General information
Performs data resampling to receive a more balanced dataset.
An unbalanced dataset is one in which the target variable has more observations in one specific class than the others.
The problem is that models trained on unbalanced datasets often have poor results when they have to generalize. If the algorithm receives significantly more examples from one class, it gets biased towards that particular class. The algorithm is then prone to overfitting the majority class. Just by predicting the majority class, models would score high on their loss functions.
Description
Brick Locations
Bricks → Machine Learning → Balanced Sampling
Brick Parameters
- Target
Column from the dataset with expected classes. Resampling is done with respect to it.
- Number of samples per class
Expected number of observations for each class in the resulting dataset.
Brick Inputs/Outputs
- Inputs
Brick takes the dataset
- Outputs
Brick produces the resampled dataset
Example of usage
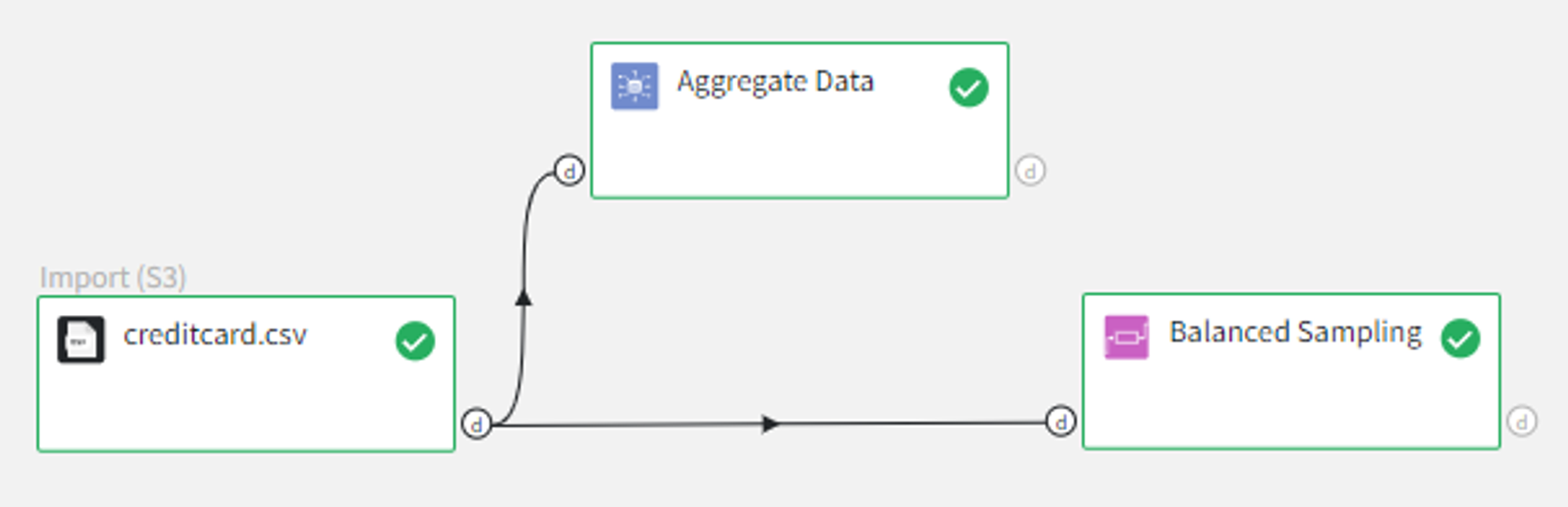
Let’s try to apply Balanced Sampling Brick to the dataset for Credit Card Fraud Detection.
