General information
This brick is used to combine two datasets into a single one.
Description
Brick Locations
Bricks → Data Manipulation → Union Data
Brick Parameters
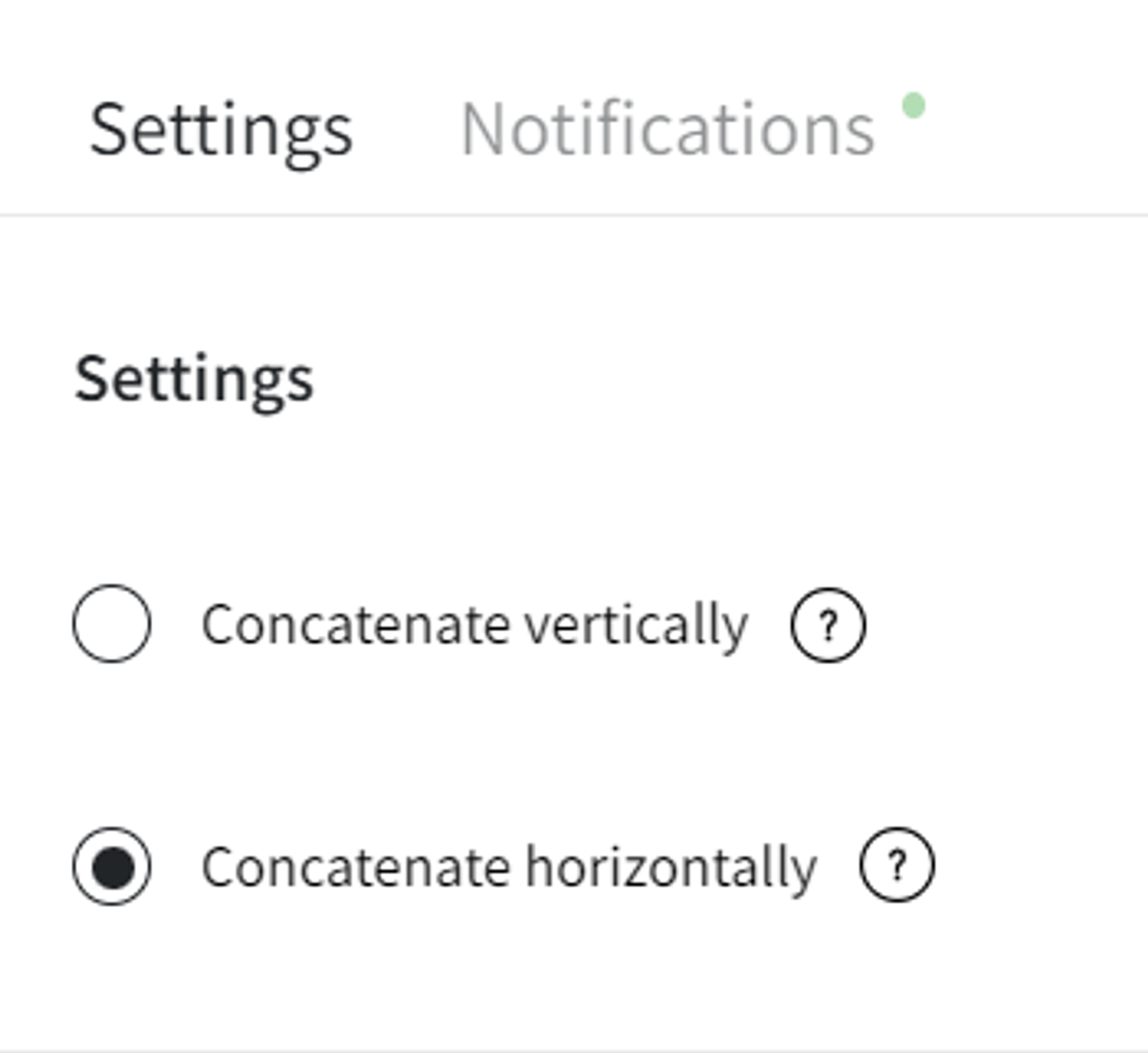
- Settings (Concatenate vertically/Concatenate horizontally)
Vertically means two datasets are stacked "one top of each other", the brick checks whether the column names and types match and are in the same order in both datasets.
Horizontally means two datasets are stacked "side by side", the brick checks whether the number of rows in the datasets is the same. If there are columns with the same name, corresponding columns will get "_X" and "_Y" suffixes.
