General information
Brick performs the selection of the independent variables that are characterized by sufficient predictive power with respect to the binary target variable. The predictive power of the variable is reflected via Information Value (IV) (please, see Information Value for the details):
Information Value explanation
Information Value
Variable Predictiveness
Extremely Weak predictive Power
Weak predictive Power
Moderate predictive Power
Strong predictive Power
Very Strong Predictive Power
Description
Brick Location
Bricks → Data Manipulation → Filter → Variable Selection
Bricks → Analytics → Features Engineering → Variable Selection
Bricks → Analytics → Data Insights → Variable Selection
Bricks → Use Cases → Credit Scoring → Features Engineering → Variable Selection
Brick Parameters
- Target
A binary variable that is used as a target variable in a binary classification problem. The information value of the separate predictors is calculated with respect to the specified target. The target variable should present in the input dataset and takes two values - (0, 1).
- Columns to exclude
List of columns that are going to be excluded from the analysis. These columns will be passed to the output dataset regardless of their predictive power. It is possible to choose several columns for filtering by clicking on the '+' button in the brick settings.
- Threshold
Minimal value of the Information Value score, which allows considering the variable (predictor) as a variable with sufficient predictive power, so that we may consider it as appropriate for further predictive modeling.
Brick Inputs/Outputs
- Inputs
Brick takes the dataset, which contains the binary target variable and independent predictors
- Outputs
- Columns that are considered as informative predictors
- Binary target variable
- Columns, which were excluded from the analysis
Brick produces the dataset, which contains:
Example of usage