To get the target variable quantities we can use Aggregate Data Brick with the following settings:
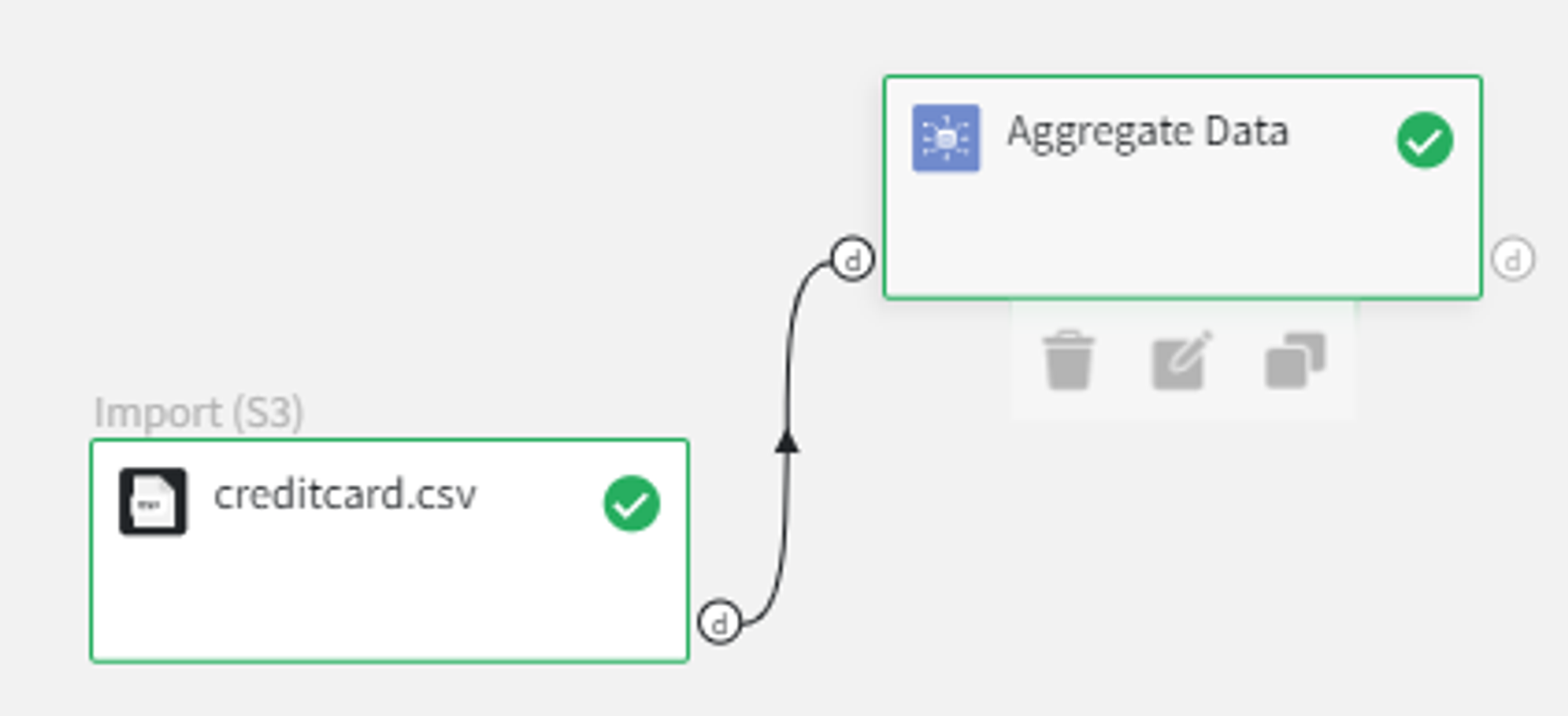
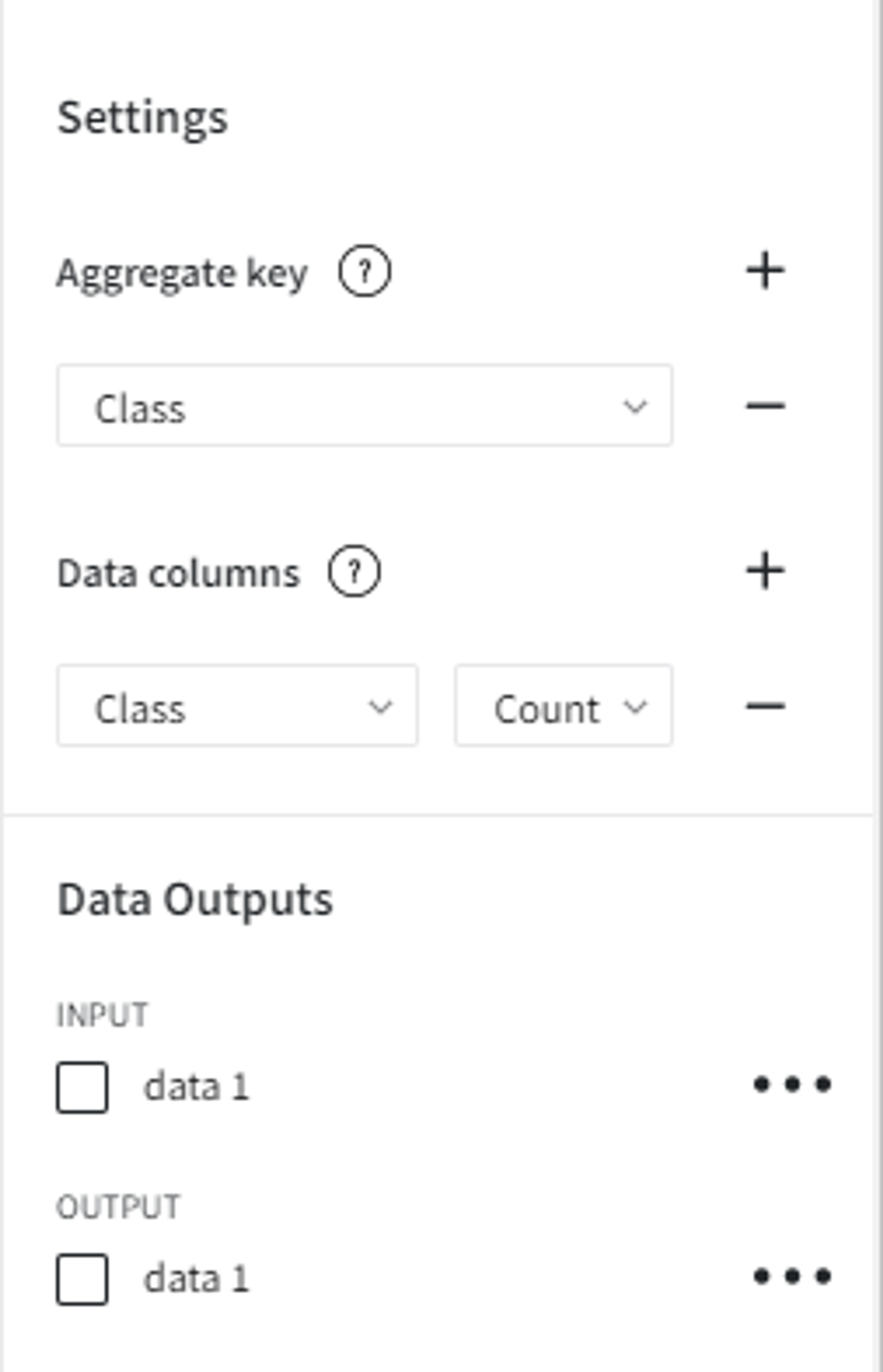
