General information
Brick provides a tool to encode categorical data to numerical type.
This action is needed if your data set contains strings, which cannot be processed by most machine learning algorithms. In addition, this helps to decrease computational resource usage (numerical types are processed faster than strings), therefore slightly speeding up large pipelines.
Brick supports 3 types of encoding: one-hot, binary and label
One-hot encoding
A one-hot encoding is appropriate for categorical data where no relationship exists between categories. It involves representing each categorical variable with a binary vector that has one element for each unique label and marking the class label with a 1 and all other elements 0.
For example, if our variable was “color” and the labels were “red,” “green,” and “blue”, we would encode each of these labels as a three-element binary vector as follows:
- Red: [1, 0, 0]
- Green: [0, 1, 0]
- Blue: [0, 0, 1]
Therefore, every label in data set will be replaced with such vectors, where one column transforms to N-different columns (N is a number of unique values in the column)
Label and binary encoding
These types of encoding involve mapping each unique label to an integer value. Because of that, it is sometimes refereed as an integer encoding (or ordinal encoding as well).
For example, if our variable was “color” and the labels were “red,” “green,” and “blue”, we would encode this variable as follows:
Color: [0, 1, 2]
The only difference between label and binary encoding is that binary supports only columns with two unique values and is more suitable for working with boolean values.
Description
Brick Location
Bricks → Data Manipulation → Transform → Encoding
Bricks → Analytics → Features Engineering → Encoding
Bricks → Use Cases → Demand Forecasting → Data Processing → Encoding
Brick Parameters
- Columns to encode
- one-hot encoding (Please note that column can be one-hot encoded only if it contains no more than 10 unique values)
- label encoding
- binary encoding (Please note that this encoding supports only columns with 2 unique values in it)
List of the column-encoding pairs. In the first output you can select one of the possible columns and in the second you specify one of the following encoding types:
