General Infomation
This brick provides a tool to handle missing values in your data.
It is pretty common for a data set to have missing values. This cases should be treated accordingly to not cause any issues or errors while training (e. g., some models do not support empty elements or will cause performance deterioration).
There are several ways to handle missing values: fill "cells" with function value or specify a constant one, delete rows with missing values or delete an entire column. It is highly advised to analyze your subject area (or to contact an expert if possible), as well as to get columns' information value.
There are some recommendations to consider while choosing the method to handle missing values:
- Be mindful when choosing a value or a function to fill the missing value. Always pay attention to the data types.
- Row deletion is suggested if you have a large dataset or if your subject area (e. g., medicine) allows that.
- Deleting columns is suggested if you have a large percentage of empty values and if your subject area does not forbid that. In addition, check the information value of this column to ensure that your model would not lose any useful features.
If you are not sure which method to choose, you can use brick's auto-suggestions (you will also get these suggestions when you first open the brick's settings) and then adjust them.
Description
Brick Location
Bricks → Analytics → Features Engineering → Missing Values Treatment
Bricks → Use Cases → Credit Scoring → Features Engineering → Missing Values Treatment
Bricks → Use Cases → Demand Forecasting → Data Processing → Missing Values Treatment
Brick Parameters
- Treatment
- Fill with custom value
- Fill with function
- Delete columns
- Delete rows
In this parameter you can specify one of the treatment types:
- Value
- Min
- Max
- Mean
- Median
- Mode
- Forward fill
- Backward fill
Enabled only if treatment type is either 'Fill with custom value' or 'Fill with function'.
If treatment is 'Fill with function' then you need to chose one of these functions:
With 'Fill with custom value' you would need to specify the value.
- Brick frozen