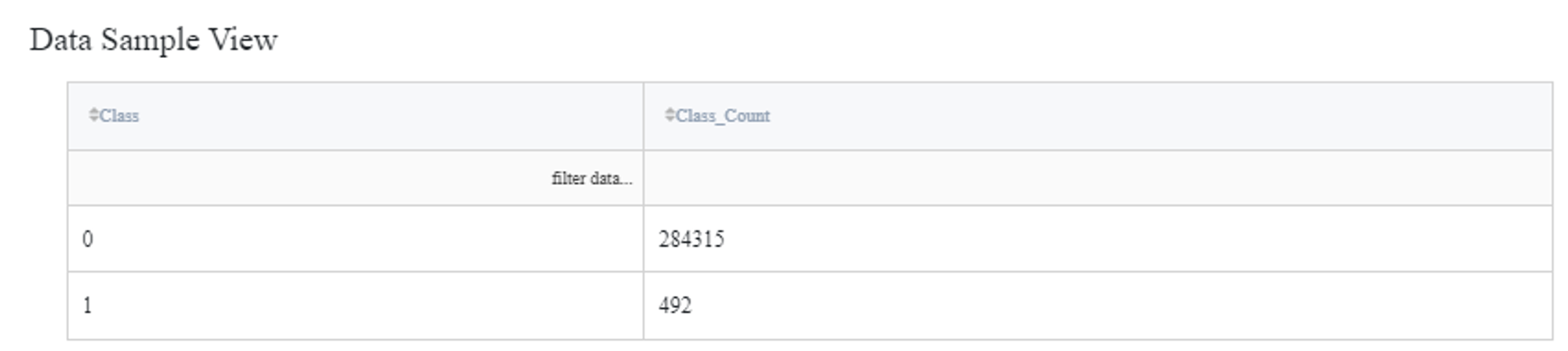
From the results, it’s obvious that there is a significant imbalance towards the ‘0’ class, which is reasonable since frauds happen far less frequently than normal transactions.