Brick Inputs/Outputs
- Inputs
Brick takes two datasets
- Outputs
Brick produces one united dataset
Example of usage
Let’s have a look at the usage of the Union Data Brick.
We can use the ‘titanic.csv’ dataset, split the data into train and test sets with the Split Data Brick, and perform vertical concatenation to get the initial dataset.
Everything successfully worked as both input datasets have the same column names in the same order.
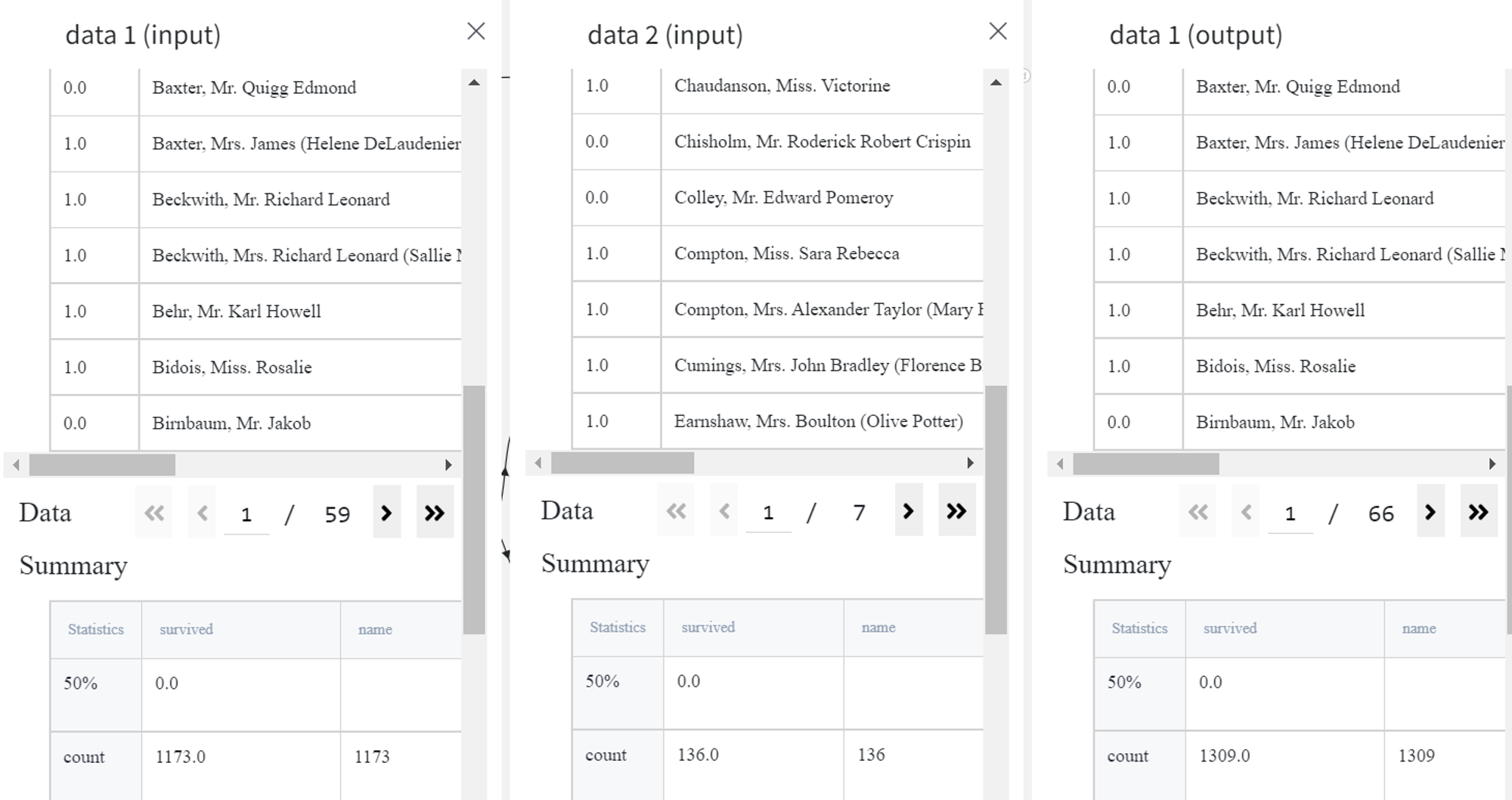
Let’s also try out the horizontal concatenation on the same dataset.
