General information
Brick provides a possibility to compare the values in the column of the input dataset against another custom value or values from another column from the same or different dataset.
Description
Brick Locations
Bricks → Data Manipulation → Transform → Compare Data
Bricks → Analytics → Data Insights → Compare data
Brick Parameters
- Setting
- Compare column against a value
- Compare column against another column from the same dataset
- Compare column against another column from a different dataset
List of possible actions to perform.
In this parameter you can specify one of the following treatment strategies:
- Column that is compared
List of possible columns for single selection from the input dataset which you want to compare.
This field is obligatory for any setting selected.
- Operator
- greater than (>)
- greater than or equal to (>=)
- less than (<)
- less than or equal to (<=)
- equal to (==)
- not equal to (!=)
- starts with
- ends with
- contains
- is contained in
List of possible comparison operators to apply.
Regardless of the selected setting, you can choose one of the following operators:
For numeric columns:
For text columns:
- Value
Additional parameter required for setting Compare column against a value.
Custom value to be compared with. For the comparison with empty and infinite values, please use NA and Inf correspondingly.
- Column to compare with
Additional parameter required for setting Compare column against another column from the same dataset or Compare column against another column from a different dataset.
List of possible columns from the same or different dataset for single selection which you want to compare with.
- New column name
The name of the output column where the comparison results will be written.
Note, that you may specify the existing column as an output one, in this case, its values will be overwritten.
Brick Inputs/Outputs
- Inputs
Brick can take one or two datasets as the input.
Note, that for the settings Compare column against a value and Compare column against another column from the same dataset it is necessary to provide only one input dataset, while for the setting Compare column against another column from a different dataset it is required to supply the brick with two datasets (both data and optional data inputs).
- Outputs
Brick produces the result dataset based on the input dataset and parameter New column name.
Thus, in case the specified parameter New column name do not repeat the name of the column that is already present in the input data, the result will be an extended input dataset with one additional column with the results of comparison.
Otherwise, the output dataframe will be with the same shape as input dataset where one of the columns will be overwritten with the results of comparison.
Example of usage
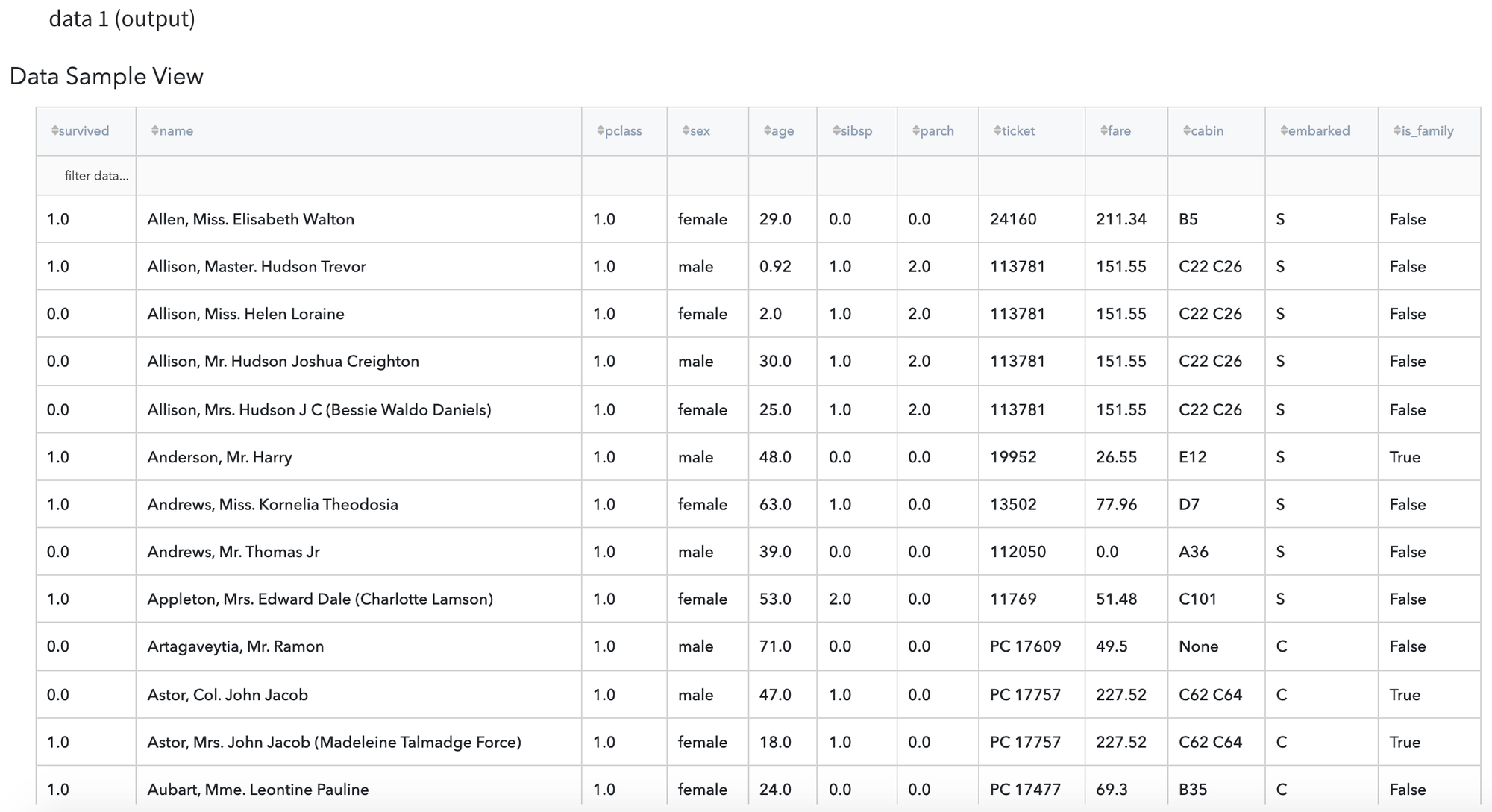
Let us explore the brick Compare data with all possible settings.