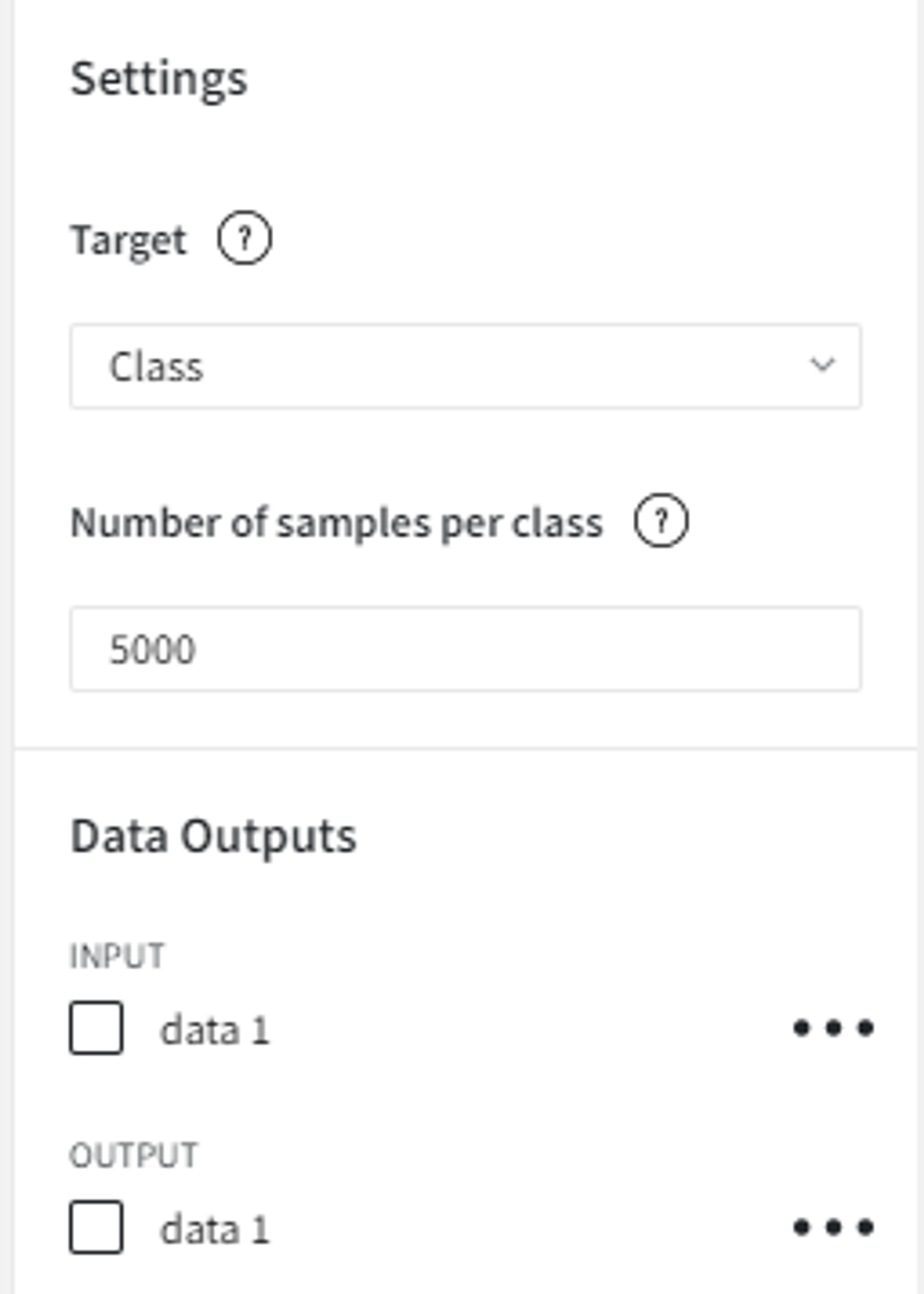
We can use Balanced Sampling Brick to resample the dataset with respect to the ‘Class’ column and set the ‘Number of observations per class’ equal to 5000.