In addition, it is possible to choose several column-encoding pairs by clicking on the '+' button in the brick settings.
Be warned, that specified columns will be overwritten or removed.
- Brick frozen
This parameter enables the frozen run for this brick. It means that all labels will save their current categorized value for the next runs, which would be useful after pipeline deployment where some classes in new data samples could be absent or could come in a different order.
This option appears only after successful regular run.
Note that frozen run will not be executed if new data contains previously unseen data values.
Brick Inputs/Outputs
- Inputs
Brick takes the data set with categorizable data points.
- Outputs
Brick produces the result as a new dataset. Columns with label or binary encoding will be overwritten, while one-hot encoding will generate new column for every unique value (original column will be deleted).
Example of usage
Let's consider the binary classification problem Binary classification : Titanic:
The inverse target variable takes two values - survived (0) - good or non-event case / not-survived (1) - bad or event case. The general information about predictors is represented below:
- passengerid (category/int) - ID of passenger
- name (category/string) - Passenger's name
- pclass (category/int) - Ticket class
- sex (category/string) - Gender
- age (numeric) - Age in years
- sibsp (numeric) - Number of siblings / spouses aboard the Titanic
- parch (category/int) - Number of parents / children aboard the Titanic
- ticket (category/string) - Ticket number (contains letters)
- fare (numeric) - Passenger fare
- cabin (category/string) - Cabin number (contains letters)
- embarked (category/string) - Port of Embarkation
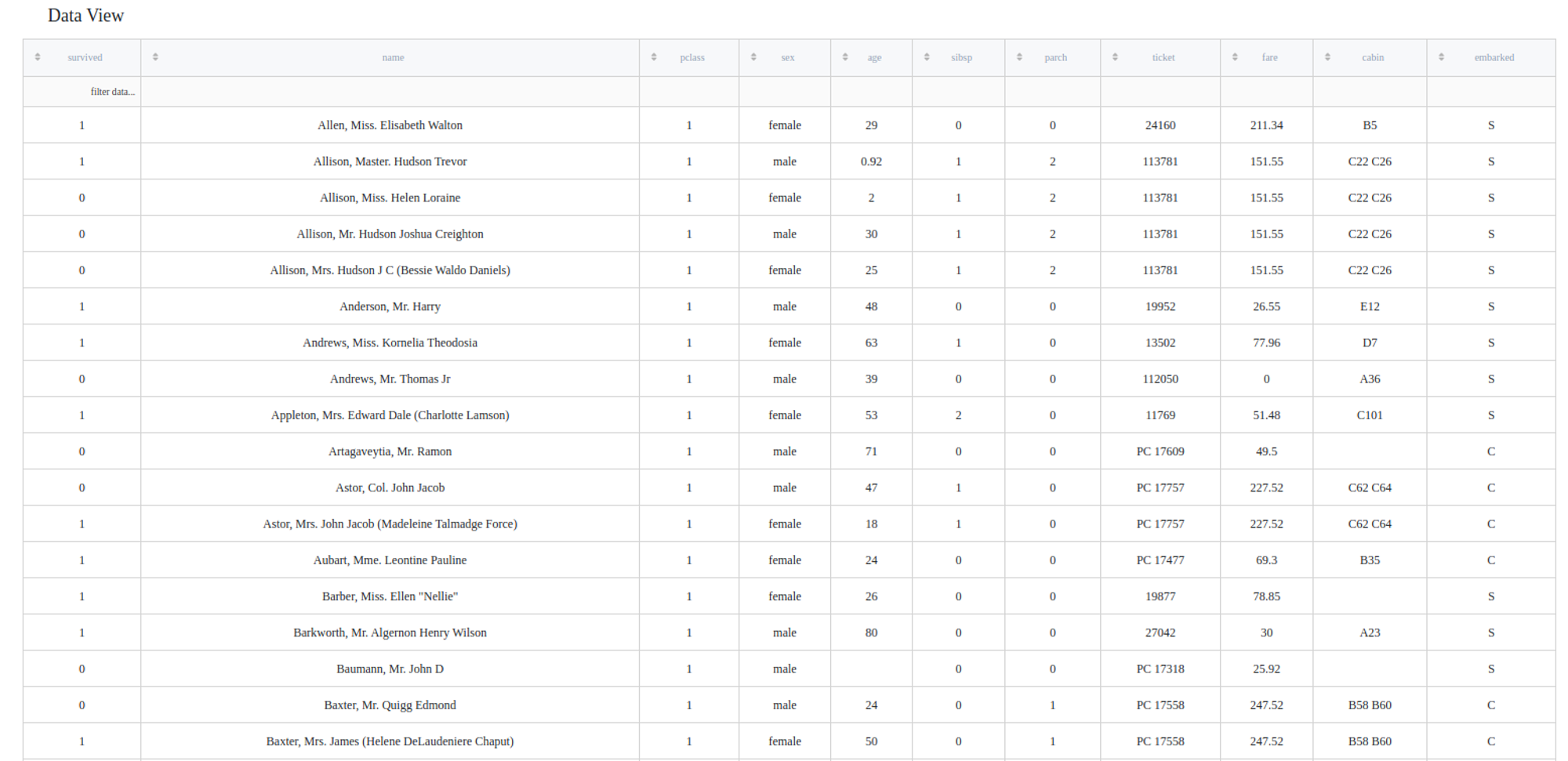
As was mentioned in the "General Information" section, most models do not take any string data due to their inner mechanisms. From the predictors' description, we can see that some columns are not numerical: name, sex, ticket, cabin, embarked. These listed columns should be encoded the next way:
- name, ticket and embarked - should be label encoded due to the number of unique values.
