General Information
This brick provides you with an easy interface for creating your own out-of-box and distributed gradient boosted decision tree for your regression tasks (if you need to solve a classification task, please, check LGBM Binary or LGBM Multiclass brick). Due to its leaf-wise processing nature, the created model can be easily trained on large datasets, while giving formidable results.
The models are built on three important principles:
- Weak learners
- Gradient Optimization
- Boosting Technique
In this case, the weak learners are multiple sequential specialized decision trees, which do the following things:
- the first tree learns how to fit to the target variable
- the second one learns how to fit the difference between the predictions of the first tree and the ground truth (real data)
- The next tree learns how to fit the residuals of the second tree and so on.
All those trees are trained by propagating the gradients of errors throughout the system.
The main drawback of the LGBM Binary is that finding the best split points in each tree node is both a time-consuming and memory-consuming operation.
Description
Brick Locations
- Bricks → Analytics → Data Mining / ML → Regression Models → LGBM Regressor
- Bricks → Use Cases → Demand Forecasting → Modelling → LGBM Regressor
Brick Parameters
- Learning rate
Boosting learning rate. This parameter controls how quickly or slowly the algorithm will learn a problem. Generally, a bigger learning rate will allow a model to learn faster while a smaller learning rate will lead to a more optimal outcome.
- Number of iterations
A number of boosting iterations. This parameter is recommended to be set inversely to the learning rate selected (decrease one while increasing second).
- Number of leaves
The main parameter to control model complexity. Higher values should increase accuracy but might lead to overfitting.
- Regularization
- Lasso Regression (L1) - Least Absolute Shrinkage and Selection Operator, is a type of linear regression that uses shrinkage. Shrinkage is where data values are shrunk towards a central point, like the mean. The lasso procedure encourages simple, sparse models (i.e. models with fewer parameters). This particular type of regression is well-suited for models showing high levels of multicollinearity or when you want to automate certain parts of model selection, like variable selection/parameter elimination. The cost function for Lasso regression is:
- Ridge Regression (L2) - (also known as Tikhonov regularization), ridge regression shrinks the coefficients and it helps to reduce the model complexity and multi-collinearity
- ElasticNet - linearly combines both the L1 and L2 penalties of the Lasso and Ridge methods.
Regularization is a technique used for tuning the function by adding penalty term in the error function, which helps overcome overfitting. The model supports the next types of regularization:
- Target Variable
The column that has the values you are trying to predict. Note that the column must contain exactly two unique values and no missing values, a corresponding error message will be given if done otherwise.
- Optimize
This checkbox enables the Bayesian hyperparameter optimization, which tweaks the learning rate, as well as the number of iterations and leaves, to find the best model's configuration in terms of metrics.
Be aware that this process is time-consuming.
- Disallow negative predictions
This checkbox forces the model to round up negative values to be equal to 0.
- Filter Columns
If you have columns in your data that need to be ignored (but not removed from the data set) during the training process (and later during the predictions), you should specify them in this parameter. To select multiple columns, click the '+' button in the brick settings.
In addition, you can ignore all columns except the ones you specified by enabling the "Remove all except selected" option. This may be useful if you have a large number of columns while the model should be trained just on some of them.
- Brick frozen
This parameter enables the frozen run for this brick. It means that the trained model will be saved and will skip the training process during future runs, which may be useful after pipeline deployment.
This option appears only after successful regular run.
Note that frozen run will not be executed if the data structure is changed.
Brick Inputs/Outputs
- Inputs
Brick takes the data set with a target column that has exactly two unique values.
- Outputs
- Data - modified input data set with added columns for predicted classes or classes' probability
- Model - trained model that can be used in other bricks as an input
Brick produces two outputs as the result:
Additional Features
- What-if This option gives access to the information for the Model Deployment service, as well as a possibility to call API using custom values.
