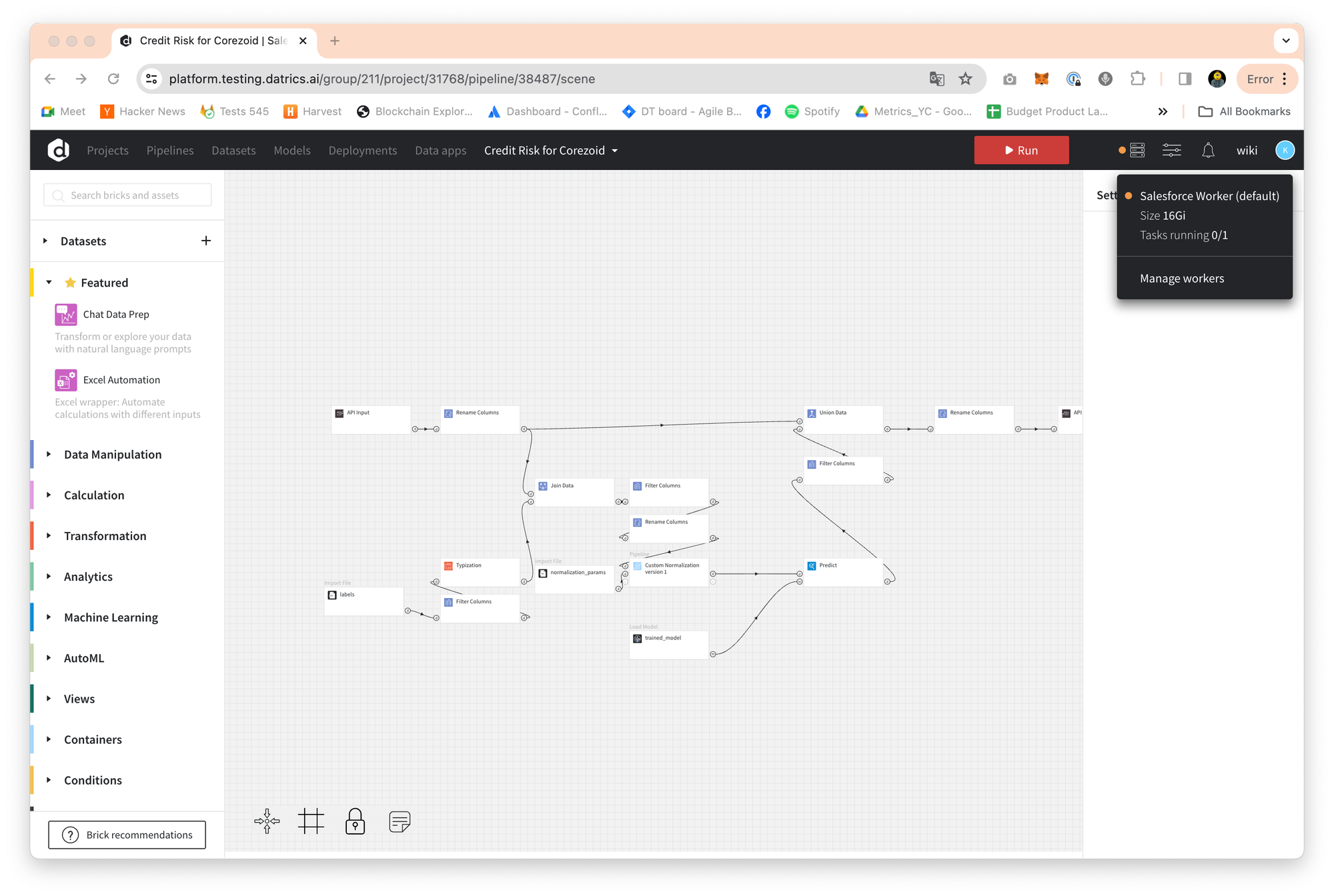
Workers can be paused during periods of inactivity, typically during night hours, to save on machine time costs. This is especially helpful for resource-intensive tasks, such as model training, where a larger worker can be initiated and then paused when it's no longer required.
In enterprise environments, workers can run on GPUs. In this case, the system administrator should spin up the appropriate node in the Kubernetes cluster.