For demonstration, let us consider the Titanic dataset, which subset is presented below:
Setting 1: Compare column against a value
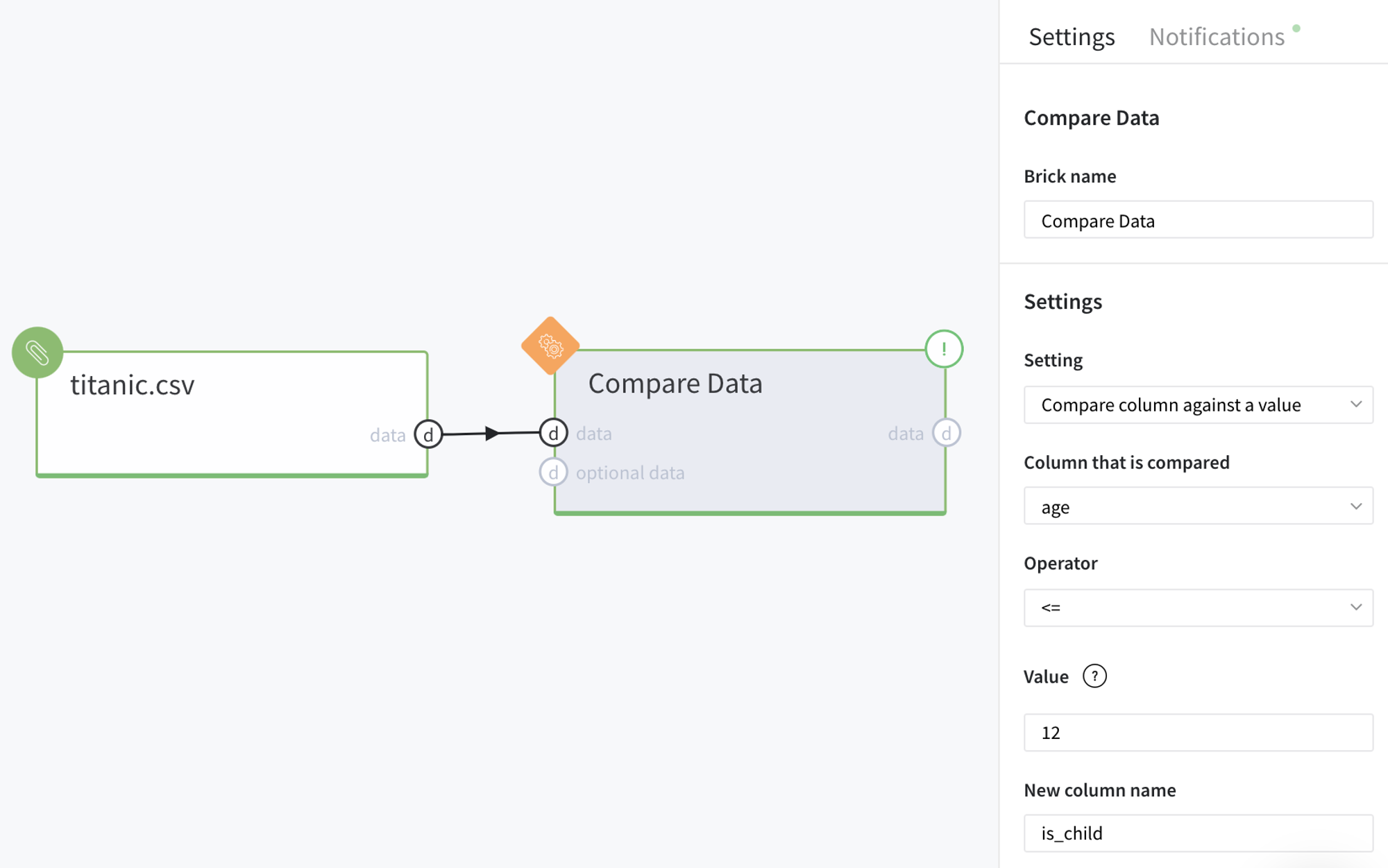
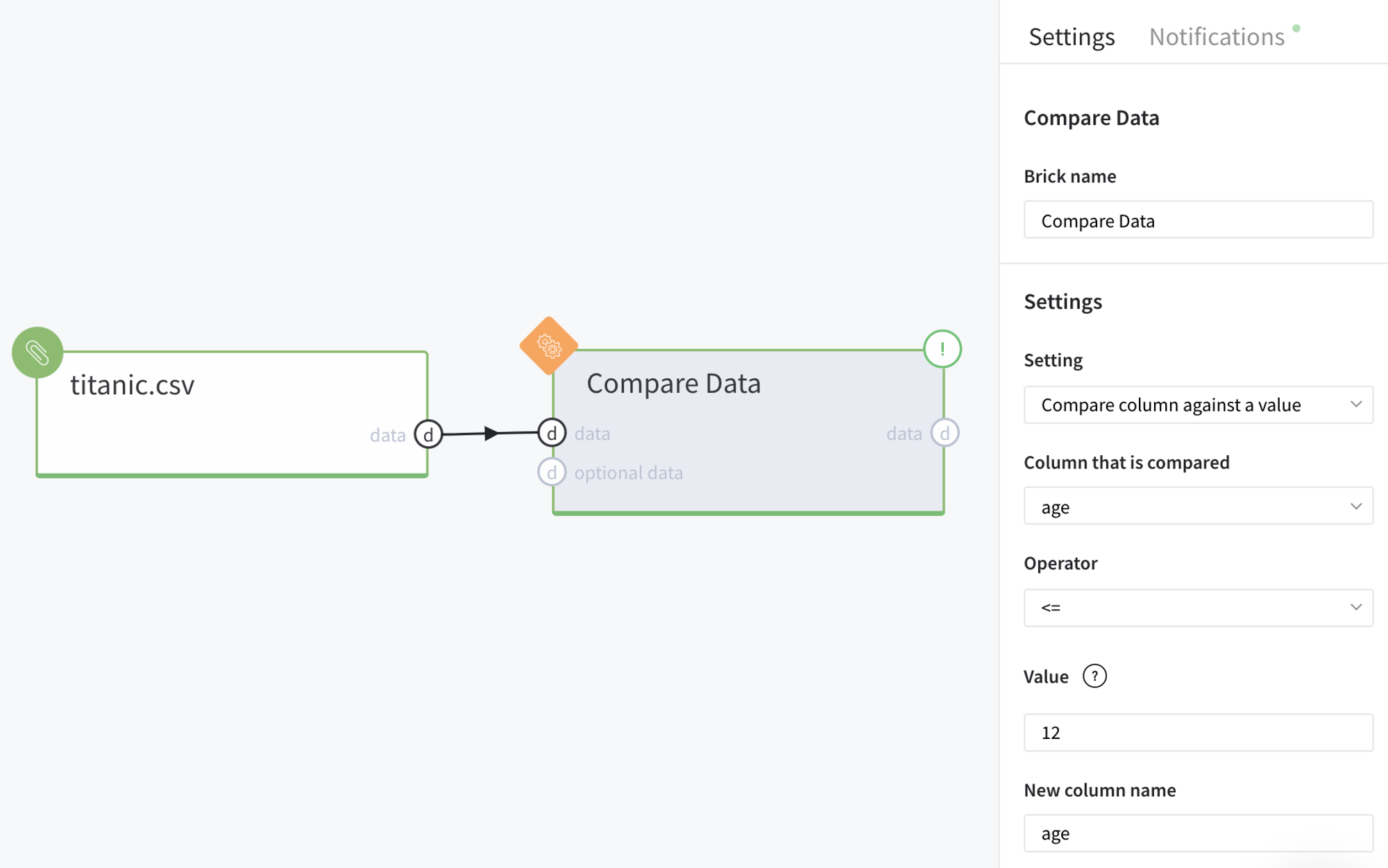
Imagine, we want to create a new boolean feature is_child based on the existing variable age indicating whether the person from our dataset is a child (not above 12 years old) or not.