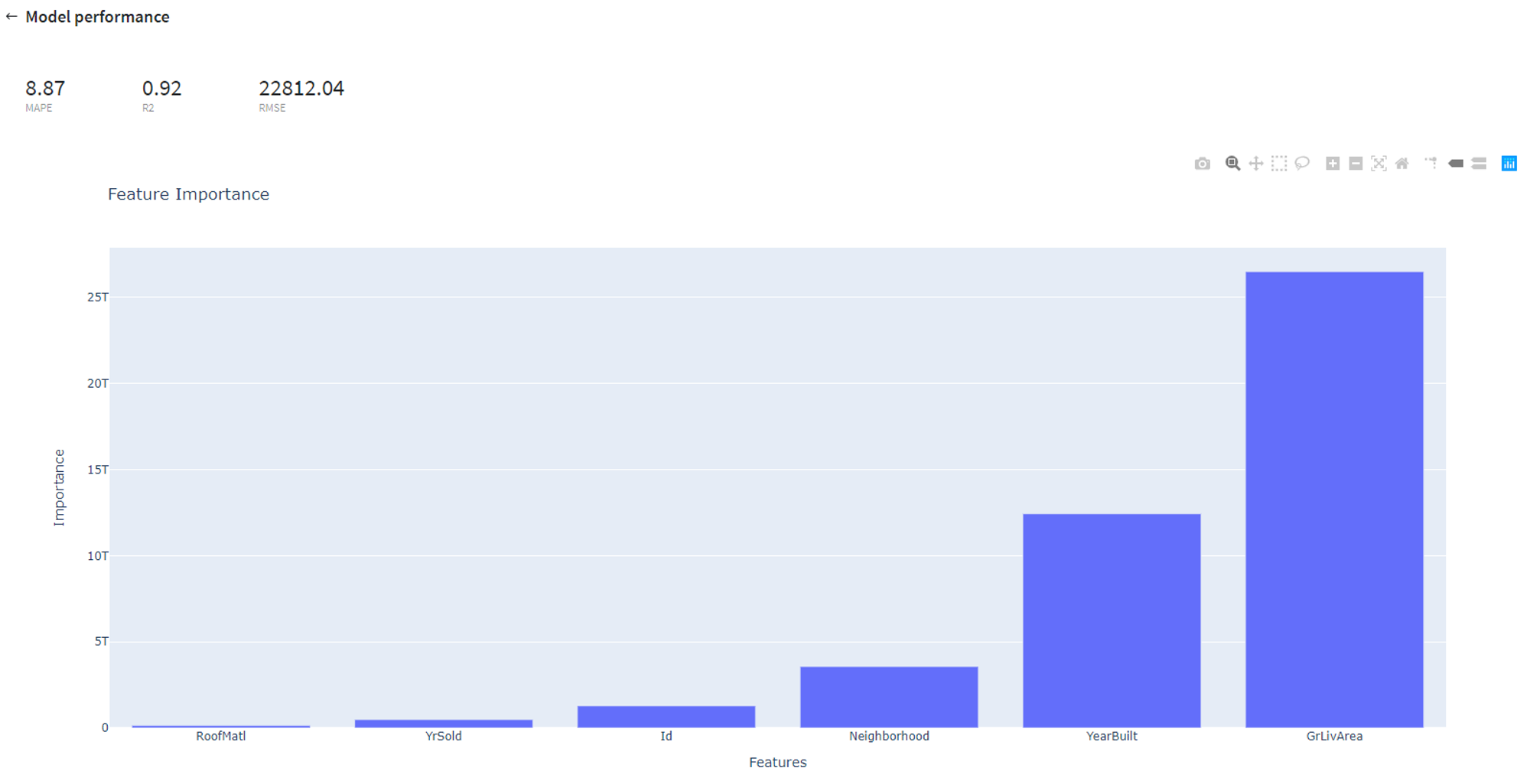
- Model Performance
This button (located in the 'Deployment' section) gives you a possibility to check the model's performance (a.k.a. metrics) to then adjust your pipeline if needed.