As a result, we get the dataset of size 10 000, created by performing random sampling with replacement. It means that some of the records might be duplicated once or more times.
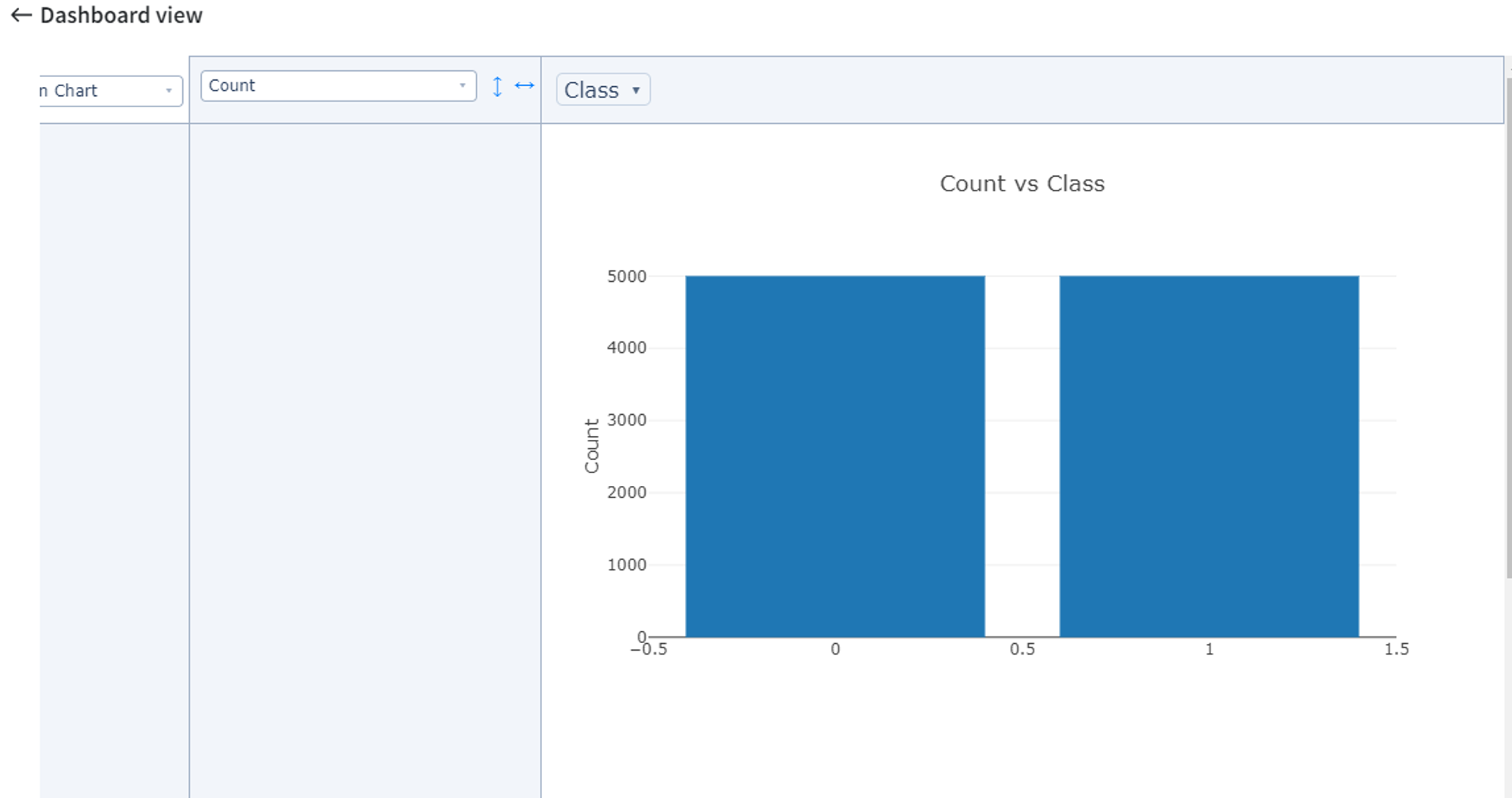
If we visualize the distribution of the ‘Class’ variable counts (Pivot Table Brick), we get the next dashboard:
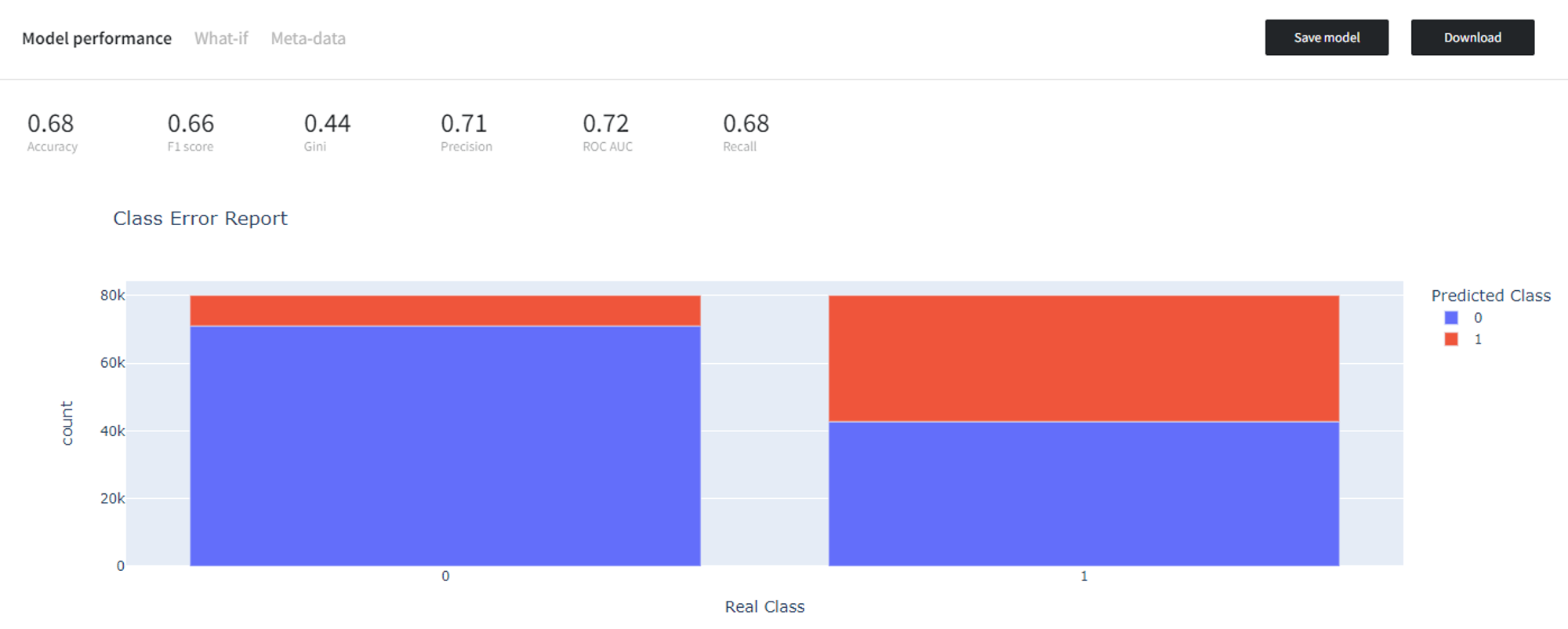
If we trained a binary classification model (Logistic Regression in this example) on the initial highly imbalanced dataset, it would predict every observation as the majority class ‘0’ and get perfect scores on the training data, but fail to perform well on the test data.