We can remove all columns except for the ‘name’ column with Filter Columns Brick and apply Union Data with horizontal concatenation.
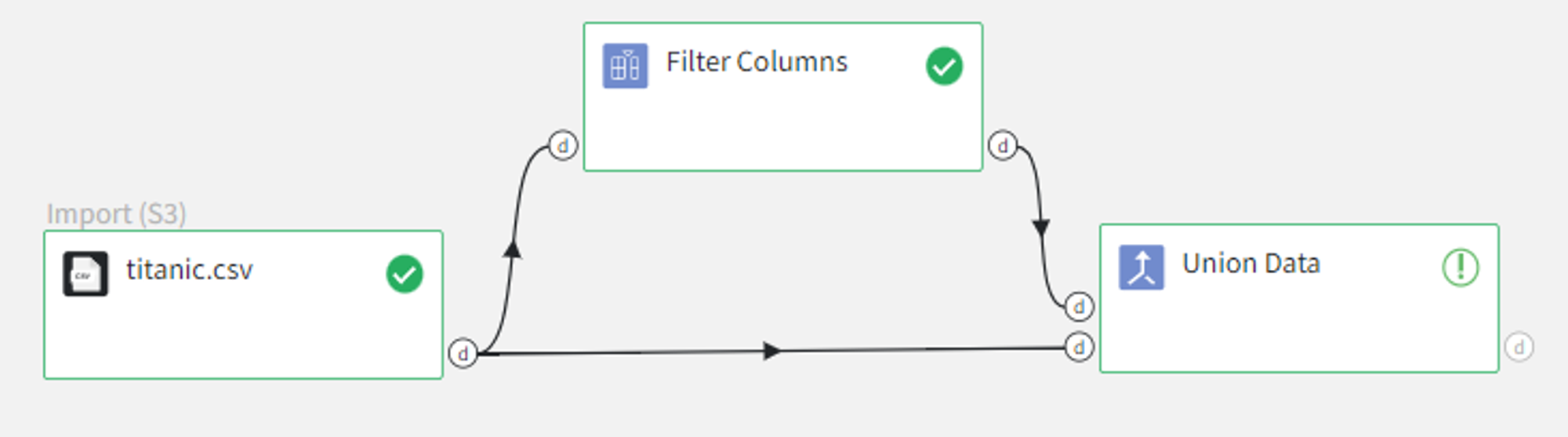
As both input datasets contain ‘name’ columns, the resulting