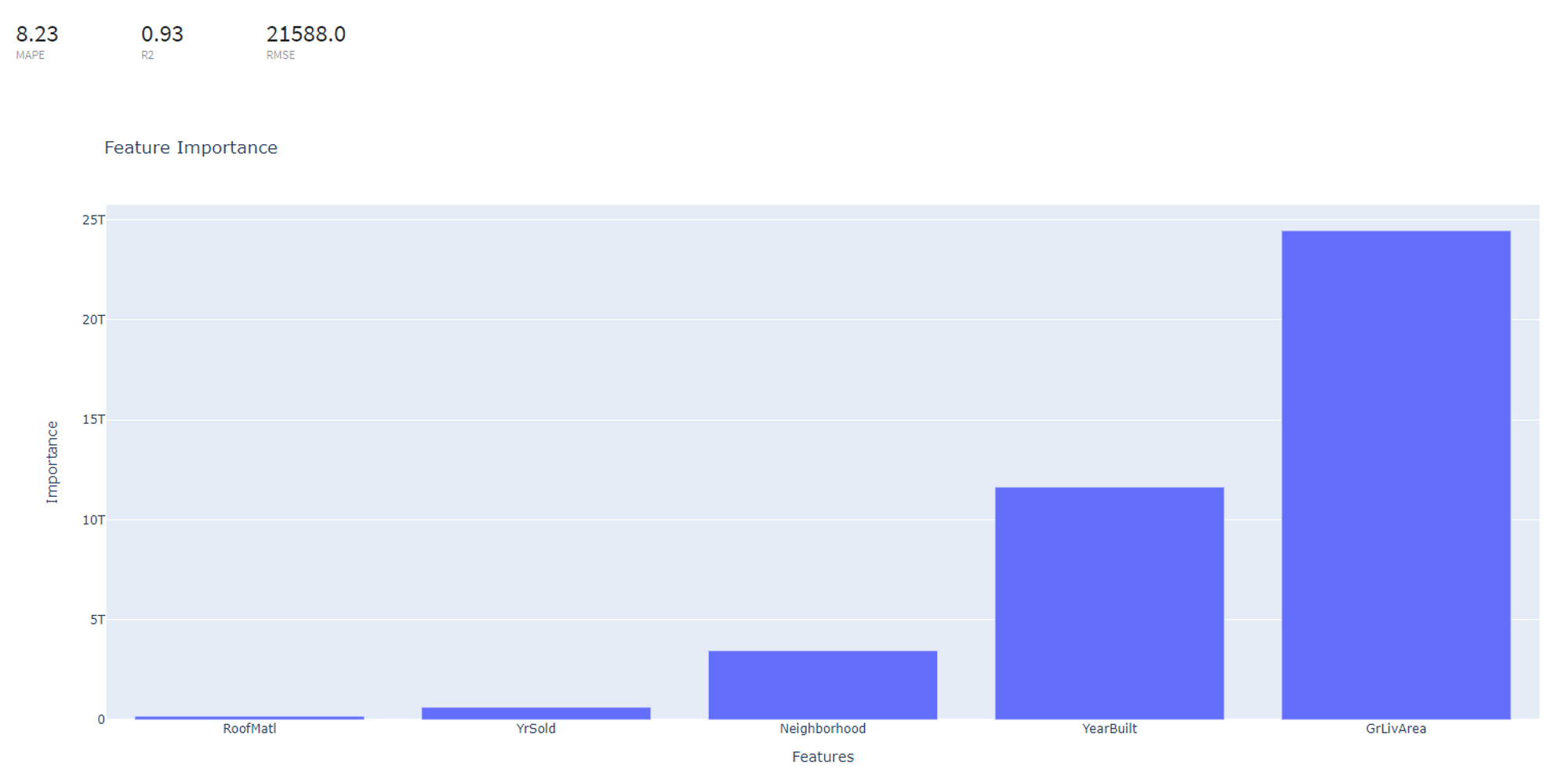
Supported metrics: MAPE (Mean average percentage error), R2, RMSE (root mean square error)
In addition, feature importance graph is provided in the dashboard.
- Save model asset
This option provides a mechanism to save your trained models to use them in other projects. For this, you will need to specify the model's name or you can create a new version of an already existing model (you will need to specify the new version's name).
- Download model asset
Use this feature, if you want to download model's asset to use it outside Datrics platform.
- Open metadata view By clicking this button you will be transported to the metadata view, which holds information about pipeline settings and utility data, such as package versions. Also, you can see the bricks configuration, where you have access to the information like bricks' inputs, outputs, status and arguments. Please note, that this view will only show the part of the pipeline that comes before the model, ignoring everything that comes after.