This parameter enables the frozen run for this brick. It means that all columns with the 'Fill with function' (min, max, mean, median, mode) treatment type will save their current calculated value for the next runs, which may be useful after pipeline deployment.
This option appears only after successful regular run.
Brick Inputs/Outputs
- Inputs
Brick takes the data set without any restrictions.
- Outputs
Brick produces the result as a new dataset. All missing values will be handled by the specified method. All changes are inplace and will not create new columns.
Example of usage
Let's consider the binary classification problem Binary classification : Titanic:
The inverse target variable takes two values - survived (0) - bad or event case / not-survived; (1) - good or non-event case. The general information about predictors is represented below:
- passengerid (category/int) - ID of passenger
- name (category/string) - Passenger's name
- pclass (category/int) - Ticket class
- sex (category/string) - Gender
- age (numeric) - Age in years
- sibsp (numeric) - Number of siblings / spouses aboard the Titanic
- parch (category/int) - Number of parents / children aboard the Titanic
- ticket (category/string) - Ticket number (contains letters)
- fare (numeric) - Passenger fare
- cabin (category/string) - Cabin number (contains letters)
- embarked (category/string) - Port of Embarkation
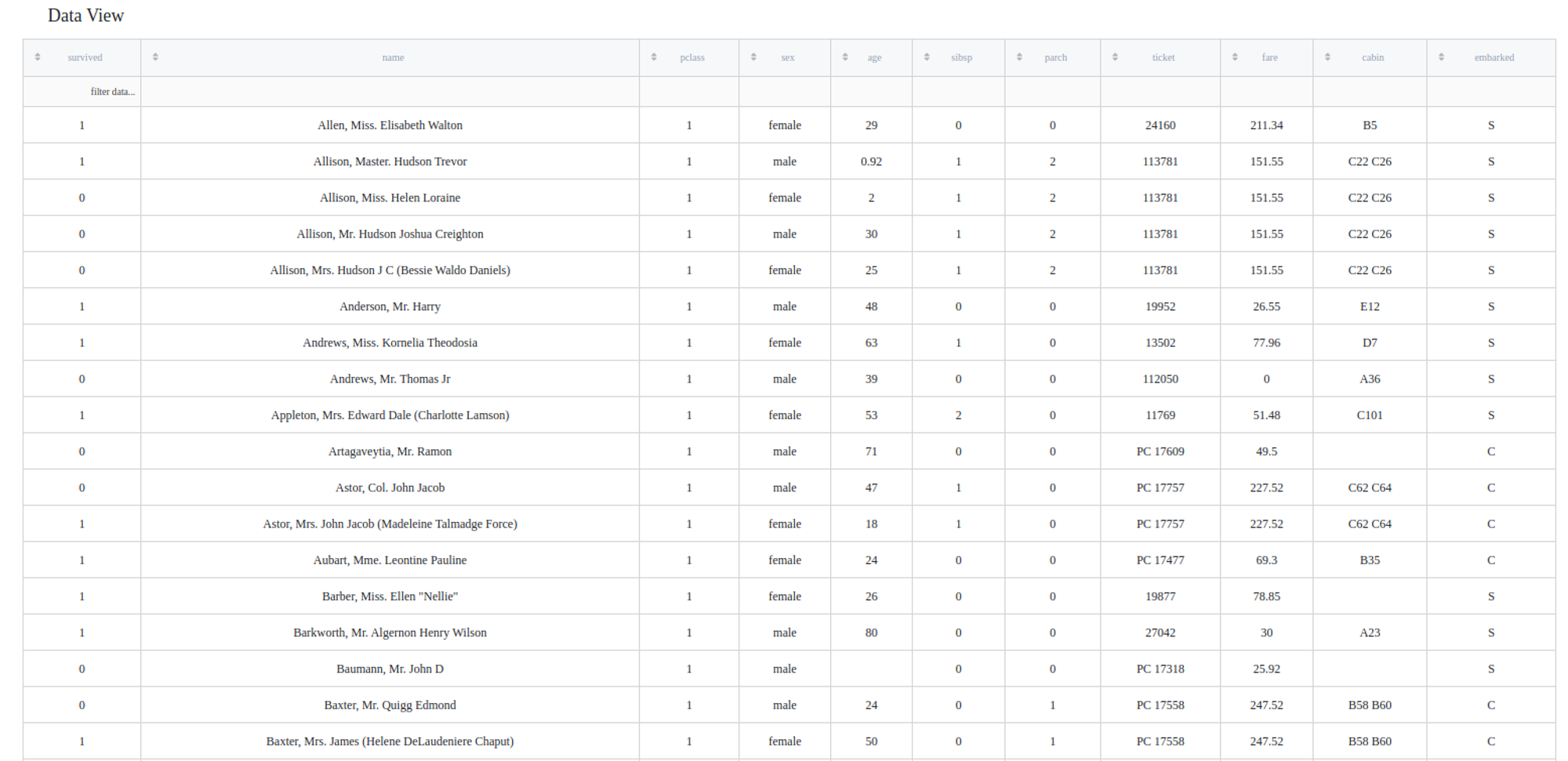
We can easily see some missing values in the 'cabin' column. The brick will automatically find and specify columns that have some missing values, as well as auto-suggested solutions, which you can modify later on.
Executing regular pipeline
Next steps would be made to build simple pipeline:
- First, drag'n'drop titanic.csv file from Storage→Samples folder and Missing Values Treatment brick from Bricks →Data Preprocessing
- Connect titanic data set to our "Missing Values Treatment" brick
- Execute pipeline, so brick can analize columns to find columns with missing values and suggest treatment methods
- Press "Handle missing values" button inside brick's settings
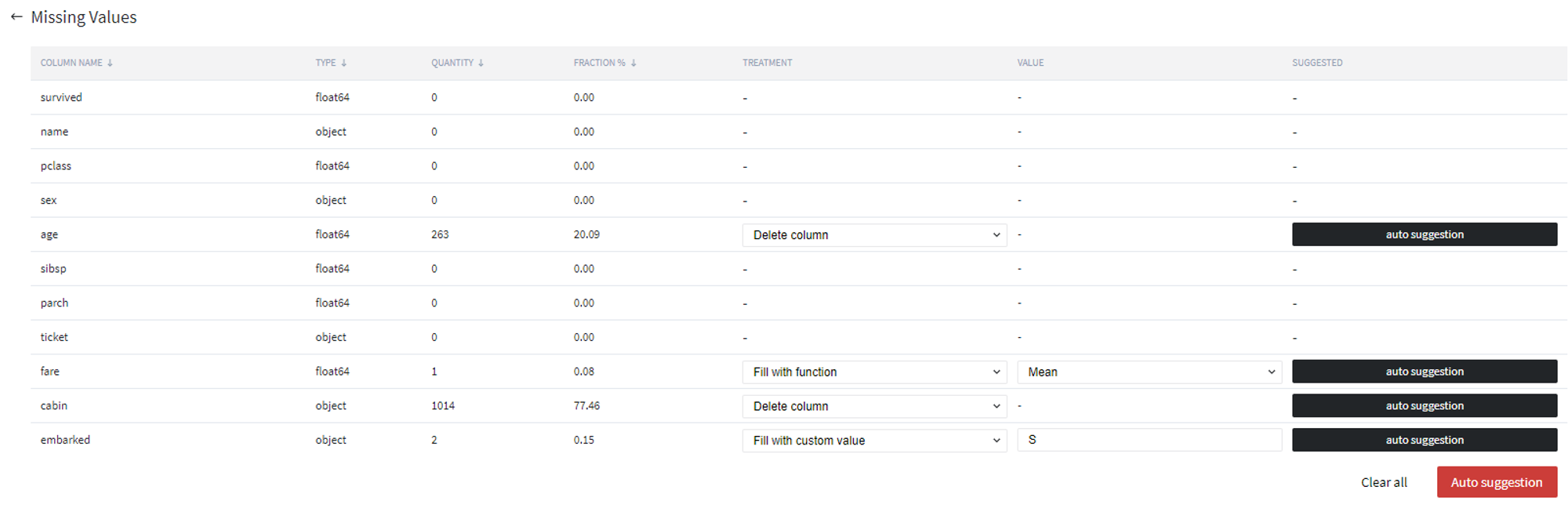
Inside we will see some statistics about quantity and fraction of missing values for each column, as well as dropdown menus to choose treatment types for the eligible columns (and inputs for 'value' if treatment type permits it).