dataset will contain columns ‘name_X’ and ‘name_Y’ along with the other columns.
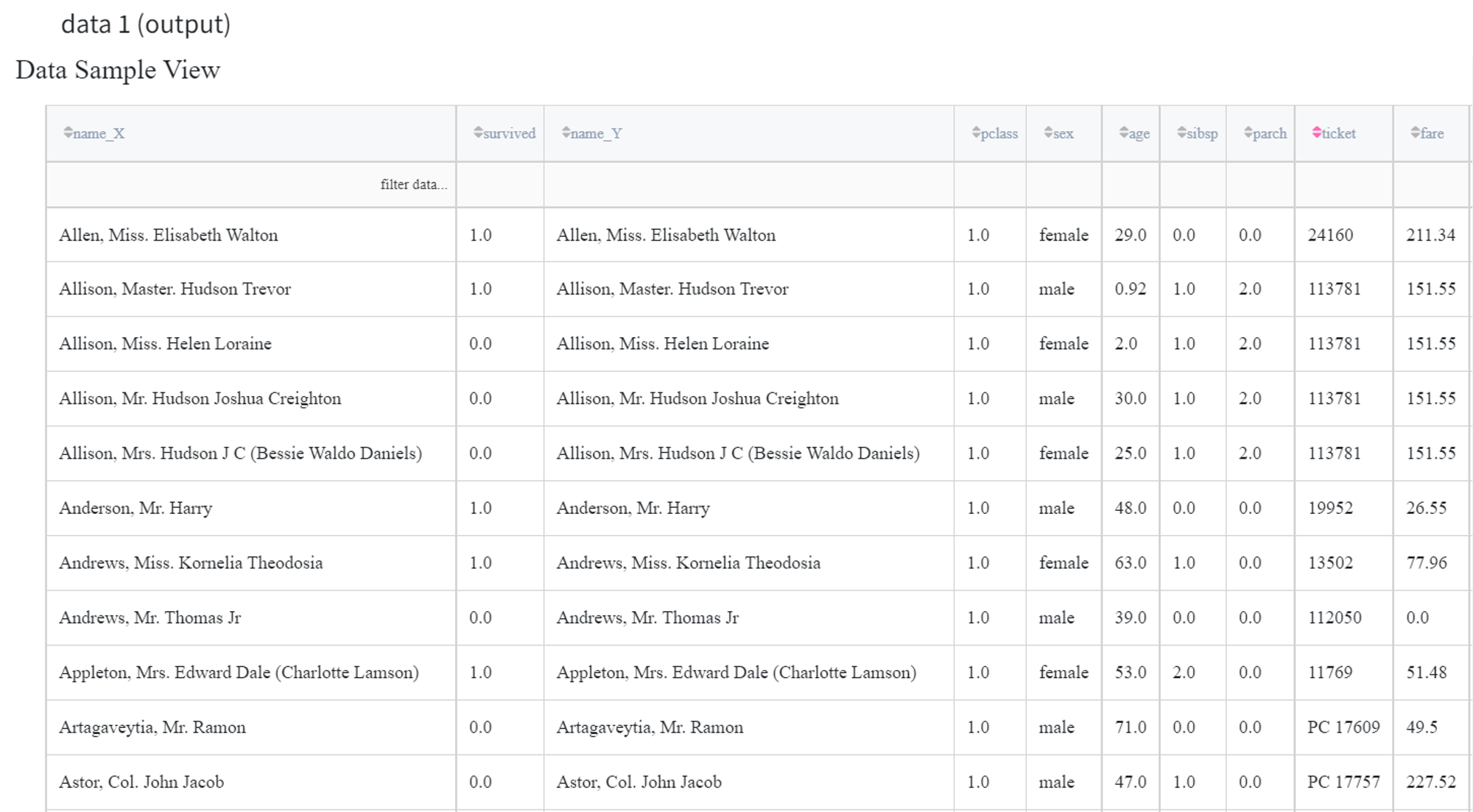
Instead, if the first input contains only one column ‘name’ and the second input contains all the columns except for