Example of usage
Let's consider a simple regression problem, where we know the characteristics of some houses and want to know their sale price. We have the next variables:
- Id (category/int) - Sale's ID
- Neighborhood (category/string) - House neighborhood name
- YearBuilt (int) - The year when a house has been built
- RoofMatl (category/string) - The materials used to construct the roof
- GrLivArea (int) - The living area
- YrSold (int) - The year when a house was sold
- SalePrice (int) - The price at which the house was sold. Target variable
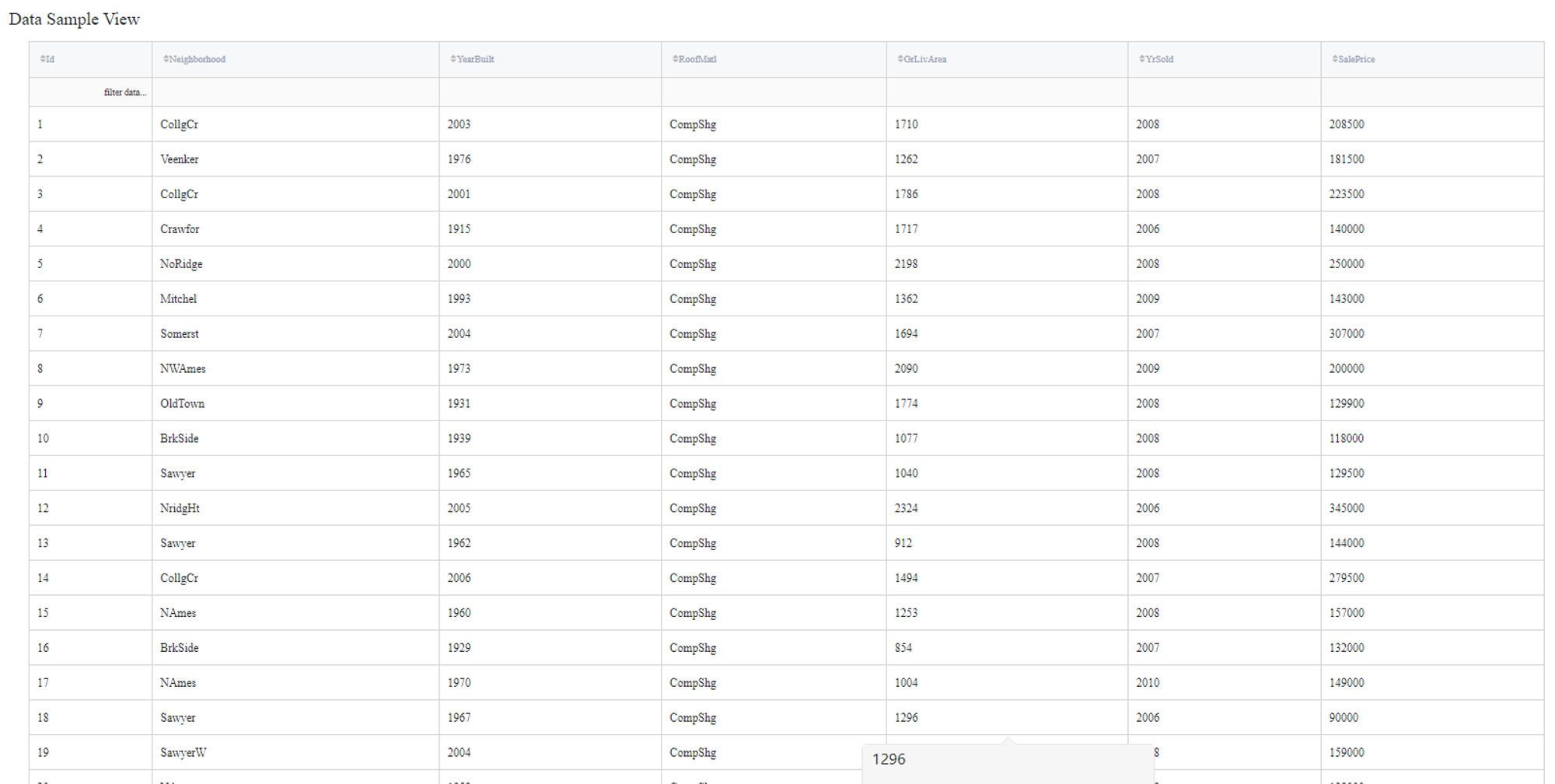
Some of the data columns are strings, which is not a supported data format for the LGBM Regression model, so we will need to label encode the next columns:
- Neighborhood - label
- RoofMatl - label
In addition, Id does not contain useful information, so they will be filtered out during the training.