Let's consider the binary classification problem Binary classification : Titanic. The inverse target variable takes two values - survived (0) - good or non-event case / not-survived (1) - bad or event case. The general information about predictors is represented below:
- passengerid (category) - ID of passenger
- name (category) - Passenger's name
- pclass (category) - Ticket class
- sex (category) - Gender
- age (numeric) - Age in years
- sibsp (numeric) - Number of siblings / spouses aboard the Titanic
- parch (category) - Number of parents / children aboard the Titanic
- ticket (category) - Ticket number
- fare (numeric) - Passenger fare
- cabin (category) - Cabin number
- embarked (category) - Port of Embarkation
As we know, the variables with good predictive power should be characterized by Information Value higher than 0.5. Information Value Brick may help us to make the preliminary assessment of the dataset (please, see Information Value for the details):
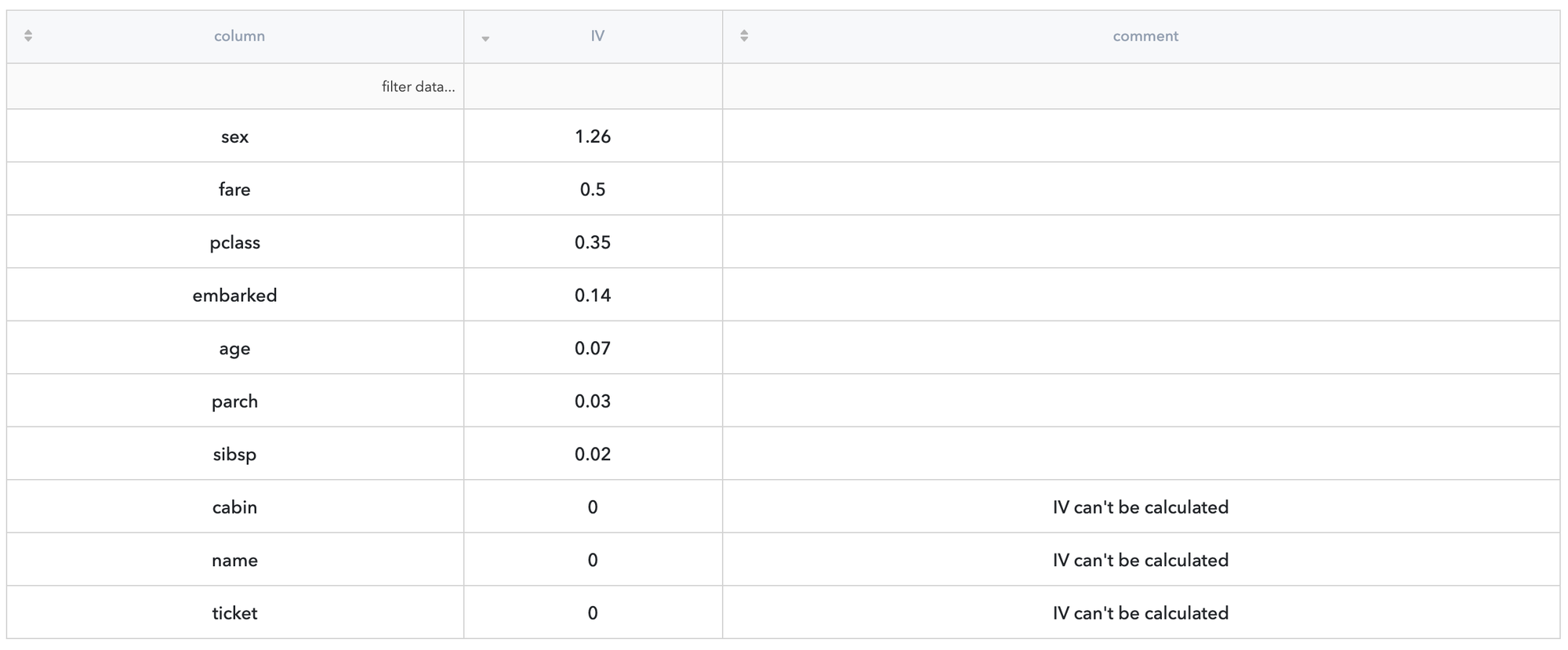
Now we may see that predictors sex, fare, pclass, and embarked can be considered as informative with IV threshold equals to 0.5.
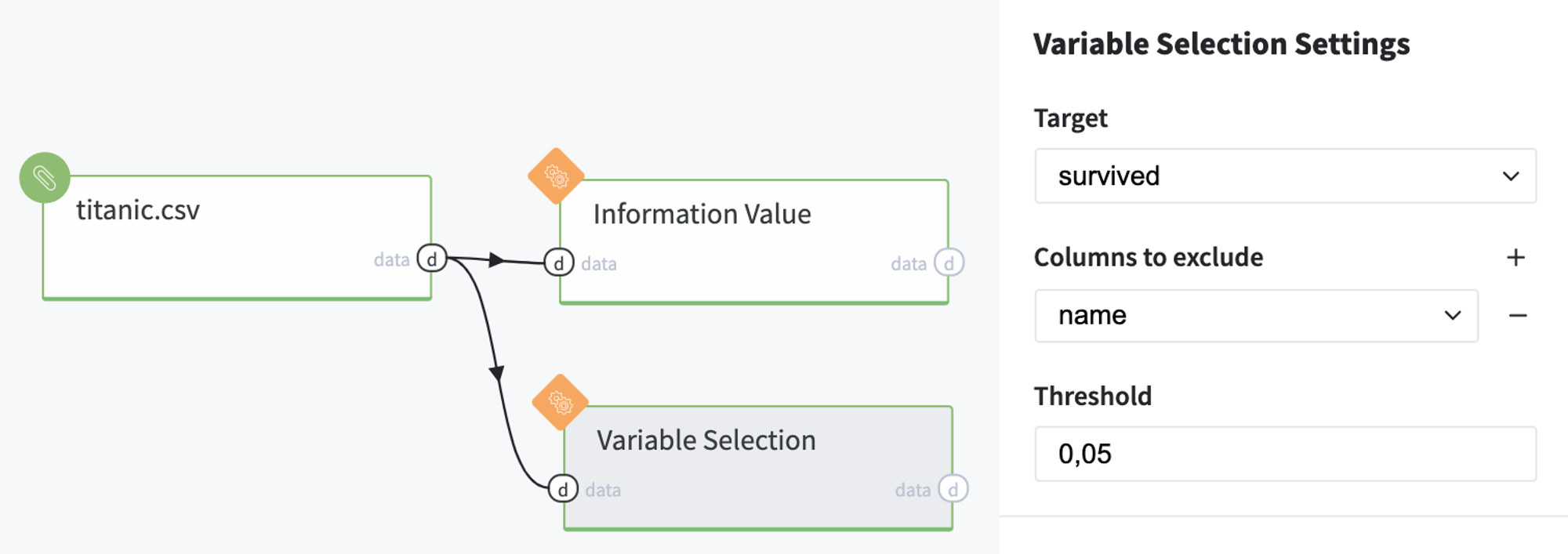
For instance, we would like to leave the informative variables only, but save the passengers' names in the output dataset as identifiers. For this purpose, we should put Variable Selection brick to the pipeline and configure it:
- pass the input data set to the Variable Selection brick
- define the target (survived column)
- add column name to the Columns to exclude list
- set Information Value Threshold equals to 0.05
- run pipeline
Assessment Information Values of the predictors
First of all, we may get a general assessment of the predictors in the context of their ability to predict the target variable. For this purpose we should:
- pass the input data set to the Information Value brick
- define the target (survived column)
- choose the "Information Value only" mode
- run pipeline
In order to see the assessment result, you should open the Output data previewer on the right sidebar.