For this purpose, first of all, we load and connect the dataset and Compare data brick on the scene, so we can configure the brick parameters as follows:
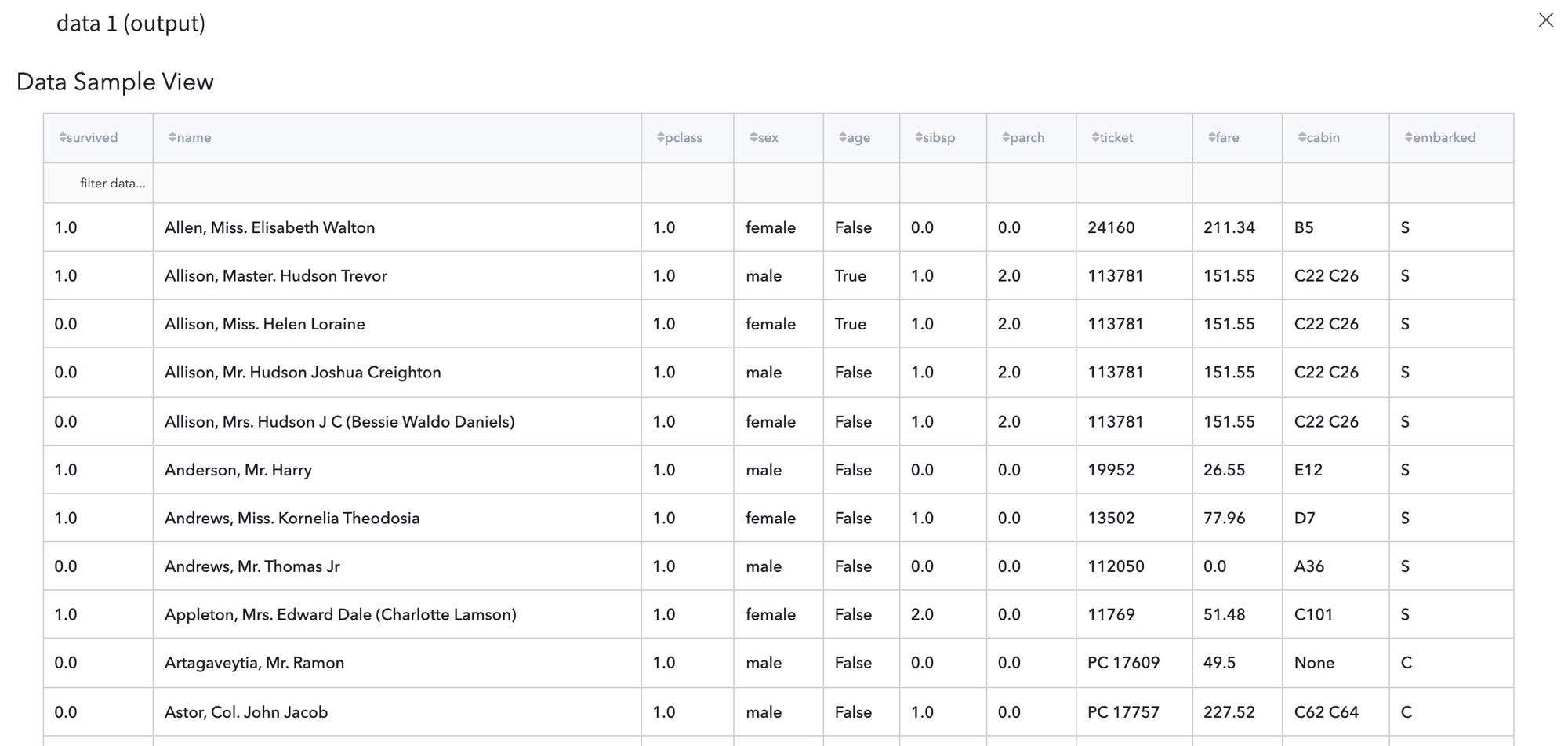
After running the pipeline we should obtain the result in the new column is_child:
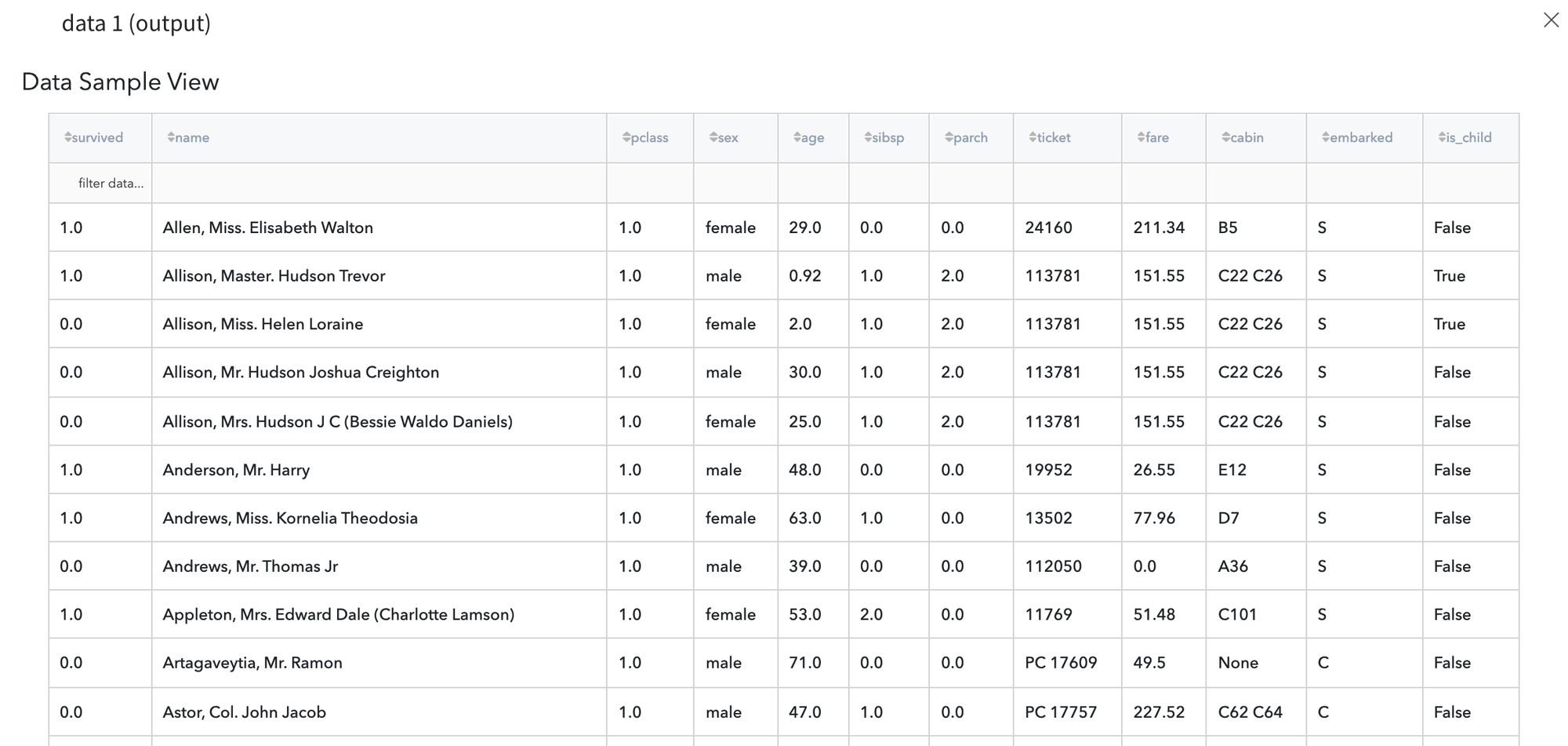