the ‘name’, the Union Data Brick with horizontal concatenation will return the initial dataset, although with different columns order.
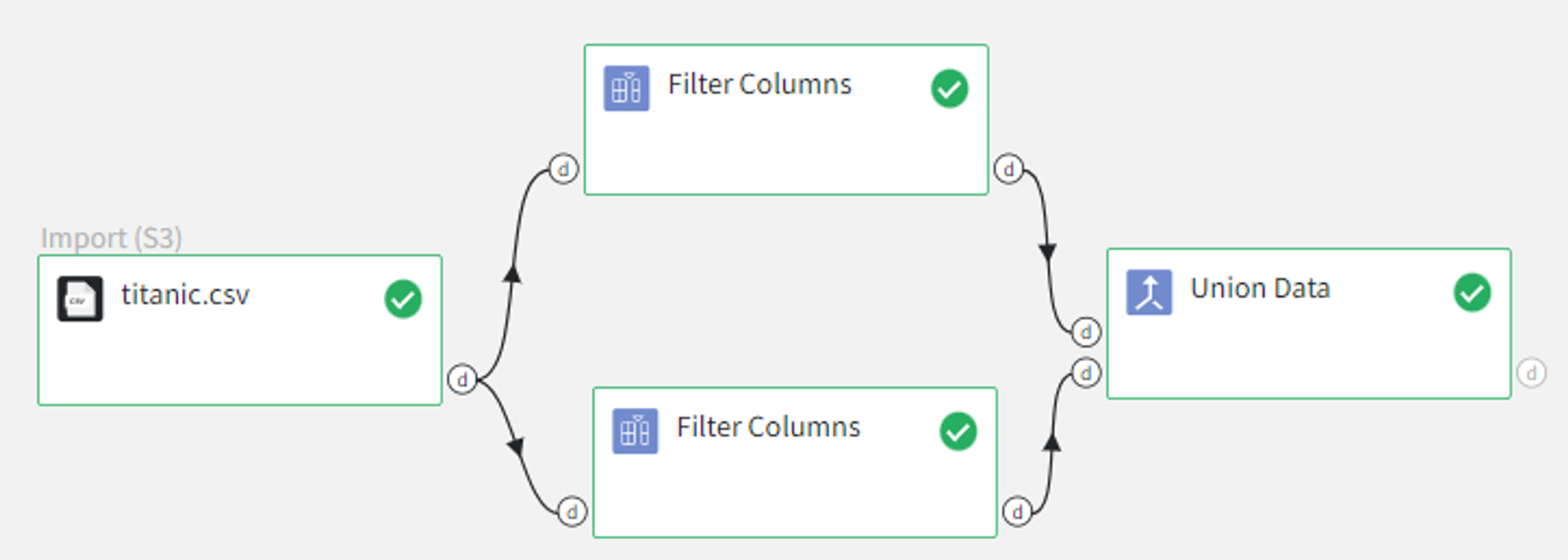
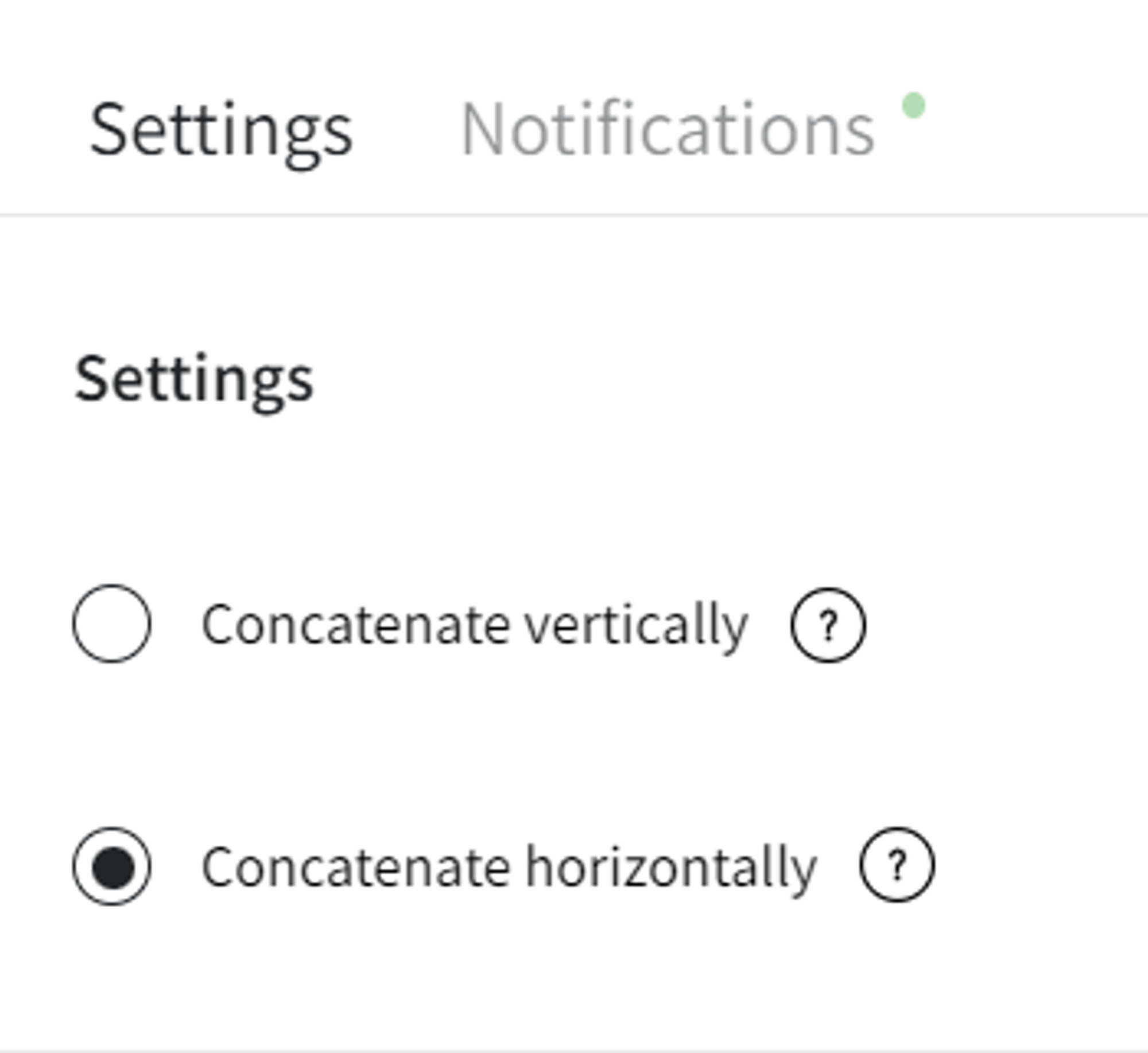