The result is depicted in the table:
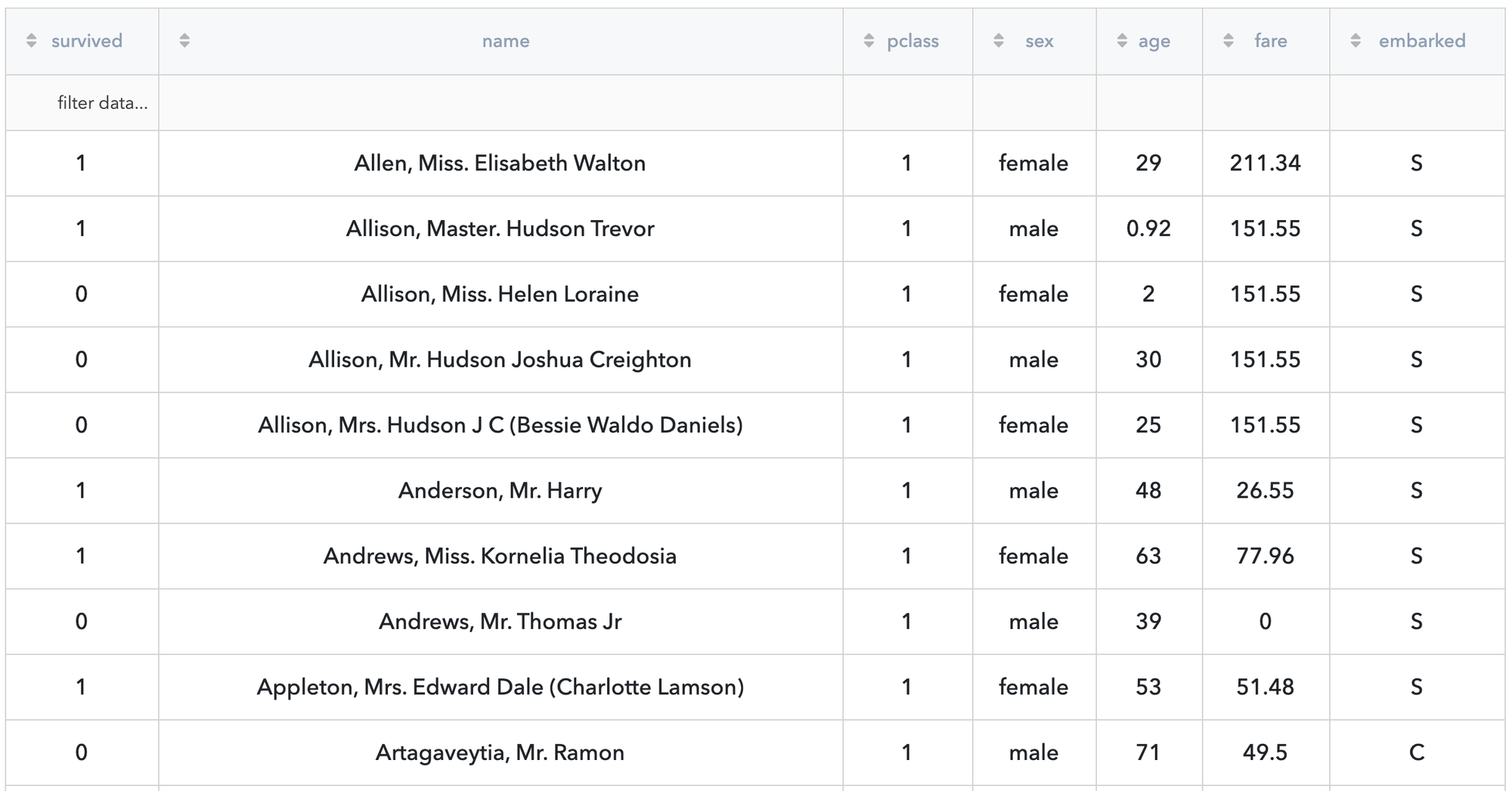
As we can see, the result dataset contains all informative variables (sex, fare, pclass, and embarked), saved column - name, and target variable - survived. The rest columns were excluded as non-informative ones.