Executing regular pipeline
Next steps would be made to build simple test pipeline:
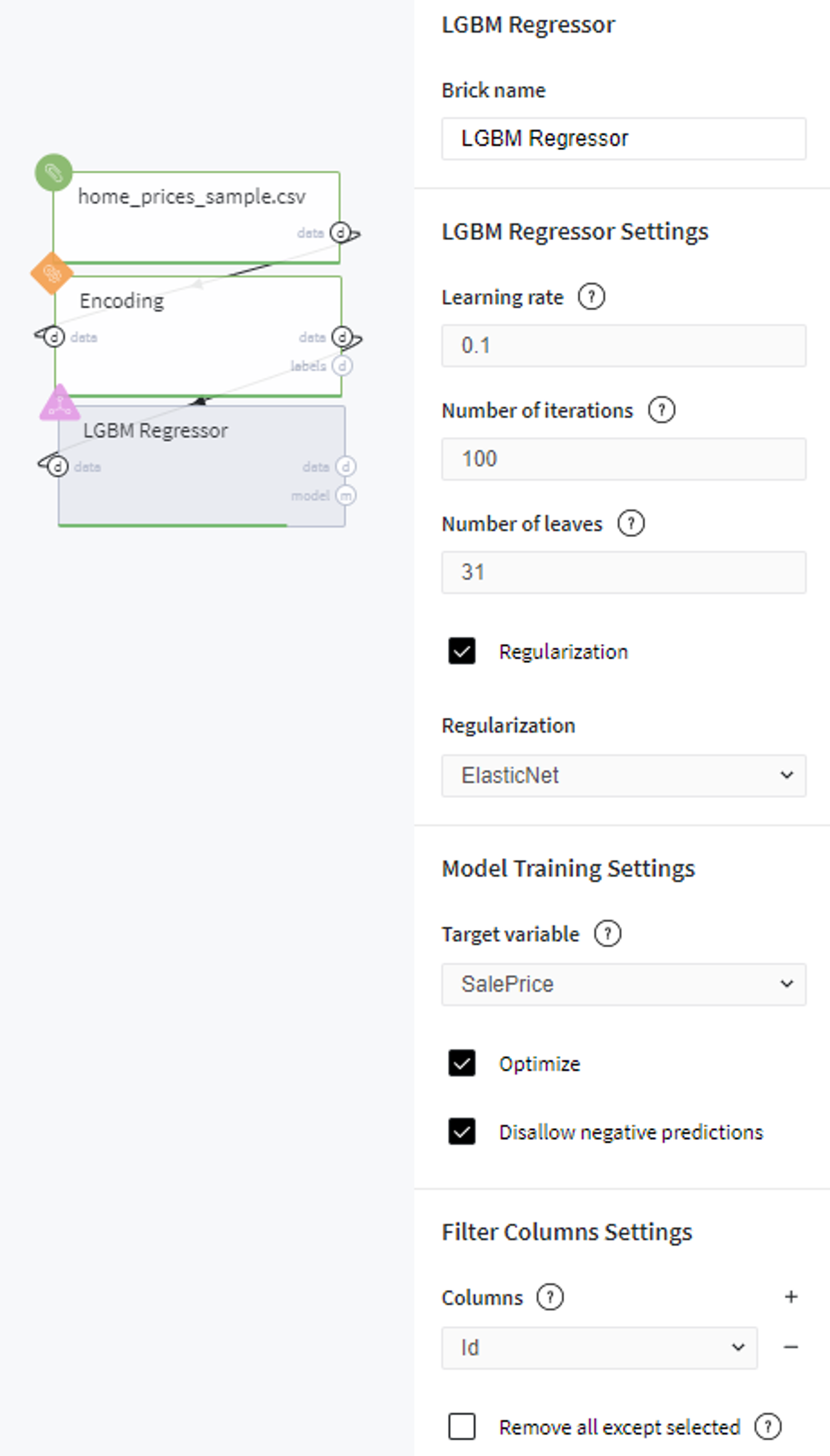
- First, drag'n'drop home_prices_sample.csv file from Storage → Samples folder, Encoding brick from the Bricks → Data Manipulation → Transform, as well as LBGM Regression from the Bricks → Analytics → Data Mining / ML → Regression Models
- Connect the data set to Encoding brick, set it up accordingly to the previous section and then connect to the LGBM Regression model
- Select the LGBM Regression brick, choose the ElasticNet regularization, specify the target variable (the SalePrice column) and the Id column to filter. Check the Disallow negative predictions to ensure that predictions will not be less than 0.
- Check the Optimize option if you like (note, it will take some time).