- sex - should be binary encoded, because this column has only two unique values (so, one-hot and label may be used as well)
- embarked - this column contains 3 values and there are no relation between them, so it should be one-hot encoded
Executing regular pipeline run
Next steps would be made to build simple pipeline:
- First, drag'n'drop titanic.csv file from Storage→Samples folder and Encoding brick from Bricks →Data Preprocessing
- Connect titanic data set to our Encoding brick
- List all pairs defined before in 'Columns to encode' section (you can add additional pairs by pressing '+' symbol)
- Run pipeline
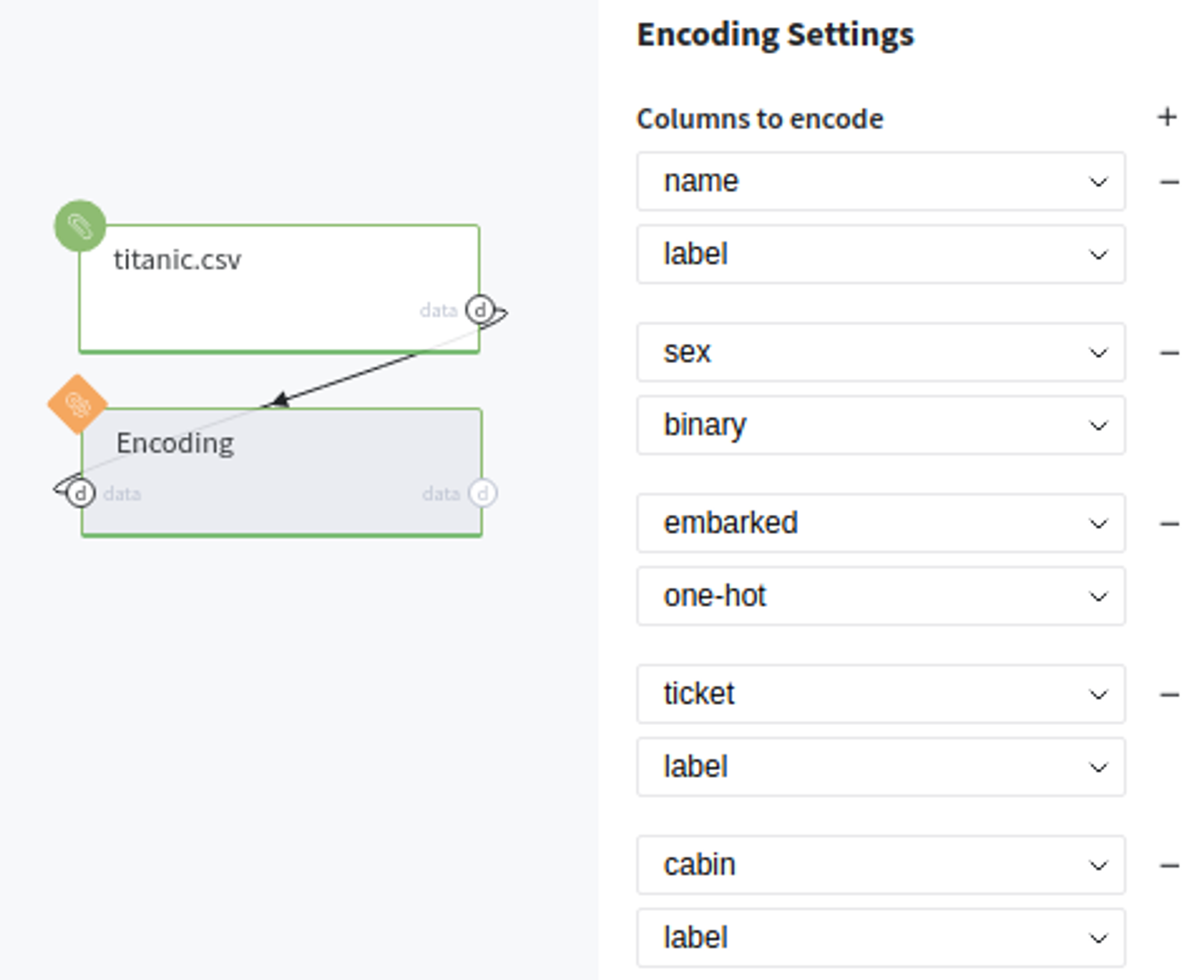
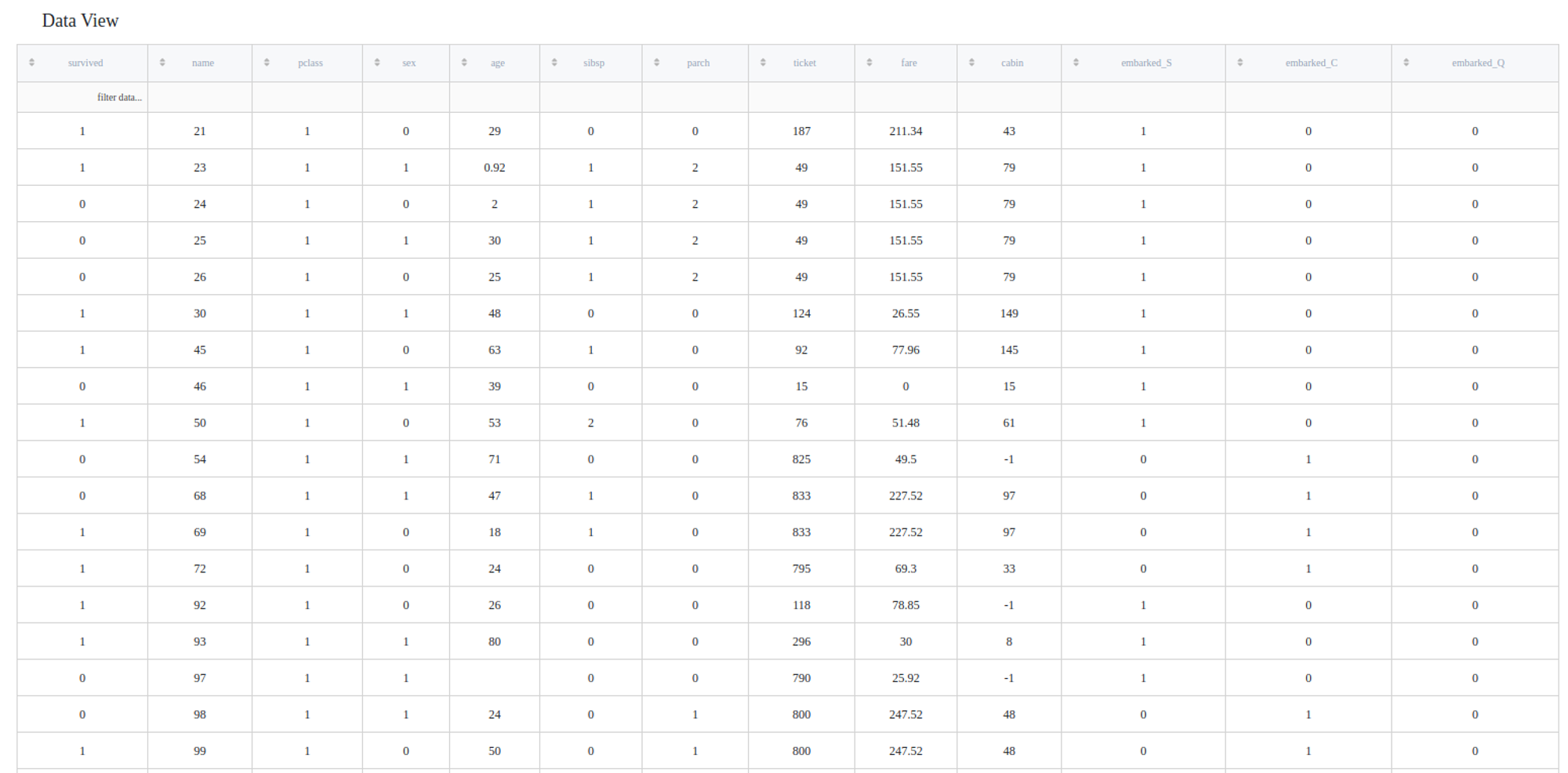
In order to see the assessment result, you should open the Output data previewer on the right sidebar.

The results are depicted in the table:
Executing frozen pipeline run:
After completing the previous steps you need to check the 'Brick frozen' options in the 'General Settings' section:

This ensures that every time we execute our pipeline, the encoded labels will stay the same even if the data is shuffled in a different way or some classes are absent. Please note, that brick will raise an error if previously unseen values are given.