Note, in case we specify the New column name value the same as Column that is compared, the defined column will be overwritten:
Setting 2: Compare column against another column from the same dataset
Now, let us illustrate how comparison of two different columns inside the same dataset works.
For example, we want to check whether the ticket number is dependent on name of the embarkation port. First of all, let us simply validate whether the values in ticket column start from the letter that identifies the corresponding port name (column embarked). In this case, the brick parameters will be as follows:
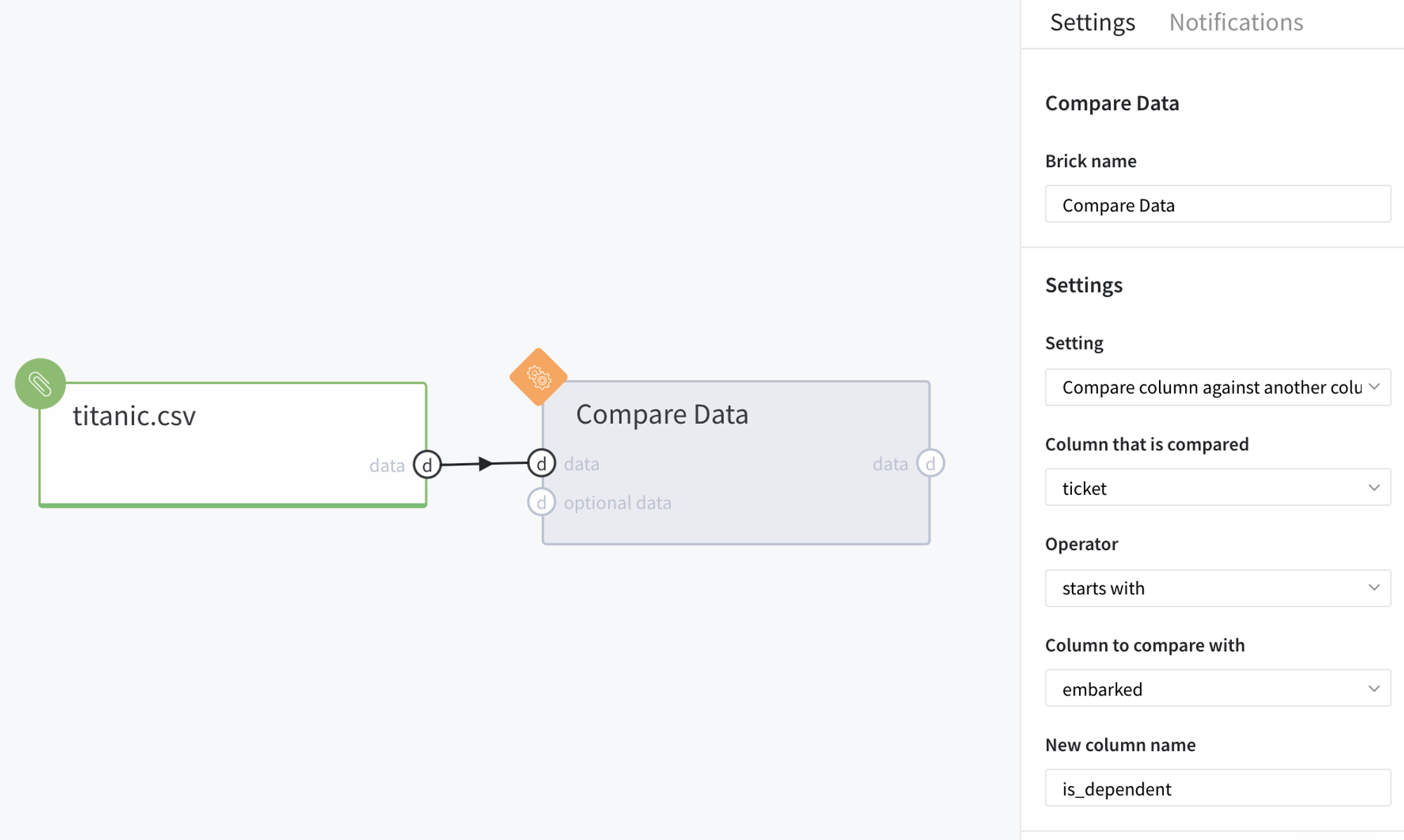
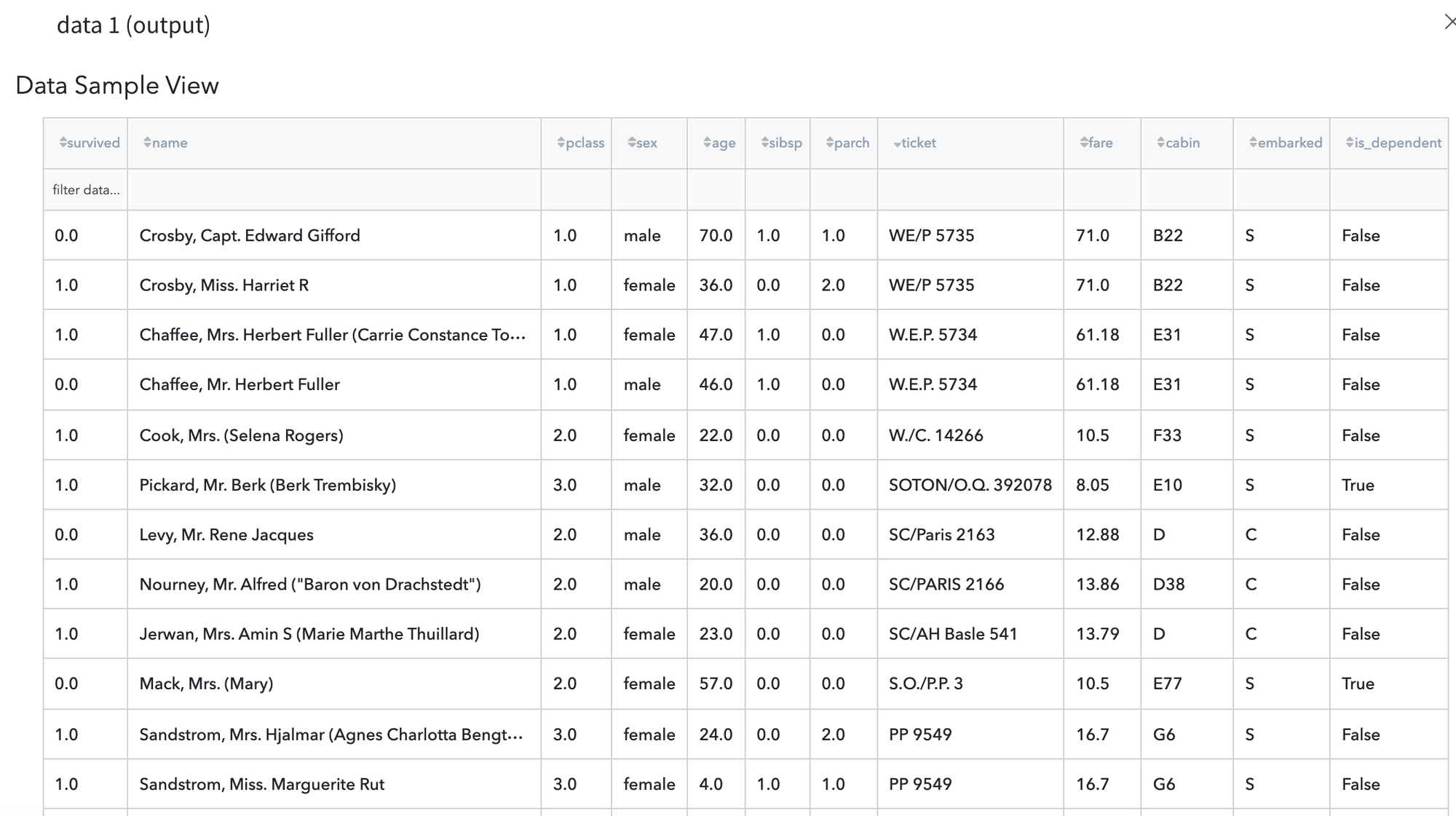