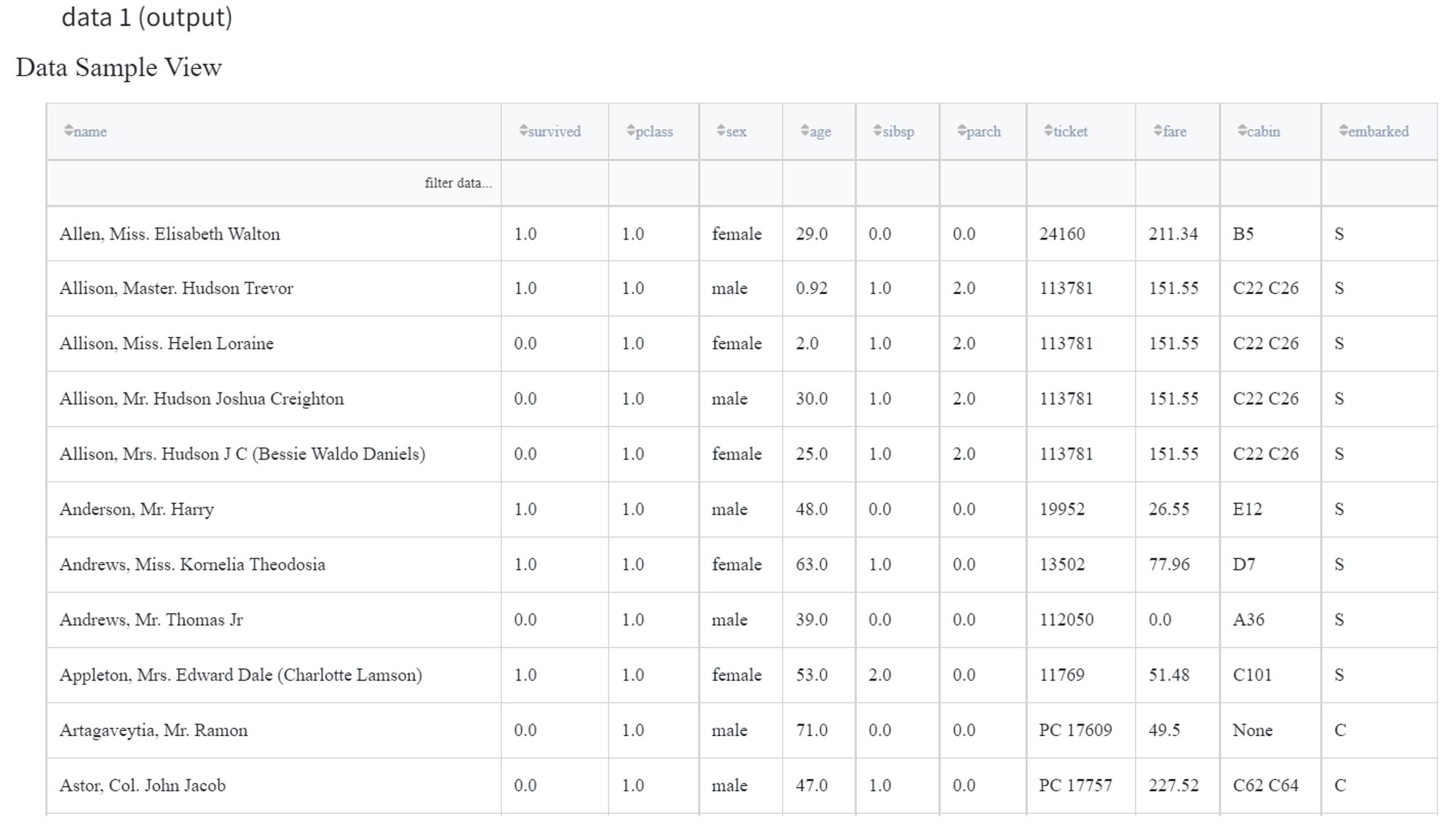
Recommendations
- Be mindful of the column names when doing horizontal union. If the column repeats twice, better remove it prior to the union.
- Be mindful of the order of the data, as the brick unites data as-is.