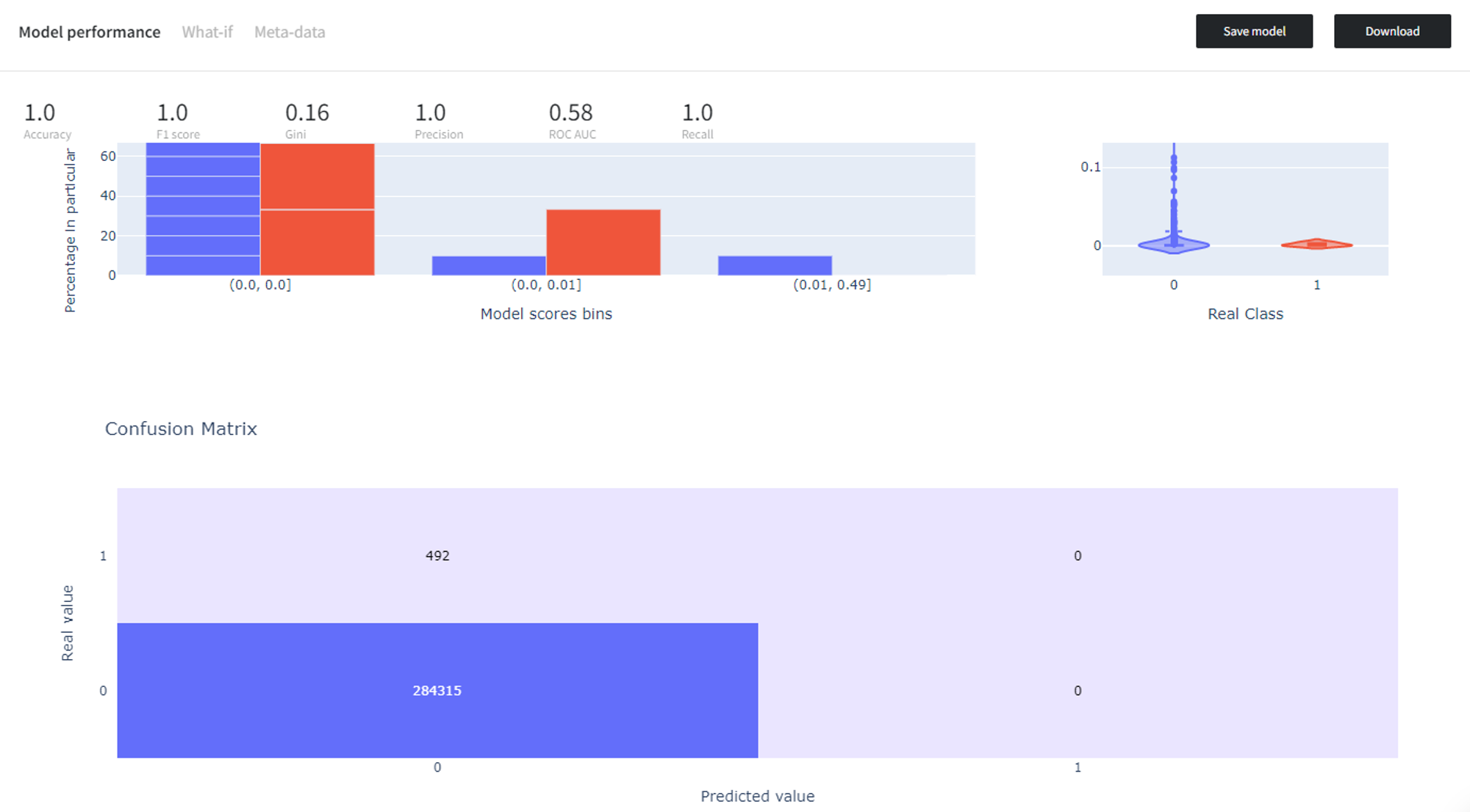
However, if we balance the dataset before training the model, the model performs much better at distinguishing the rare class ‘1’, and, consequently, is better at generalization.