In addition to that, we have several buttons to clear all inputs and get auto-suggestion (you can choose separately for each column or for all at once).
After you have configured all the settings, you just need to run the pipeline again!
In order to see the assessment result, you should open the Output data previewer on the right sidebar.

The results are depicted in the table:
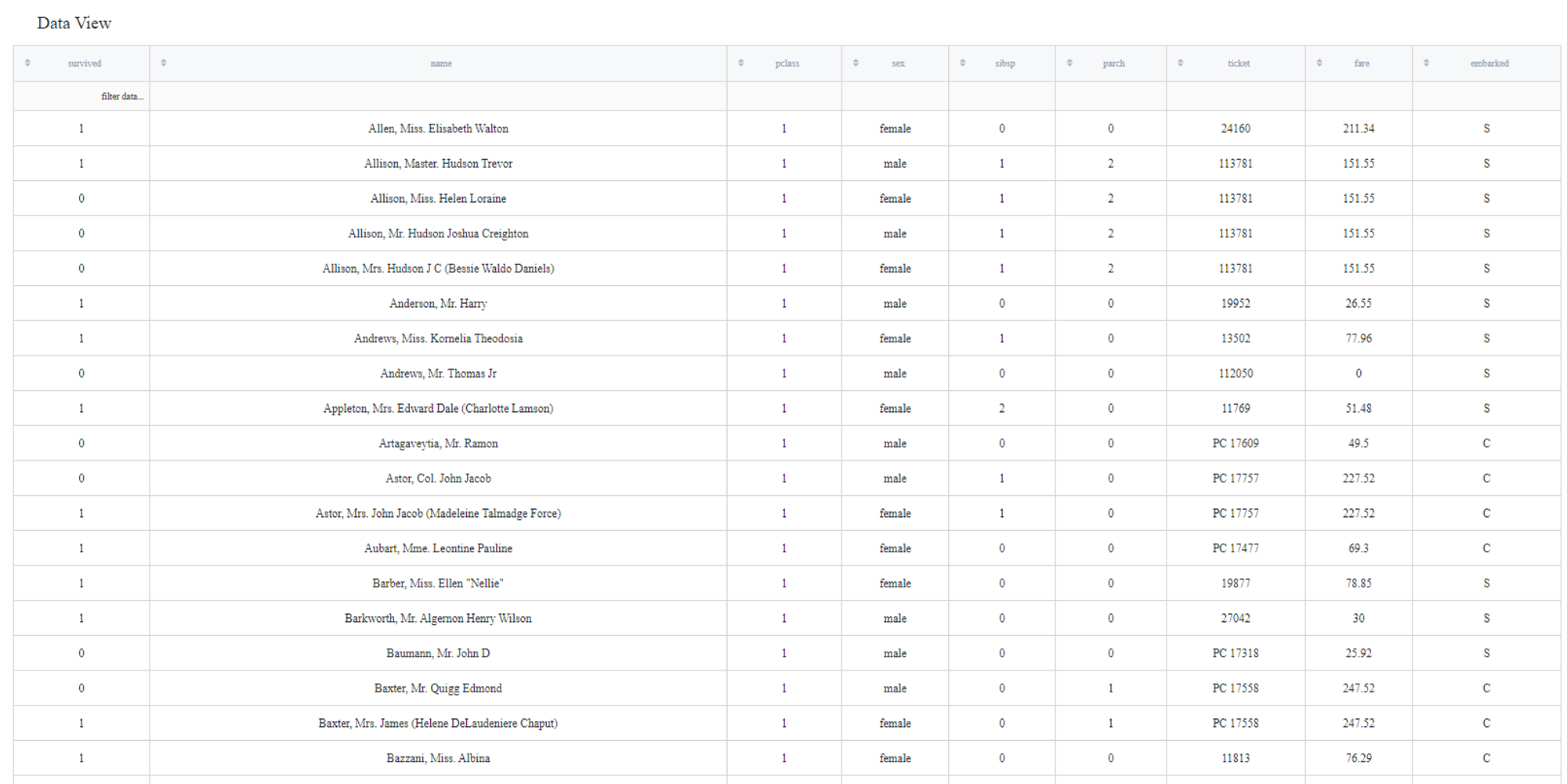
You can see that missing values are removed by the specified treatment type (for example, 'age' and 'cabin' columns are deleted)
Executing frozen pipeline run:
After completing the previous steps you need to check the 'Brick frozen' options in the 'General Settings' section:

This ensures that every time we execute our pipeline, the columns with the "Fill with function" treatment type would save their calculated value even if new data points will be given.