- Run pipeline
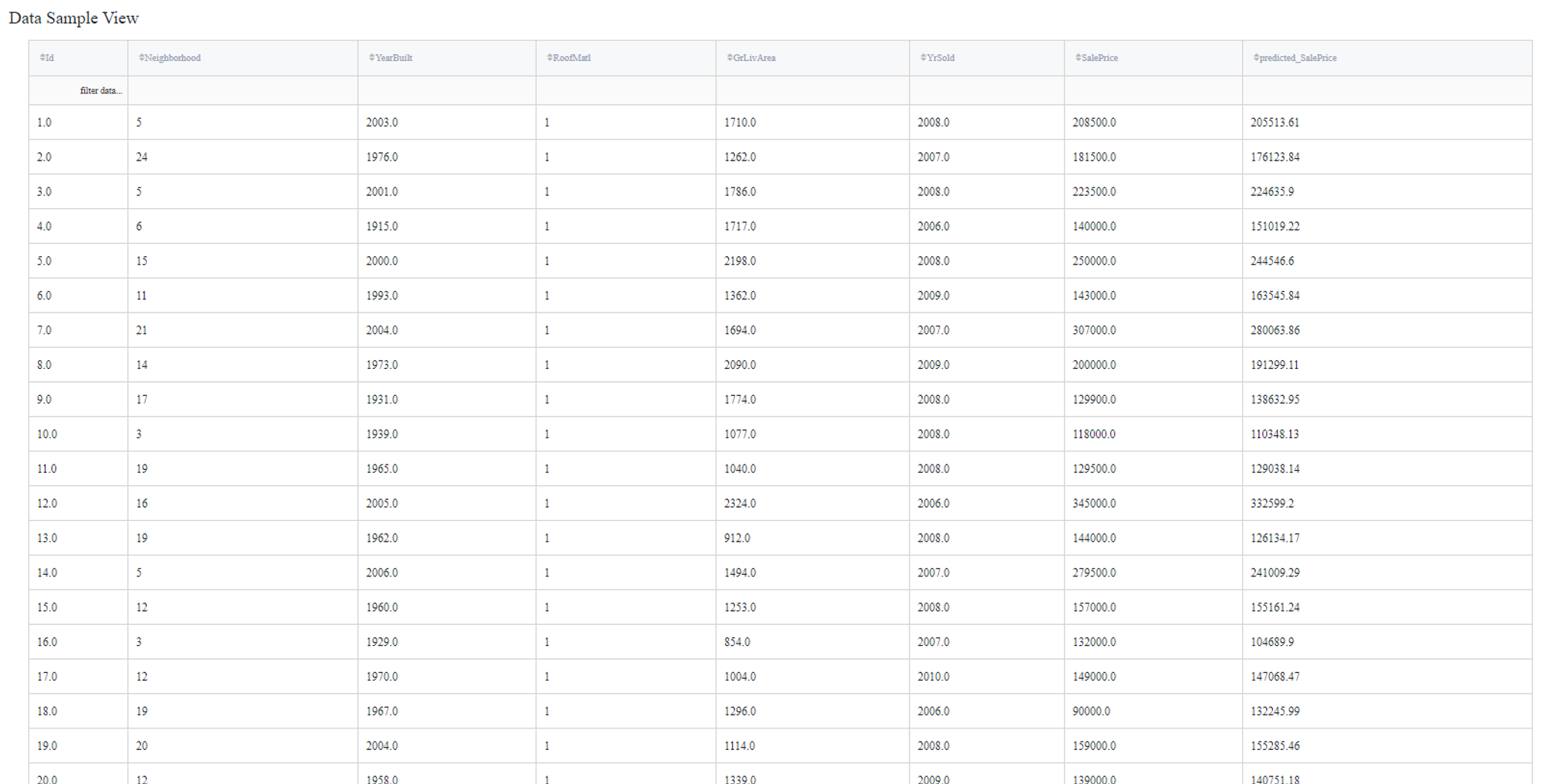
In order to see the processed data with new columns, you should open the Output data previewer on the right sidebar.

The results are depicted in the table:
To see the model's performance just choose the corresponding option in the Model Info section:
Executing frozen pipeline run:
After completing the previous steps you need to check the 'Brick frozen' options in the 'General Settings' section:

This ensures that every time we execute our pipeline, the LBGM Regression brick will load already trained during previous runs model, which may be useful during the deployement. Please note, that brick will raise an error if the data structure will be changed.