After running the pipeline we should obtain the following results:
Setting 3: Compare column against another column from a different dataset
For demonstrating the last setting we, firstly, create a new one-column dataframe using Create a New Column brick with a few family names:
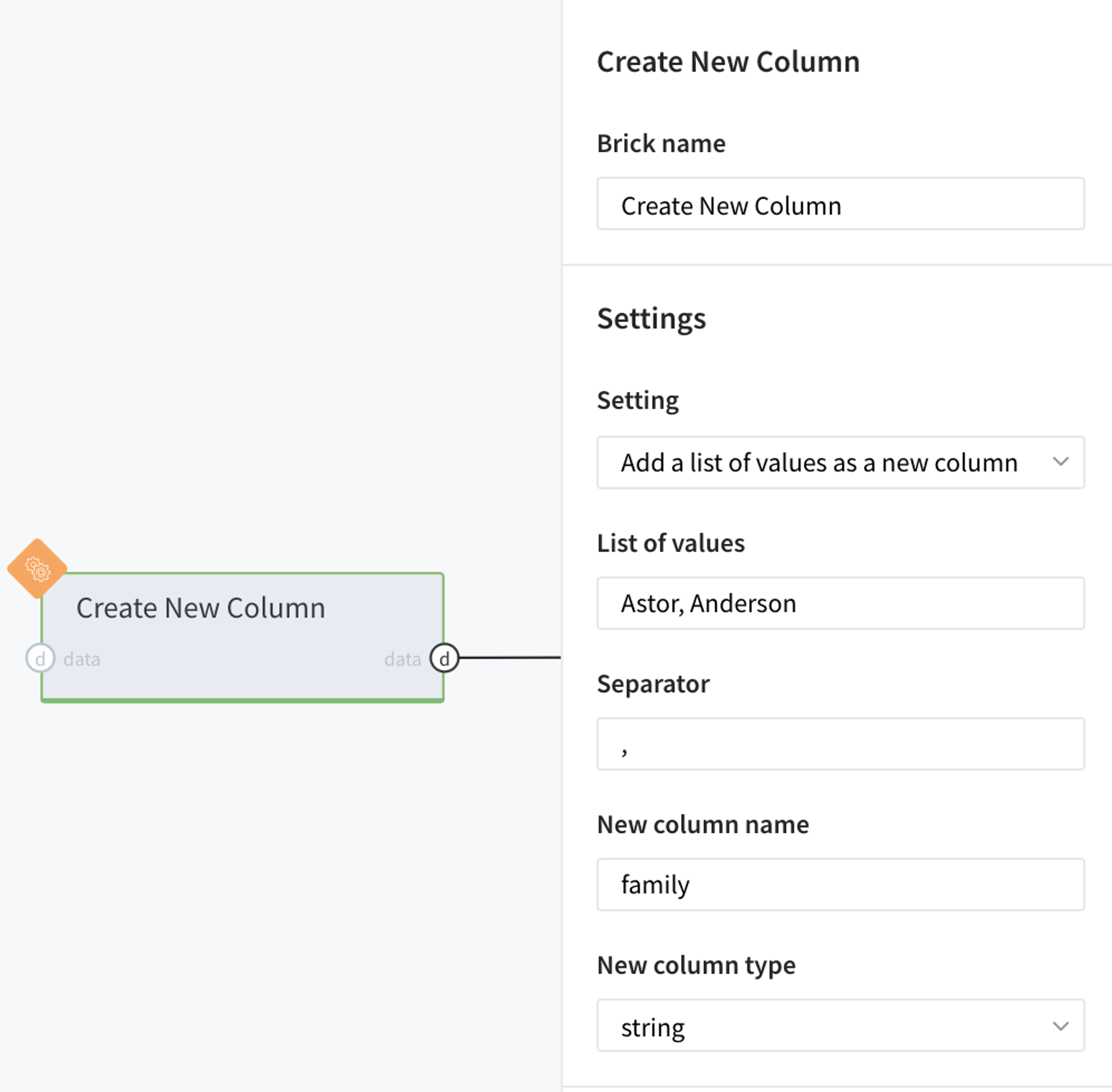
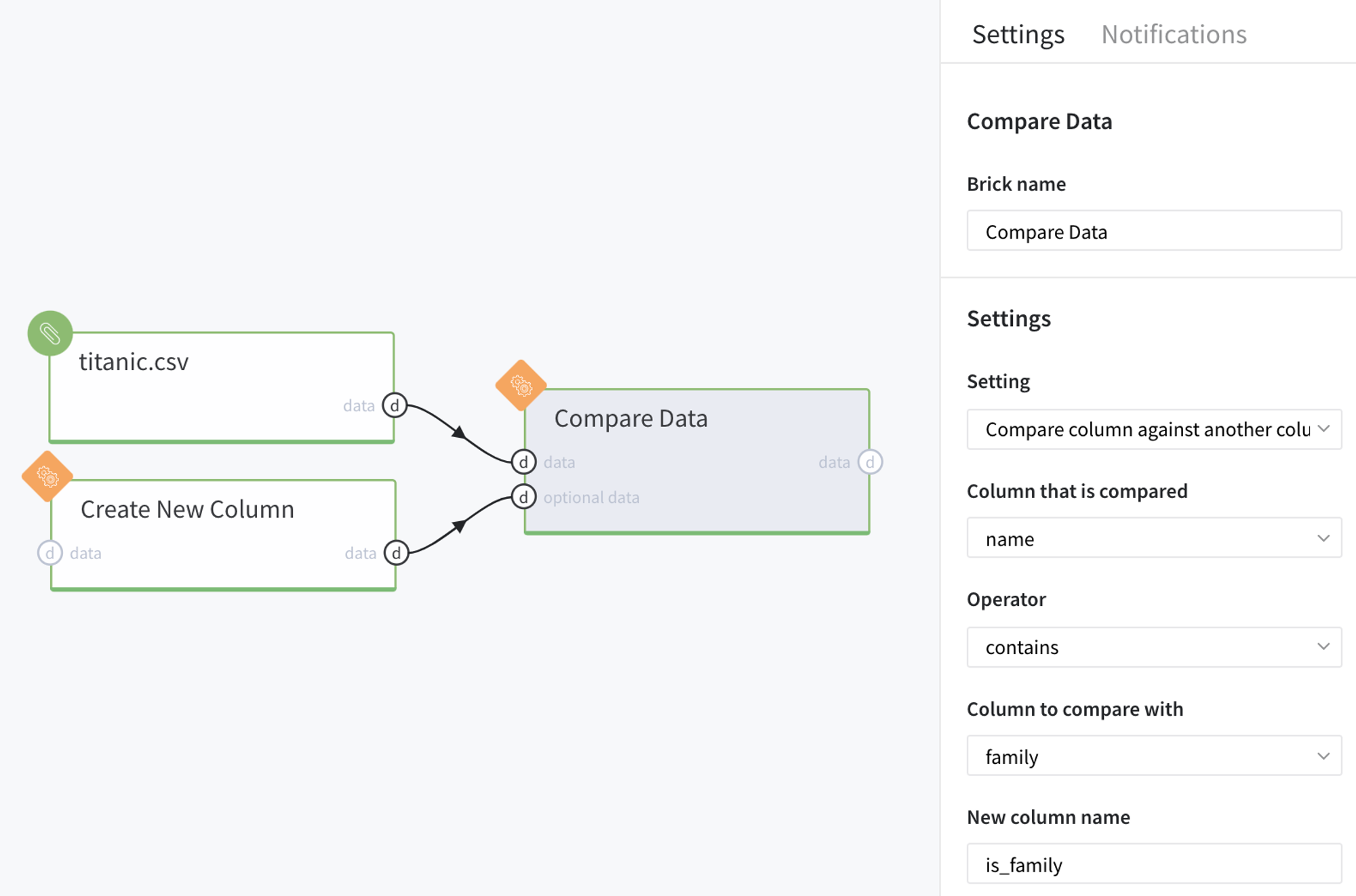
Using this custom dataset, let us check is there any person in our main Titanic data who belongs to one of these families (Astor or Anderson).
To do so, we should connect both these datasets to the Compare data brick with the next settings:
That should lead us to the following results: